PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
随着视频生成和3D生成从娱乐端走向专业化的内容生产端,影像行业对AI的可控性要求仍在持续提升,保持人物一致性,复现复杂镜头语言、实现画面精准控制和局部空间编辑等能力,也逐渐成为AI创作的底层支撑,然而视角旋转、物体移动、镜头推拉、空间补全等大量编辑任务仍然依赖Prompt 控制或多阶段Pipeline,稳定性与可控性都存在明显局限。
另一方面,尽管当前生成模型拥有强大的图像生成能力,但当单帧生成结果进入连续视角或动态运动时往往难以维持稳定的“空间一致性”,例如出现镜头运动不流畅、空间透视关系错乱、多视角内容不连续等问题。对此,让生成模型具备更强的“空间理解能力”,成为AI视觉领域的重要研究方向,“Novel View Synthesis(新视角生成)”也因而受到了越来越多的关注。
近期,美图影像研究院(MT Lab)联合University of Texas at Austin(德克萨斯大学)提出了一种基于扩散Transformer(DiT)的3D位置编码框架——Positional Encoding Field(PE-Field),将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。该成果已被国际顶级人工智能会议ICLR 2026收录。

论文链接:[2510.20385] Positional Encoding Field
开源代码和模型:GitHub - MTLab/PE-Field · GitHub
01
DiT 里的Patch Token,其实比想象中“独立”
在Diffusion Transformer(DiTs)中,图像通常会被划分为带有位置编码(Positional Encodings, PEs)的Patch Token,从而将Transformer的序列建模能力扩展至视觉空间,但现有DiT主要在2D平面上处理位置编码,更多承担“位置标记”作用,对于空间结构、几何关系、视角变化等更复杂的建模能力则相对有限。
当研究团队在分析DiT视觉内容组织机制时,观察到一个有趣的现象,即Patch Token在一定程度上表现出独立性。实验发现,即使对位置编码进行扰动,模型仍能够生成语义连贯的图像,但其空间结构会随位置编码的变化而重新组织。这一现象表明,生成图像的空间连贯性,在很大程度上受到位置编码的引导。

图片1: DiT 图像块级独立性

图片2: 直接新视角合成(NVS) 结果
02
PE-Field:将2D位置编码,扩展至3D场
受到上述观察的启发,研究团队设计了Positional Encoding Field(PE-Field)框架,通过引入深度感知与层次化控制,将原本局限于2D的位置编码扩展为结构化的3D场(Structured 3D field),为扩散Transformer(DiT)的3D感知与空间控制提供了一种全新的位置编码思路,同时提升了模型理解3D几何的能力。PE-Field主要包含两个核心模块:
▎深度感知编码(Depth-aware Encodings)
DiT的位置编码一般只有X(横向)和Y(纵向),PE-Field为模型引入了Z轴方向的深度信息,使得DiT具备了体积推理(Volumetric Reasoning)的潜力,有助于模型感知场景的三维深度结构。
▎层次化编码(Hierarchical Encodings)
一般情况下,DiT中一个Token对应一个Patch,但为了实现更为细致的控制,PE-Field采用了层次化的编码策略,允许DiT在更精细的层面对几何结构进行建模。
基于对上述两个核心模块的创新设计,PE-Field使得DiT能够在较少改动核心网络架构的情况下,更自然地进行3D几何特征的学习与建模。
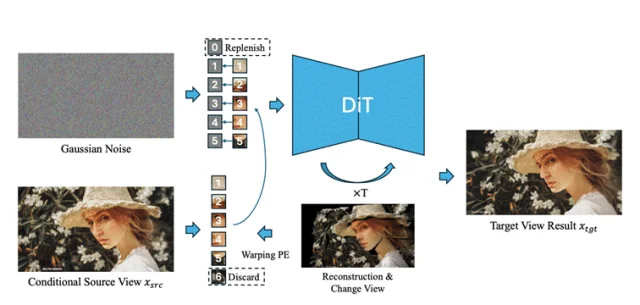
图片3: 整体框架
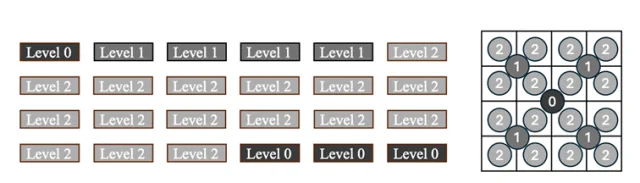
图片4: 层次化位置编码
实验结果表明,引入PE-Field的DiT模型在单张图像的新视角合成(Novel View Synthesis)任务中展现出了具有竞争力的性能,它可以通过调整位置编码,生成质量较高的多视角结果;与此同时,PE-Field在泛化能力上也表现出了潜力,在特定物体的3D编辑、物体移除等可控的空间图像编辑(Spatial Image Editing)任务中展现了较好的灵活性和适用性。

图片5: 新视角合成结果可视化

图片6: 与基于提示词的图像编辑方法的比较

图片7: 其他应用场景 - 物体位置编辑与物体消除
03
面向真实创作场景:
从前沿研究到产品落地
生成式AI正在逐步融入专业化的内容创作场景,尤其在视频生成、3D重建等领域,对模型的空间关系建模能力提出了更高要求。针对这一挑战,美图所提出的PE-Field,基于对位置编码与空间结构关系的探索,为Diffusion Transformer(DiT)的3D感知与空间控制提供了新的研究思路,而对于用户场景而言,前沿研究的意义在于让模型的能力边界能够加速满足真实创作需求。
近年来,美图影像研究院(MT Lab)围绕生成式AI与影像Agent方向的技术能力布局,将人像美容与创意玩法、视频处理与美化、专业创作辅助等AI能力广泛落地在美图秀秀、美颜相机、Wink、RoboNeo、开拍等美图旗下AI影像产品中,通过聚焦在”技术能力的产品化“,让生成式AI真正进入高频创作流程。未来,依托从前沿影像技术研发到实际应用的商业化模式闭环,美图有望进一步推动智能创作在专业场景与大众场景的落地,持续为用户带来兼具创作自由度与个性化视觉表达的产品体验。
文章来自于"AI科技评论",作者 "美图影像研究院(MT Lab)"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

