更聪明的计算远比更多的计算更有效。
这正是蚂蚁集团CodeFuse团队,用一篇ACL 2026主会论文验证的核心结论。
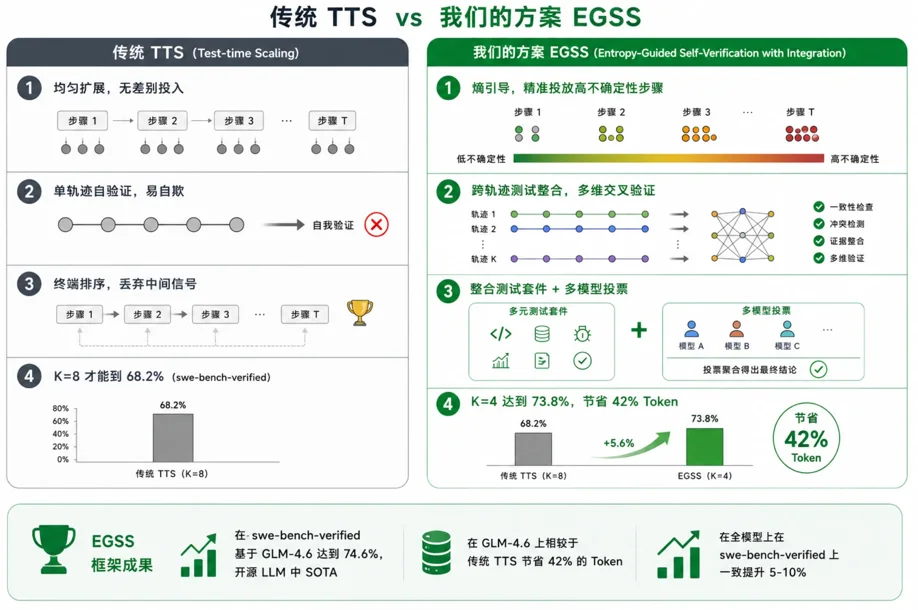
Test-Time Scaling(TTS)是通过在推理阶段投入更多计算资源,让Agent多次尝试、探索不同推理路径再选最优的关键范式,是当前LLM在复杂任务上取得SOTA的核心方法。
然而业界主流TTS方法对所有推理步骤一视同仁地投入计算,大量Token浪费在确定性操作上,且多轨迹选择仅靠“谁得票多”,Agent自我验证通过率88%中却有35.7%是错的——
投入翻倍,收益边际递减。
针对这一现状,蚂蚁集团CodeFuse团队提出EGSS:
通过“工具熵”指标精准识别高不确定性决策点、只在关键步骤展开多候选探索,并首创跨轨迹测试整合机制用客观执行结果替代主观评分,两阶段闭环精准解决计算冗余与选择脆弱两大痛点。

EGSS在SWE-Bench-Verified上全模型一致提升5-10%,GLM-4.6+EGSS达到74.6%创下开源方法新纪录,更以K=4打败K=8节省38-42%Token。
这有力说明了,更聪明的计算远比更多的计算更有效。
TTS的性能危机:越强大,越昂贵
