全员本科生!
刚刚,何恺明携本科生“军团”又放出一篇新论文。
继去年探索直接从像素预测图像的JiT架构后,团队这次又把这套“删繁就简”的思路扩展到了文生图领域,推出全新工作:
MiniT2I。
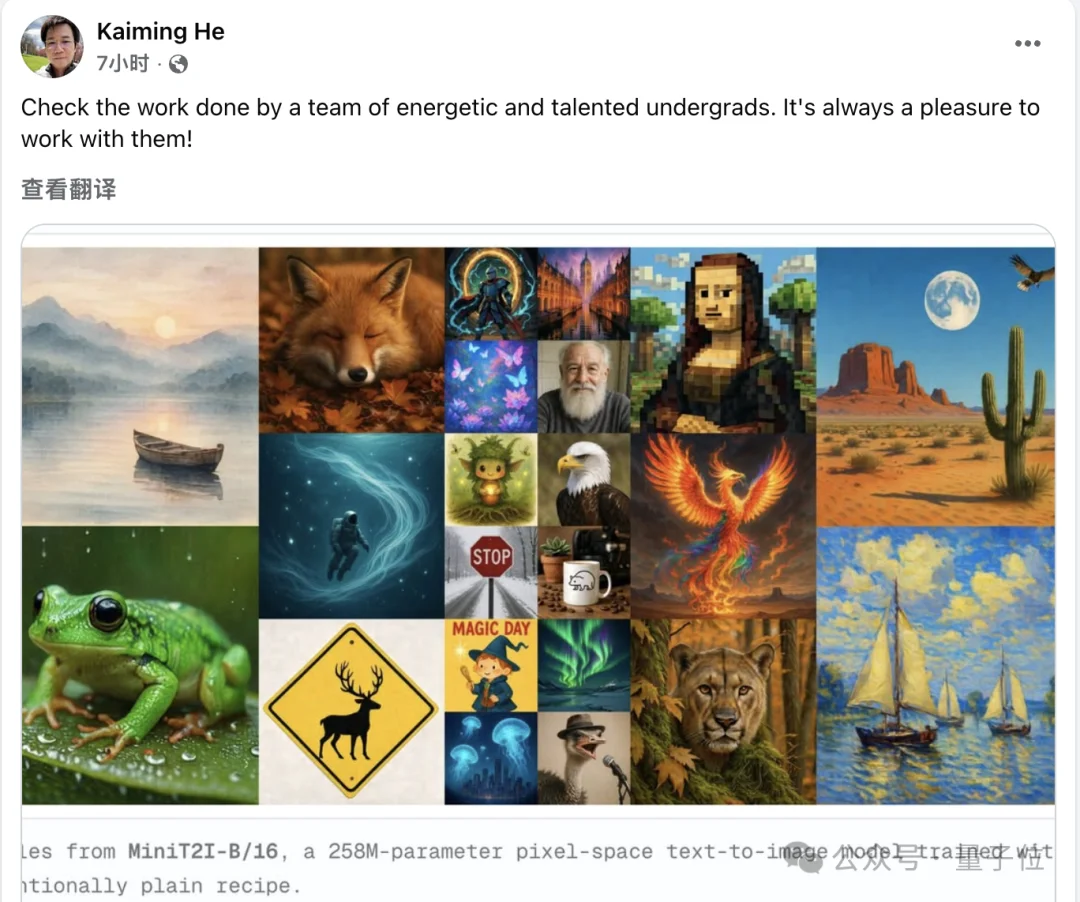
在今天动辄数十亿参数、海量图文数据训练文生图模型的背景下,MiniT2I选择了另一条路。
它基于全新的MM-JiT架构,直接在像素空间进行扩散生成,同时尽可能压缩模型复杂度和训练成本。
最终,仅用258M参数,就实现了不错的文生图效果。
更关键的是,整个训练成本只相当于一次标准ImageNet实验。
这是怎么做到的?
