阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应
什么是 Zvec

Zvec
Zvec 是阿里巴巴集团开源的一个进程内向量数据库。所谓"进程内",意味着它不是一个需要单独部署的服务,而是一个像 SQLite 那样的嵌入式库——你装个包,在代码里直接调用,它就运行在你的应用程序进程里。
这个项目在阿里集团内部经历了多年的生产环境考验,支撑过不少高要求的业务场景。2024年开源后,目前 GitHub 上已经有 9.3k 星。
Zvec 的使用场景很灵活:可以用来做原型验证和本地开发,可以嵌入到应用程序或边缘设备里,也能支撑亿级规模的生产系统。
数据模型:Collection、Document 和 Schema
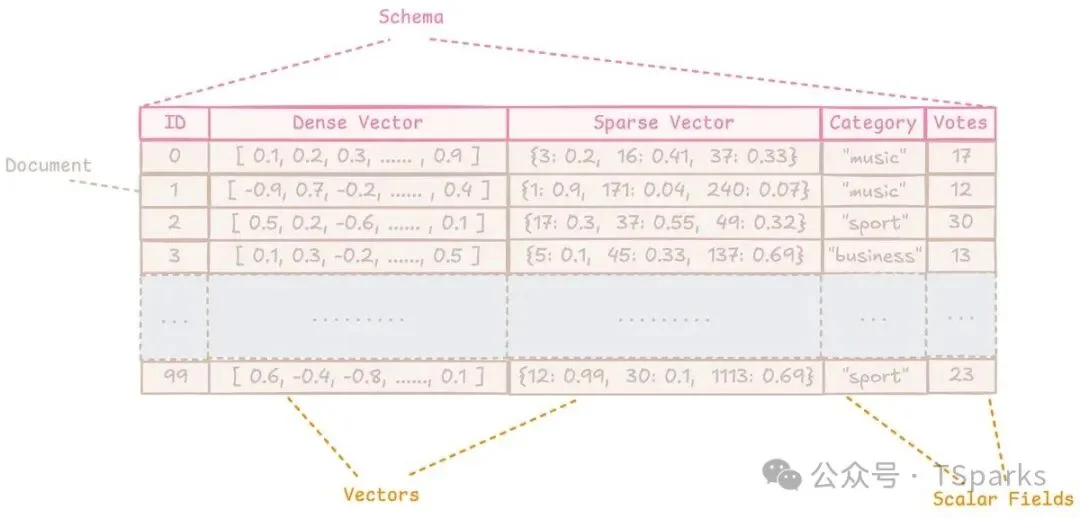
数据模型
理解 Zvec 怎么组织数据,先看三个概念。
Collection(集合) 是存放文档的容器,类似于关系数据库里的表。每个 Collection 有自己的 schema,定义了它包含哪些字段以及字段类型。不同 Collection 之间是隔离的,各自独立演化——比如你可以专门建一个 RAG 用的 Collection 存文本向量和元数据,再建一个图像搜索用的 Collection 存图像向量和标签。
Document(文档) 是存储的基本单位,相当于表里的一行记录。每个文档必须符合所属 Collection 的 schema。一个文档由三部分组成:
id:字符串类型的唯一标识符,插入后不可更改vectors:一个或多个向量字段fields:标量字段,支持字符串、数值、布尔值以及这些类型的数组
举个例子,一篇 RAG 用的文档可能长这样:
{
"id": "doc_001",
"vectors": {"embedding": [0.12, -0.34, 0.56, ...]},
"fields": {
"title": "Zvec 介绍",
"source": "https://zvec.org",
"word_count": 1240
}
}
Schema(模式) 是强类型的。标量字段分 STRING、BOOL、INT32、INT64、FLOAT、DOUBLE 以及对应的数组类型。向量字段分稠密向量和稀疏向量两种。插入数据时,每个字段必须严格匹配 schema 里声明的类型。
值得一提的是,Zvec 的 schema 是动态的——你可以在不重建 Collection 的前提下随时增删标量字段或向量字段。每个 Collection 独立保存在磁盘上的一个目录里,把这个目录挪到别处,Zvec 照样能打开。
有一点需要注意:Zvec 不支持跨 Collection 的查询,没有 join、union 或者多 Collection 联合搜索的能力。设计数据模型的时候要把这个因素考虑进去。
向量嵌入:把非结构化数据变成数字
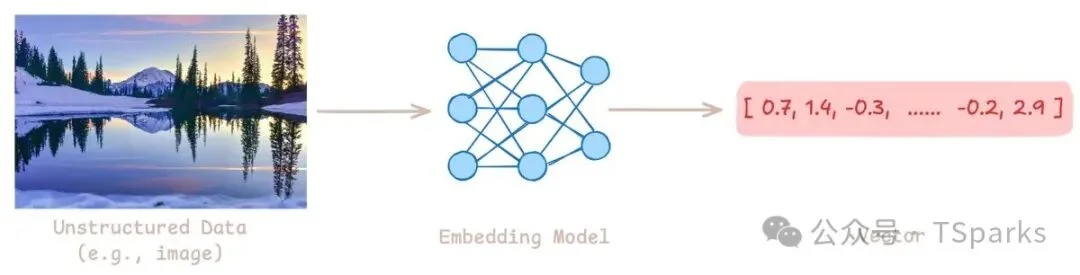
向量嵌入
向量数据库的核心是向量。向量是一串数字,由嵌入模型(Embedding Model)从非结构化数据——文本、图像、音频等——中生成,用来捕捉数据的语义信息。