Test-Time Scaling(TTS)是当前LLM在复杂软件工程任务上取得SOTA的关键范式——
通过在推理阶段投入更多计算资源来探索多样化的推理路径,从而提升代码生成和Bug修复的效果。
但现实很骨感:TTS正在用惊人的资源消耗换取边际递增的收益。
痛点一:计算冗余与低效探索
现有方法普遍采用均匀搜索扩展或大规模重复采样,没有任何轨迹间的协调机制。
大量计算被浪费在确定性操作上(比如读取文件、简单编辑),而真正需要深入探索的高不确定性决策点却得不到足够的计算资源。
痛点二:补丁选择机制脆弱
多轨迹TTS的最终选择环节常常丢弃中间调试信号,仅依赖终端排序。
这导致“共识错误”,即多条轨迹收敛到一个看似合理但实际错误的补丁上。
实证显示:88%的轨迹包含自我验证,但其中35.7%仍产出错误补丁——“自我欺骗性调试”。
下图为各种TTS方法在性能与Token使用量上的权衡,EGSS位于Pareto前沿。
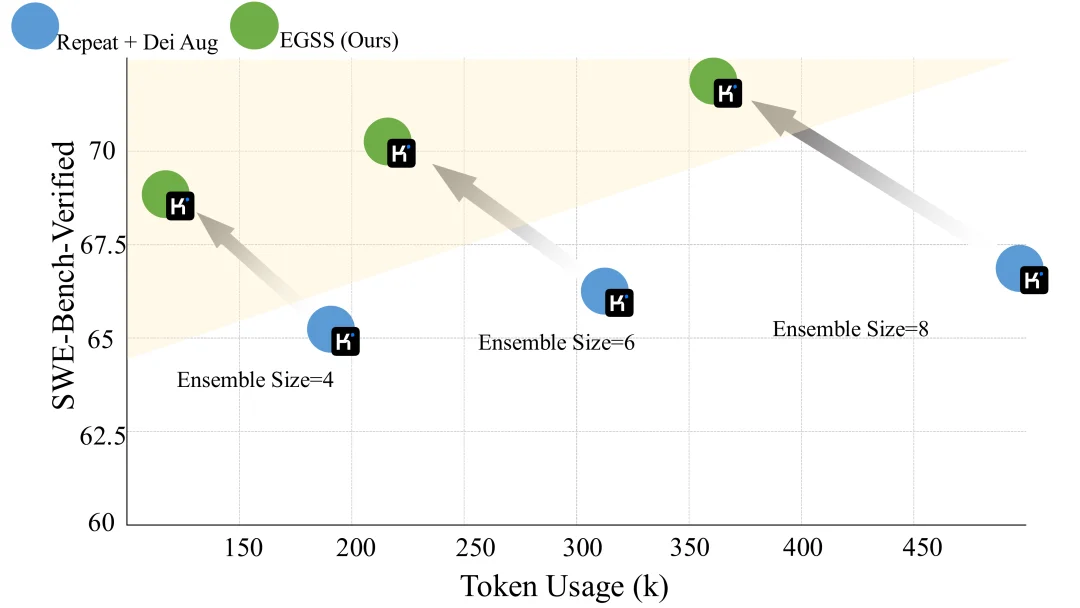
从图中可以清晰看到:
EGSS在“性能-成本”Pareto前沿上占据绝对优势,用更少的Token实现了更高的Resolved%。
两个关键发现:问题出在哪?
发现一:不是所有步骤都需要“用力”