从JiT到MM-JiT
整体看来,MM-JiT是恺明组之前论文「Back to Basics」在T2I(文本生成图像)方向上的延伸。

Back to Basics中,恺明和他的博后黎天鸿提出了JiT架构,Just image Transformers。
JiT的核心主张是:抛开VAE编解码器,直接在像素空间预测干净图像(x-prediction),而不是像传统扩散模型那样预测噪声。
这样做的好处是,整个生成流程更加直接,符合流形假设以及“从像素出发”的第一性原理。
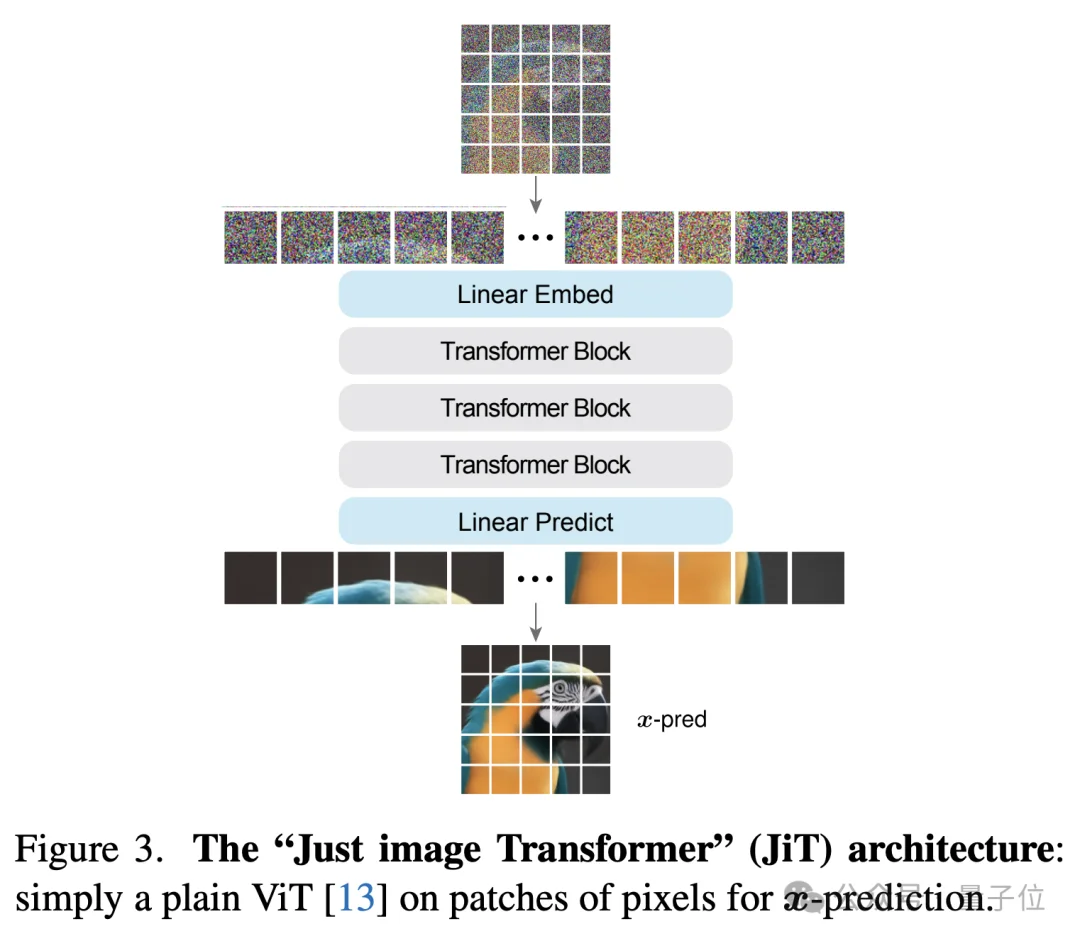
不过,当时的JiT主要针对类别条件生成(class-conditional generation),任务范围相对有限,模型只能根据ImageNet的类别标签生成对应图像。
然而,真实的图像生成任务往往不限于ImageNet的1000个固定类别,而是需要理解并遵循开放的文本Prompt。

问题也随之而来。一旦从类别生成扩展到文生图,训练成本往往会迅速攀升。
无论是SD3、FLUX.1-dev还是DALL·E 3,背后都依赖多阶段训练流程、庞大的文本编码器以及海量数据资源。
对于大多数学术团队而言,从零开始训练一个完整的文生图模型,几乎是一项难以承担的工程。
于是,MiniT2I应运而生。

它试图回答一个更现实的问题:
如果只用接近ImageNet训练规模的计算资源,能不能也做出效果不错的文生图模型?