嵌入模型做的事情,就是把原始数据映射到一个高维空间里,语义相似的东西在这个空间里距离更近。比如"国王 - 男人 + 女人 ≈ 女王"这种经典的语义关系,就是通过向量运算体现出来的。
使用向量数据库的工作流程很简单:
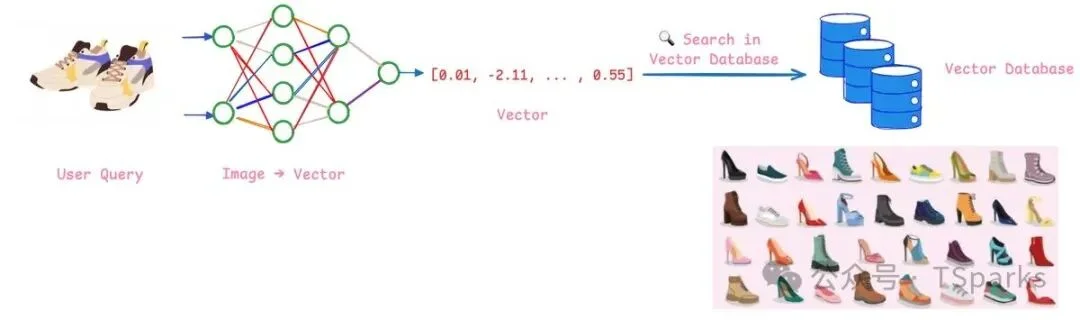
- 存:用嵌入模型把你的数据(文档、商品图片、用户画像等)转成向量,存进数据库
- 搜:用户发起查询时,用同一个嵌入模型把查询内容转成向量,然后让数据库找出最相似的向量
这就是语义搜索的原理——找的是"意思相同"的东西,而不是"字面相同"的东西。
Zvec 支持两种向量类型:
稠密向量(Dense Vector) 是定长的、实数组成的向量,几乎每个维度都承载语义信息,通常由深度学习模型生成。优点是语义丰富,缺点是难以解释哪些特征在驱动相似性。
稀疏向量(Sparse Vector) 维度很高,但大部分维度是零,只有少数维度有非零值。适合表示词袋模型这类特征。
嵌入模型的选择会影响最终效果。不同的嵌入模型针对不同的距离度量(余弦相似度、点积、欧氏距离等)进行训练,Zvec 在搜索时应该使用相同的度量,才能保证语义关系不丢失。
向量索引:为什么亿级数据还能毫秒响应
没有索引的情况下,向量检索只能做暴力搜索——把 query 向量和库里的每一个向量做距离计算。这种方法准确率 100%,但数据量上了百万级,查询耗时就是秒级甚至分钟级,没法用在生产环境。
Zvec 使用近似最近邻(ANN) 算法来加速检索。ANN 不保证找到绝对最接近的结果,但能找到非常接近的——在实际应用中,这种精度损失通常感知不到,换来的却是数量级的性能提升。
衡量 ANN 质量的指标叫 召回率(Recall) 。比如你请求 top 10 结果,暴力搜索返回的真正 top 10 里有 9 个出现在了 ANN 返回的结果里,召回率就是 90%。一般来说召回率达到 96% 以上,实际使用中就和精确搜索没什么区别了。
Zvec 提供了多种向量索引类型,可以根据数据规模、延迟要求和精度容忍度来选择。
DiskANN:当数据大到内存装不下
DiskANN 是 Zvec v0.5.0 新引入的索引类型,来自微软研究院 2019 年发表在 NeurIPS 上的论文。
它的核心思想是:把压缩的向量放内存,把完整的向量和图结构放磁盘。搜索时,内存里的 PQ(Product Quantization)编码用来快速估算距离,磁盘上的完整向量用来做最终的精确计算。
具体来说,DiskANN 做了三件事:
- Vamana 图:构建一个单层图结构,每个节点最多连接
max_degree个邻居。图里有一个"中心点"(medoid)作为所有搜索的固定入口。搜索时从中心点出发,通过贪婪搜索逐步逼近目标区域。 - PQ 量化:把向量空间切分成多个子空间,每个子向量量化成 256 个质心之一(8-bit PQ 编码)。查询时预先计算好 PQ 距离查找表,用查表代替浮点运算,大幅降低计算成本。
- 缓存束搜索:搜索时同时扩展多个前沿节点,批量读取磁盘 I/O。入口附近的热点节点会被缓存在内存里。
DiskANN 的代价是查询吞吐量(QPS)比纯内存索引低,因为每次查询都涉及磁盘 I/O。它适合的场景是:
- 十亿级别的数据集,内存装不下