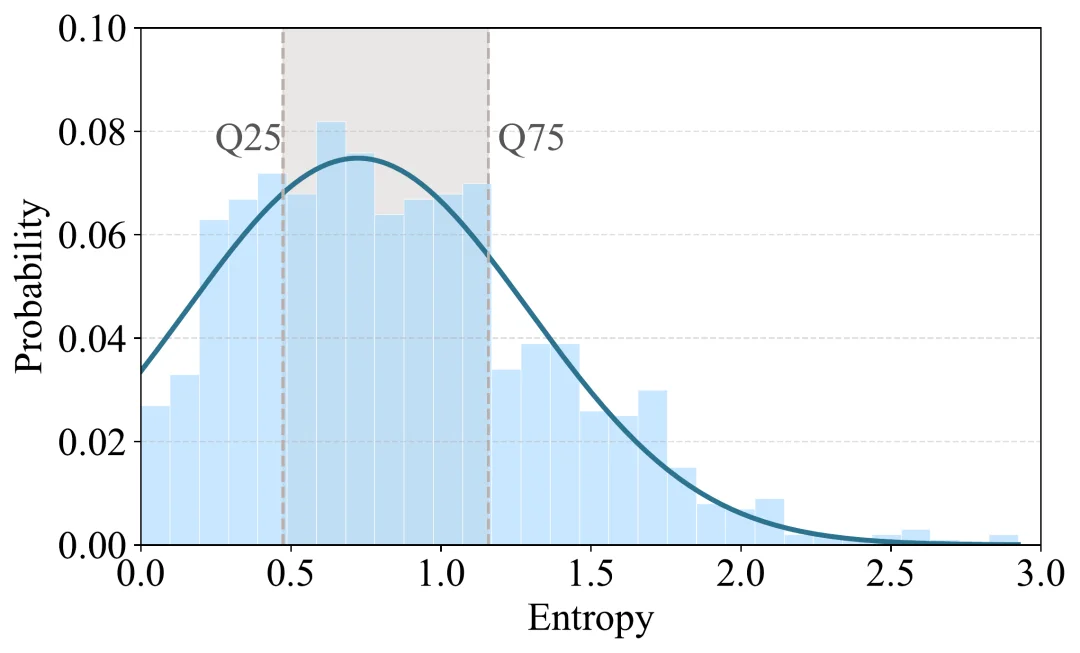
Tool Entropy分析发现,Agent轨迹中大部分的动作都在执行固定化的操作,表现为观测指标为:
大量步骤是低熵确定性操作(如读文件),仅少数高熵步骤才是关键分支点。
均匀分配计算是严重浪费,应将资源集中于不确定步骤。
下图表明,Agent轨迹中的工具熵分布呈明显右偏态,大部分步骤为低熵操作。
发现二:自我验证≠正确验证
88%的轨迹包含自我验证,但其中35.7%仍产出错误补丁。
单一视角验证会陷入“确认偏差”——
Agent自以为验证通过,实则接受了无效补丁。需要跨轨迹的多维度交叉验证。
EGSS框架:精准打击,闭环验证
EGSS框架整体架构为,熵引导的两阶段闭环。
其核心思想是:用结构化的架构复杂性替代暴力的均匀扩展。
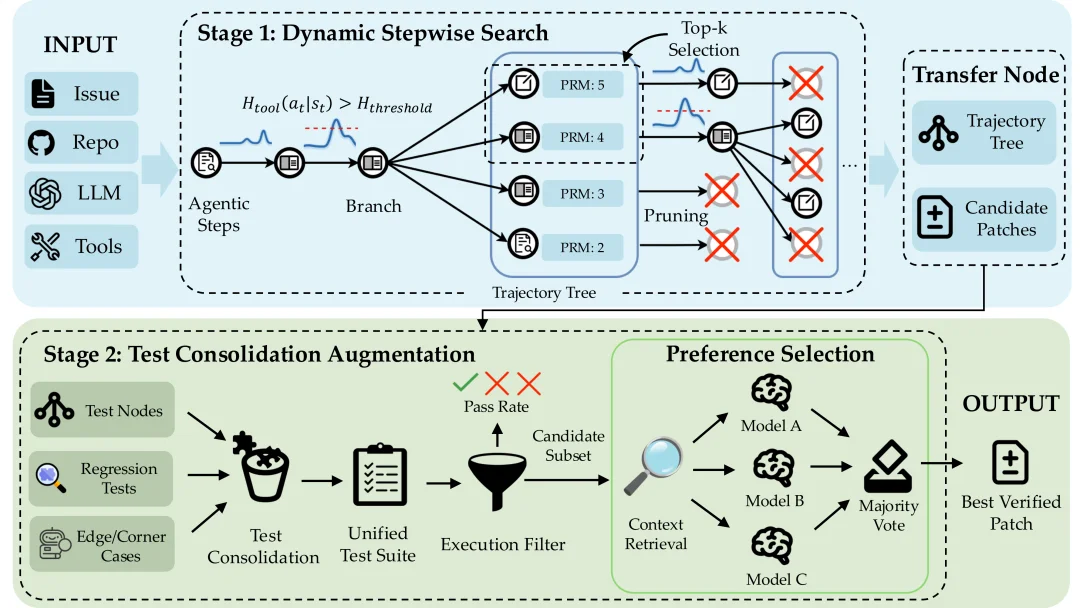
两个阶段分别精准解决两大痛点。
阶段一:动态逐步搜索(DSS)——解决“计算冗余”
鉴于现有TTS对所有步骤一视同仁地投入计算,导致大量Token浪费在确定性操作上,而关键决策点反而探索不足。
所以EGSS决定利用工具熵识别高不确定性步骤,只在这些“关键岔路口”投入额外计算。
具体怎么做?