答案是,可以。
研究发现,当文本首先被预训练语言模型编码为语义表示后,对于生成模型而言,文本条件本质上只是另一种形式的上下文条件。
换句话说,文生图或许并没有想象中那么特殊。
在模型架构、训练计算量,甚至所需数据规模上,它与类别条件生成的差距远没有业界普遍认为的那么大。
如果这个判断成立,那么一个很自然的问题就出现了:
既然类别条件生成已经能用JiT这样的极简架构完成,那么文生图任务里那些复杂的模块,究竟哪些是真正必要的?
MM-JiT给出的答案是:把它们一个个删掉,再看模型还能不能工作。
MM-JiT:删繁就简
对于上面这个问题,MiniT2I项目负责人王衔邦在X上的总结非常精炼:
我们的原则很简单,能去掉的全去掉。起点是像素空间、标准的T5-Large编码器,以及一个采用x-prediction的简洁多模态骨干MM-JiT。
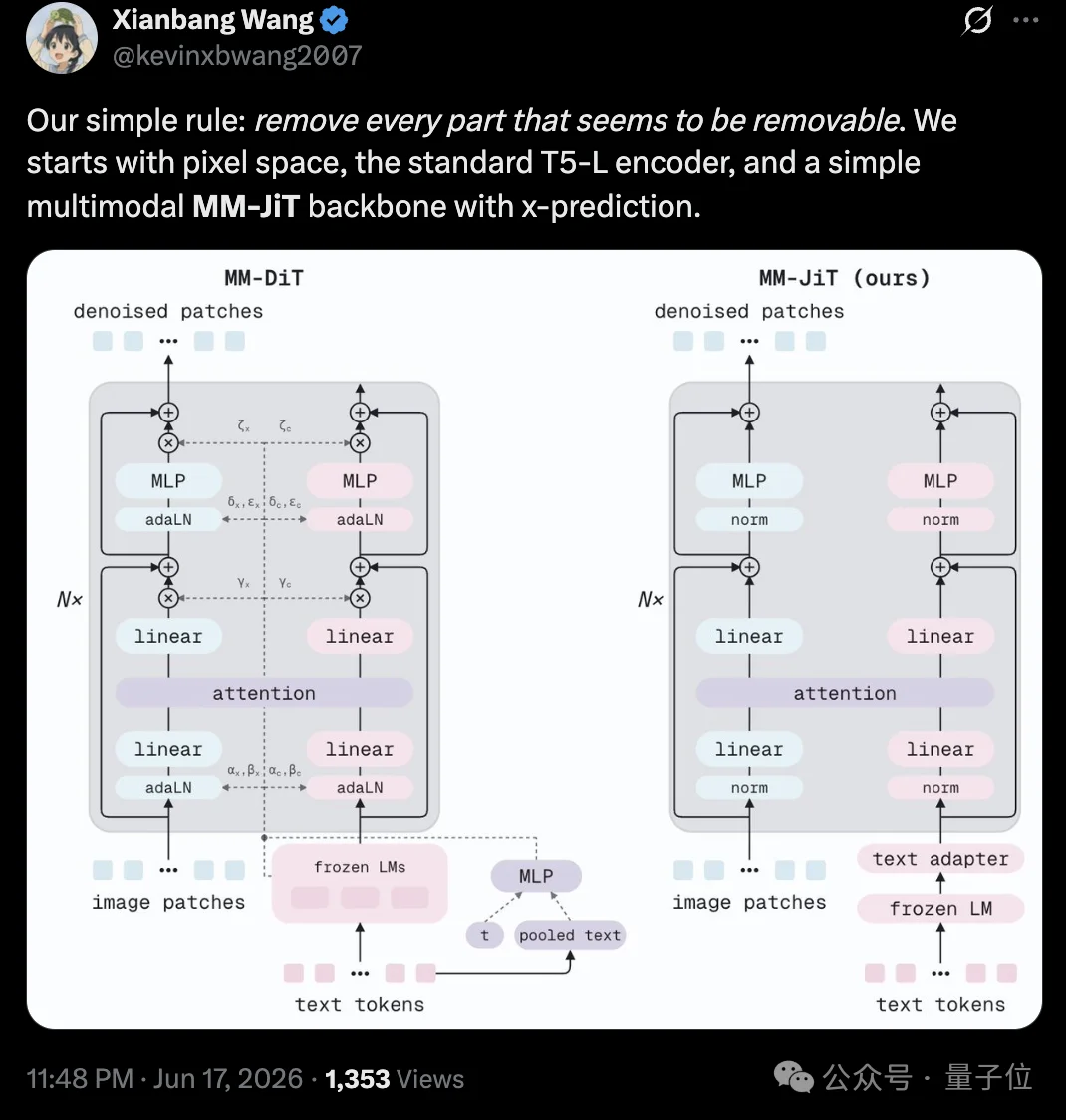
这套思路的第一刀,砍向了VAE。
众所周知,当前主流文生图模型大多采用潜在扩散(Latent Diffusion)路线:
先通过VAE把图像压缩到低维潜空间,再在潜空间里完成扩散生成,最后解码回像素。
这样做的好处是显著降低计算量,但代价也很明显——
VAE会带来重建误差和伪影,同时还额外增加了一套编解码器的训练流程。
针对这一问题,在前作JiT中,团队已经证明,至少在ImageNet任务上,直接在像素空间建模并不存在所谓的“不可逾越瓶颈”。
那么在文生图任务里,VAE是否真的不可替代?