- 对内存成本敏感、对吞吐量有一定容忍度的场景
- 批量处理这类对延迟不敏感的任务
注意:DiskANN 目前只支持 Linux,需要系统安装 libaio 库。Ubuntu 24.04 等较新发行版可能因为 libaio1t64 的 ABI 不兼容导致链接错误,这种情况需要从源码编译。
倒排索引:加速标量字段的过滤查询
向量检索之外,Zvec 也支持对标量字段做高效过滤。倒排索引就是干这个的。
什么叫"倒排"?正常视角是"文档 → 它包含什么值",倒排索引反过来,变成"值 → 哪些文档包含它"。
举个例子,有一批菜谱文档:
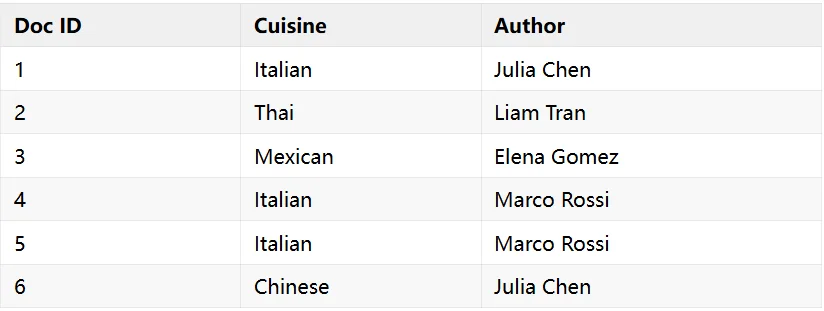
给 cuisine 字段建倒排索引后,查询"找所有 Italian 菜谱"直接查索引→得到 [1,4,5],瞬间完成。给 author 也建索引,就可以做交集查询——"找 Julia Chen 写的 Italian 菜谱",把两个索引的结果交集一下→[1]。
倒排索引适合的场景包括:
- 精确值过滤:
status = "active" - 范围查询:
age > 25 - 文本模式匹配:
product_name LIKE "Wireless%" - 数组成员查询:
tags CONTAIN_ANY ["sport", "music"]
倒排索引不是免费的——它占用存储空间,拖慢写入速度。所以只给那些频繁用于过滤的字段建索引,像 url 这种几乎不用来查询的字段就不建。
全文索引:让文本搜索带上相关性排序
全文索引(FTS,Full-Text Index)是 Zvec v0.5.0 的另一个重要新特性。它和倒排索引的区别在于:
- 倒排索引:对标量字段做精确值过滤,比如
status = "active" - 全文索引:对文本内容做关键词检索,按相关性排序
全文索引的工作流程分三步:
第一步:分词(Tokenization) 。把文本切分成一个个 token。一篇文档 "Training and optimizing machine learning models" 会被切分成 [training, optimizing, machine, learning, models]。
第二步:建倒排映射。把 token 映射到包含它的文档列表:
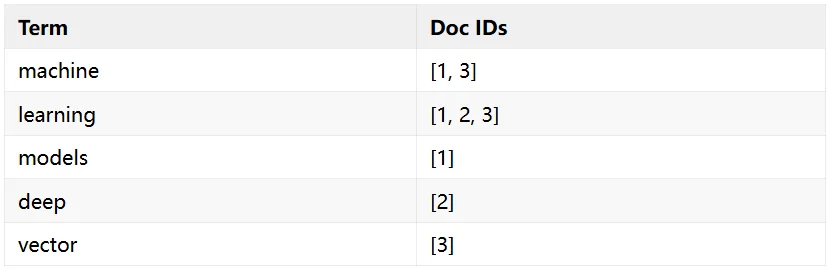
第三步:BM25 打分。用户搜 "machine learning" 时,索引找到包含这些词的文档 [1,2,3],然后用 BM25 算法给每个文档算一个相关性分数。BM25 考虑三个因素:
- 词频(TF):同一个词在文档里出现越多次,分数越高(但有递减效应)
- 逆文档频率(IDF):越稀有的词权重越高
- 文档长度:同样的情况下,短文档得分更高
为了在大数据集上高效检索,Zvec 的全文索引还用了 WAND(Weak AND)算法优化——预先计算每个词的上界分数,跳过那些不可能进入 top-k 的文档,用 Block-Max 策略批量跳过 128 个文档组成的块。
全文索引支持:
- 自然语言查询
- 精确短语匹配:
"vector database"匹配完整短语 - 布尔检索:
+machine -neural要求包含 machine、排除 neural - 多语言:内置英文类语言和中文的分词器
- 纯文本场景:甚至可以建一个没有向量字段、只用全文搜索的 Collection
混合检索:把向量、全文和过滤揉在一起
Zvec v0.5.0 支持混合检索(Hybrid Search) ——在一次查询里同时使用向量相似性、全文搜索和标量过滤。
这意味着你可以这样搜:找一篇"和这个 query 向量语义相似"、同时"正文里包含 machine learning 这个词"、而且"发布时间在 2025 年之后"的文章。三种检索能力叠加,结果更精准。
持久化与并发
Zvec 用预写式日志(WAL) 保证数据持久化。即使进程崩溃或者断电,已经写入的数据也不会丢。
并发方面,多个进程可以同时读取同一个 Collection,但写入是单进程独占的。如果你的场景需要高并发写入,这个限制需要留意。
安装与快速上手
Zvec 提供了多种语言的官方 SDK:Python、Node.js、Go、Rust、Dart/Flutter。
Python 安装:
pip install zvec
支持 Python 3.10 到 3.14。支持的平台:Linux(x86_64、ARM64)、macOS(ARM64)、Windows(x86_64)。
一分钟跑起来:
import zvec
# 定义 schema
schema = zvec.CollectionSchema(
name="example",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
# 创建并打开 Collection
collection = zvec.create_and_open(path="./zvec_example", schema=schema)
# 插入文档
collection.insert([
zvec.Doc(id="doc_1", vectors={"embedding": [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id="doc_2", vectors={"embedding": [0.2, 0.3, 0.4, 0.1]}),
])
# 向量检索
results = collection.query(
zvec.VectorQuery("embedding", vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
print(results)
不想写代码的话,可以用 Zvec Studio 可视化工具,浏览数据和调试查询。
Zvec 走的是"轻量但能打"的路线——小到本地原型、大到十亿级生产系统都能跑。v0.5.0 加的全文搜索、混合检索和 DiskANN 索引,补齐了它作为一款通用向量数据库的关键能力。如果你在做 RAG、语义搜索或者推荐系统,又不想被重型基础设施拖累,Zvec 值得花点时间试试。
项目地址:zvec.org | GitHub:github.com/alibaba/zvec
文章来自于"尧字节",作者 "尧字节"。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