1、实时监控工具熵:每一步监控Htool(at | st),当熵值超过阈值(q75 ≈ 1.16)时,判定为高不确定性决策点。
2、在高熵步骤展开多候选:对高熵步骤进行stepwise rollout(默认4个候选动作),而非在所有步骤都扩展。
3、引入Judge评估与剪枝:经过微调的Qwen3-8B Judge对每个候选动作打分,结合模型似然和Judge评分排序,保留Top-K高质量轨迹。

长度惩罚,避免偏向短轨迹。
关键设计哲学在于,只在~25%的高熵步骤调用Judge,其余~75%的确定性步骤直接通过。
这意味着DSS将计算资源精准投放到“最需要思考”的步骤,而非无差别地撒网。
最终,DSS在相同K值下Oracle指标全面优于Repeat Sampling(如GLM-4.6 K=4:77.4%vs73.4%),说明熵引导的搜索确实产生了更多高质量候选。
阶段二:测试整合增强(TCA)——解决“补丁选择脆弱”
鉴于多轨迹TTS的最终选择环节丢弃了中间调试信号,仅靠终端排序容易受“共识错误”影响,且单轨迹自我验证存在35.7%的“自我欺骗”率,无法可靠区分正确与错误补丁。
所以EGSS选择将多条轨迹中的异构调试信号整合为统一的可执行测试套件,用客观的测试结果而非主观评分来筛选补丁。
四步流水线:
Step 1:调试动作提取
从DSS生成的轨迹树中收集所有调用调试工具(如测试生成、测试执行)的节点,形成调试信号集合A_debug。
这些信号来自不同轨迹的不同视角,天然具有多样性。
Step 2:整合测试套件生成
TestConsolidationAgent分析A_debug中的异构调试意图,结合代码仓库上下文,合成为统一的可执行测试文件。
覆盖各条轨迹发现的边界情况、不同回归测试视角、单条轨迹遗漏的测试维度。