团队决定直接把它删掉试试。
MiniT2I将扩散过程重新搬回像素空间,希望验证一个看似反常识的判断:直接在像素空间扩散,不仅完全可行,而且未必比潜空间路线更贵。
实验表明,传统潜空间模型单次前向传播需要1379 GFLOPs,而彻底摆脱VAE之后,MiniT2I的计算开销仅为265 GFLOPs,直接降低了约80%。
删掉VAE之后,团队又把目光转向了模型架构本身。
前作JiT面向的是ImageNet分类条件生成,因此采用标准DiT,并通过AdaLN-Zero注入类别标签和时间步信息。
但到了开放式文生图任务,最自然的参考对象就变成了SD3采用的MM-DiT。
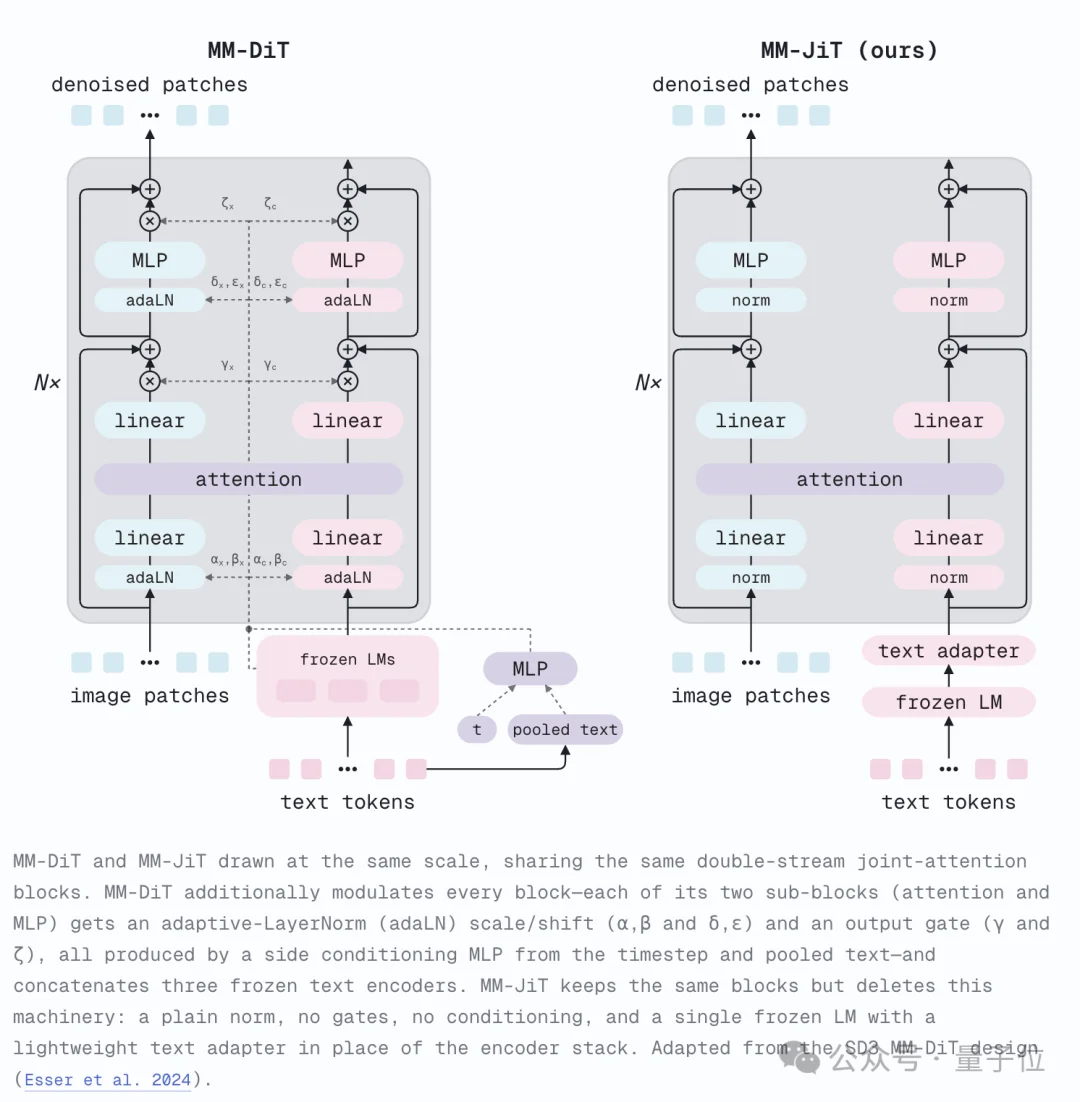
在团队看来,MM-DiT身上仍然挂着不少“历史包袱”。
其中最典型的就是AdaLN机制。模型会把时间步和池化后的文本特征转换成缩放、偏移和门控参数,并注入到每一层网络中。
MM-JiT的选择则相当激进:直接把AdaLN整个删掉。
理由也很简单——扩散模型当前所处的噪声水平,其实已经包含在加噪后的输入 z_t 里。
换句话说,模型完全可以自己推断当前处于扩散过程的哪个阶段,并不需要额外开一条通道专门传递时间步信息。
于是,条件信息只通过联合注意力这一条路径进入模型,整个骨干网络也回归到更接近标准Pre-Norm Transformer的形式。
与此同时,团队只额外增加了两个Text Adapter Block,放在联合注意力之前,让冻结的T5文本特征先完成一次适配,再与图像Token交互。
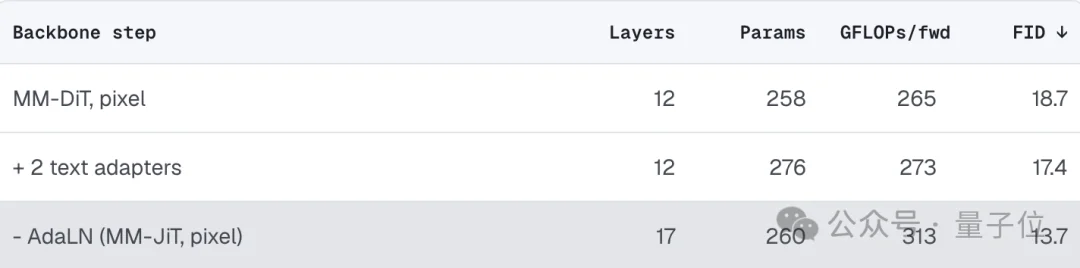
实验结果再次验证了团队的判断。
参数量几乎保持不变,依旧只有260M,但模型性能却一路提升:
FID从18.7(MM-DiT像素空间基线),提升到17.4(加入Text Adapter),最终达到13.7(移除AdaLN后的MM-JiT)。
训练与实验
在具体实现上,MiniT2I基于流匹配(Flow Matching)框架,网络直接预测干净图像,并在速度空间计算损失。
训练分为两个阶段:首先在CC12M上预训练25万步,学习基础视觉分布;随后在12万张高质量合成图像上微调4万步,进一步提升Prompt遵循能力。
结果证明,这套极简设计并没有牺牲性能。
B/16版本总参数量不到600M,在GenEval上达到0.87、DPG-Bench达到84.2,超过了多款参数规模数倍于自身的像素空间文生图模型。
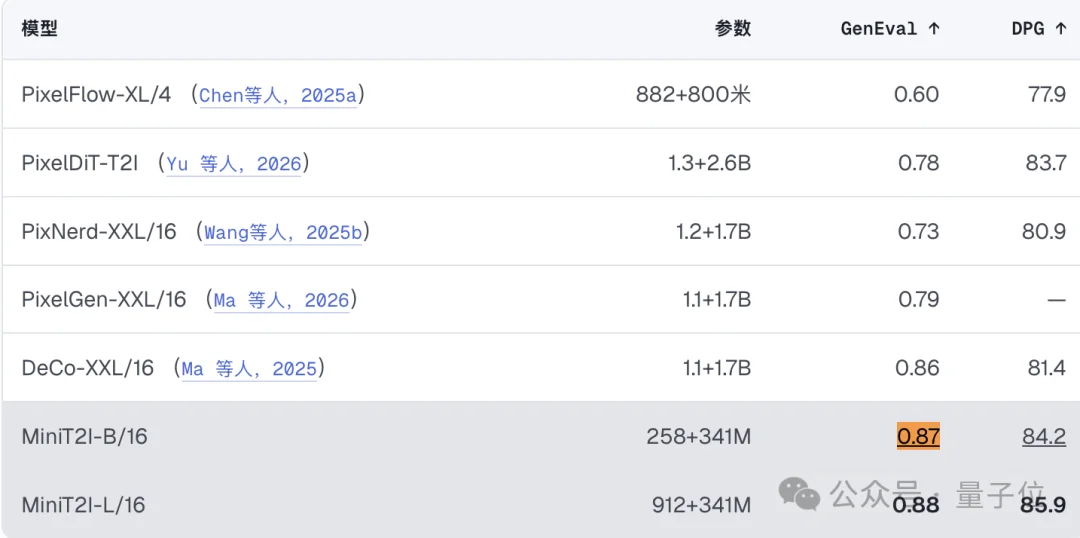
更重要的是,完成这一训练仅需约等于一次标准ImageNet实验的算力预算——8张H100,大约3天。
即便与工业级模型相比,MM-JiT也展现出不俗竞争力。
在PRISM-Bench上,L/16版本取得62.4分,而FLUX.1-dev为68.5分。具体来看,模型在风格表现和开放想象力两个维度甚至超过了FLUX;