Step 3:补丁评估与过滤
TestEvaluationAgent(仅配备Bash工具,确保安全隔离)在每个候选补丁上执行整合测试套件,计算通过率,保留通过率超过阈值τ的补丁。
用客观测试结果替代主观LLM评分——补丁好不好,跑测试说了算。
Step 4:偏好选择投票
多个独立的PreferenceSelector(Kimi-K2、GLM-4.6、Qwen3-Coder-480B)各自读取代码、应用补丁、执行验证后投票。整合测试已过滤大部分错误,投票进一步降低单模型偏差。
两阶段的闭环协同:
DSS通过熵引导搜索产生高质量、高多样性的候选集(“种好草”);TCA通过跨轨迹测试整合和多模型投票从中可靠地选出最优补丁(“挑好苗”)。
没有DSS的多样候选,TCA无从选择;没有TCA的可靠筛选,DSS的好候选也可能被错误淘汰。
实验结果:以少胜多,全面领先
主实验:SWE-Bench上的全面突破
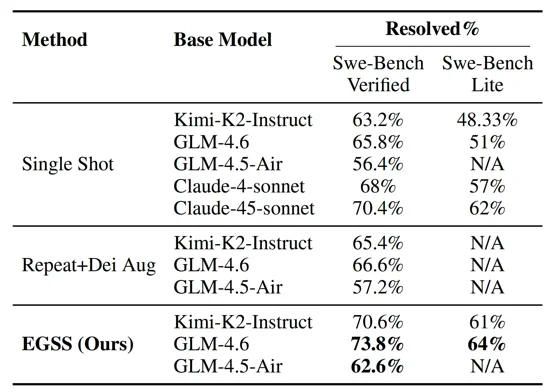
关键发现为,EGSS在K=4时就超越了所有基线方法,GLM-4.6达到73.8%,创下开源LLM新SOTA。
Token效率:K=4打败K=8
下图为不同采样策略下的平均Token使用量对比:
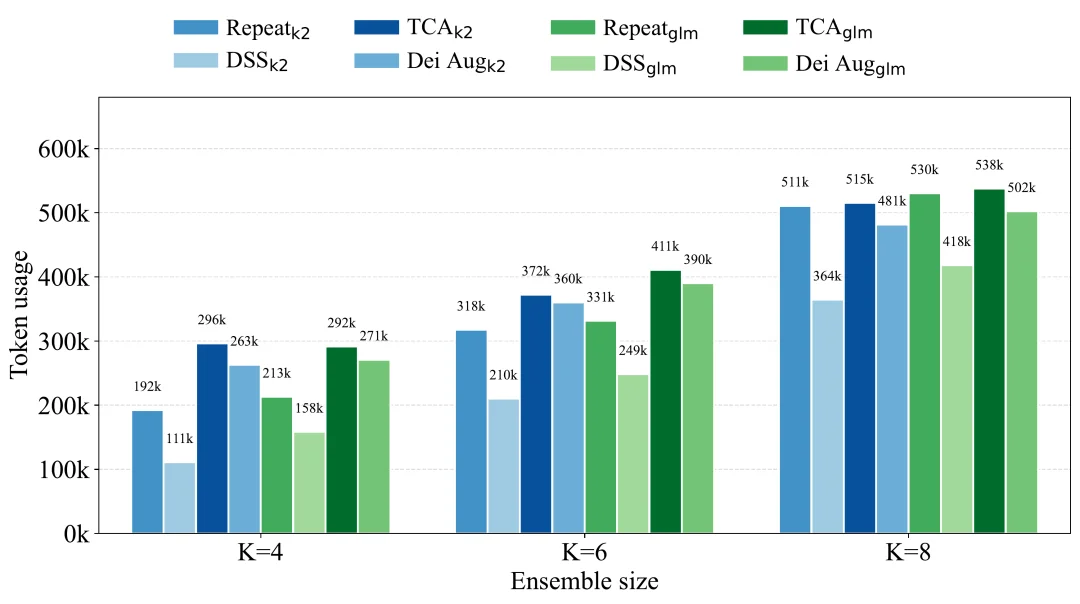
完整Token消耗对比
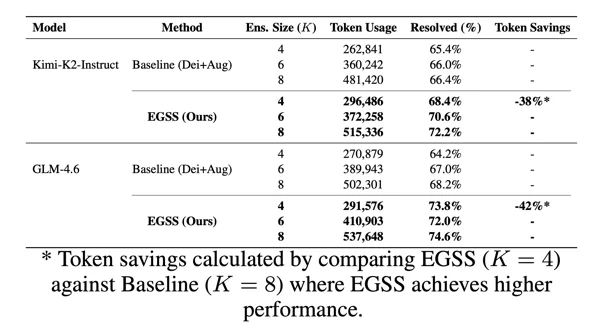
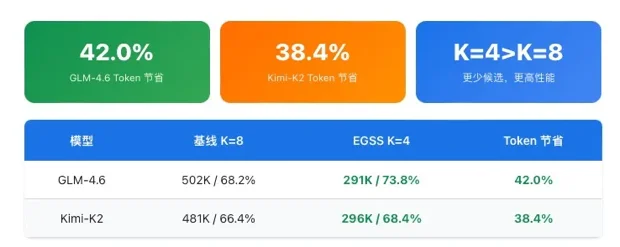
EGSS用一半的候选数量(K=4 vs K=8),不仅节省了38-42%的Token,还实现了更高的准确率。