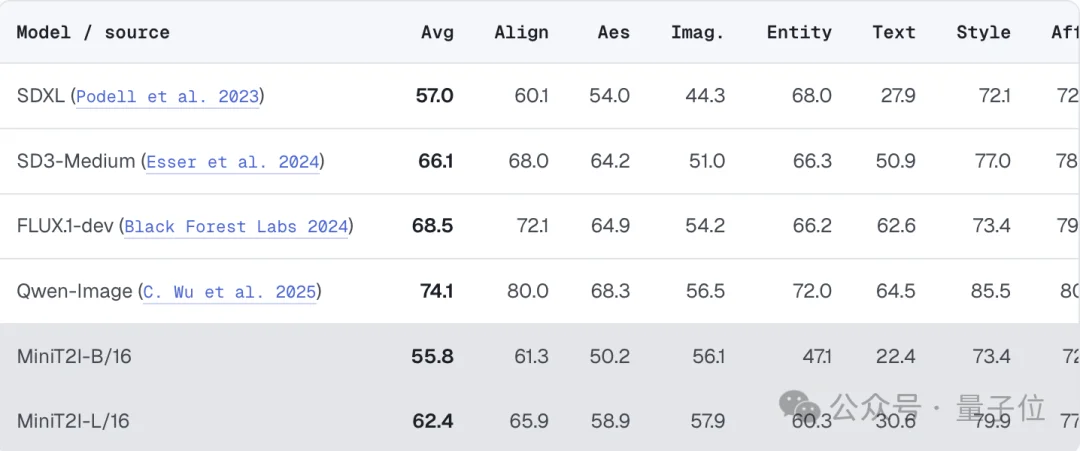
短板方面,则主要集中在文字渲染和命名实体生成,这与公开训练数据覆盖范围有限有关。
(注:具体实验设置可参考文末博客链接)
作者介绍
这篇工作最值得聊的,除了技术本身,还有背后的作者们。
整篇论文一共六位作者。除了何恺明之外,其余五位都还是本科生。
而且,这些年轻面孔并不是第一次出现在论文作者栏里。在何恺明团队此前的多篇工作中,他们都已经开始崭露头角。

项目负责人王衔邦(Xianbang Wang)目前是MIT大一本科生,去年刚从人大附中毕业。

2024年,他代表中国队参加第65届国际数学奥林匹克竞赛(IMO),拿下金牌。
更早之前,他还在2021年和2022年斩获全国信息学奥林匹克竞赛的银牌。
在这项工作之前,他已经是何恺明团队Bidirectional Normalizing Flow论文的共同第一作者。

另一位核心贡献者赵瀚宏(Hanhong Zhao),目前是MIT大二学生,曾获得国际物理奥林匹克竞赛(IPhO)金牌。

不久前引发关注的ELF(连续扩散语言模型)论文中,赵瀚宏也是作者之一。
核心贡献者陆伊炀(Yiyang Lu)则来自清华大学姚班,目前大二,在MIT CSAIL实习,导师正是何恺明。

高中时期,他是物理竞赛生,曾以江苏省第一、全国第九的成绩获得第39届全国中学生物理竞赛(CPhO)金牌。
此前,他已经与何恺明合作完成Bidirectional Normalizing Flow、Pixel Mean Flow等工作,在ELF论文中同样名列作者名单。
周康阳(Kangyang Zhou)也是MIT本科生(Class of 2029),背景更偏信息学方向。
2024年,他在第36届国际信息学奥林匹克竞赛(IOI)中夺冠,并以600分满分成为当届唯一满分选手。
更早的2023年,他以全国信息学奥林匹克竞赛(NOI)金牌第一名的成绩入选国家集训队,领先第二名55分。今年,他还作为MIT代表队成员获得ICPC 2026北美锦标赛冠军。
马麟瑞(Linrui Ma)同样毕业于人大附中,目前在MIT就读本科。

他曾担任中国国家队队长,在第56届国际化学奥林匹克竞赛(IChO 2024)中获得金牌。
最后再简单介绍一下何恺明。
目前,他是MIT EECS终身副教授,同时兼任Google DeepMind杰出科学家。

他是深度学习、计算机视觉一系列重要工作,如ResNet、Faster R-CNN、Mask R-CNN、MoCo、MAE的作者。其中,ResNet是21世纪被引用次数最多的论文。
某种程度上说,这篇论文最有意思的地方,不只是提出了一个新方法,更像是一群刚刚走出奥赛赛场的年轻人,已经开始站上AI研究最前沿的舞台。
参考链接
[1] https://peppaking8.github.io/#/post/minit2i
文章来自于"量子位",作者 "henry"。
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