虽然TCA本身引入了3%-13%的额外Token开销,但DSS产生的高质量候选使得更小的K值即可超越基线K=8的效果——这是“以小博大”的典型范式。
补丁选择:TCA的稳定优势
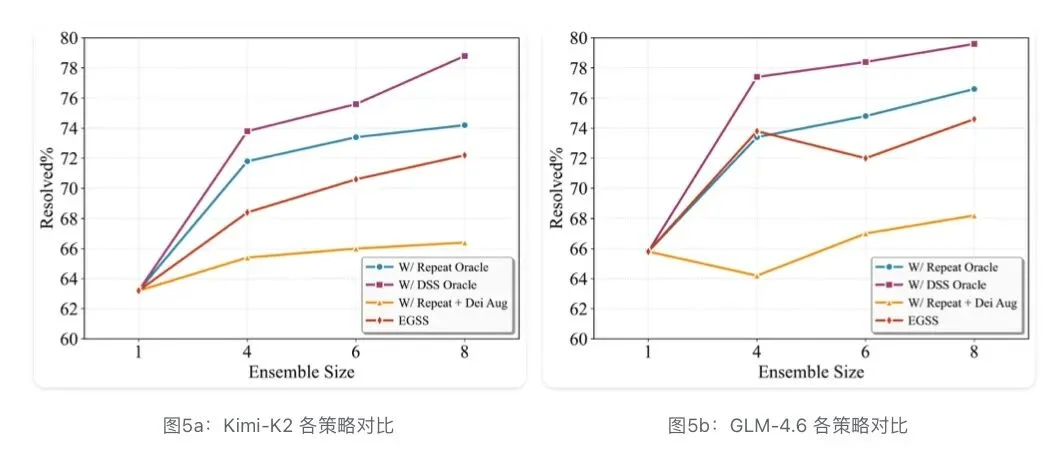
TCA在各K值下一致优于Dei Aug,且随着K增大趋近Oracle上界——
这说明TCA能有效利用更多候选的优势,而不会因噪声增加而退化。
消融实验:Test Consolidation是核心驱动力
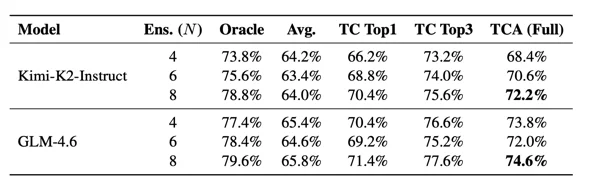
- TC Top1大幅超越随机基线:GLM-4.6在N=8时提升+7.2%;
- TC Top3接近Oracle上界:GLM-4.6在N=8时TC Top3达到77.6%,仅差Oracle2%;
- Test Consolidation是主要性能驱动力:整合测试套件的排名能力几乎触及理论上界,Augmentation投票机制提供额外稳定性。
核心启示:结构化复杂性 > 暴力扩展
在复杂领域如软件工程中,结构化的架构复杂性是实现成本效益自主性的必要前提,而非简单的开销。
通过用“熵引导的定向探索”替代“暴力的均匀扩展”,用“跨轨迹测试整合”替代“单一视角验证”,EGSS在减少38-42%Token消耗的同时达到了更优精度,这证明了聪明的计算远比更多的计算更有效。
代码:https://github.com/codefuse-ai/CodeFuse-Agent
论文:https://arxiv.org/pdf/2602.05242
文章来自于"量子位",作者 "蚂蚁集团CodeFuse团队"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales

