本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集、完整训练代码,以及针对异构多任务的新算法 TMN-Reweight。

- 论文标题:GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
- 论文链接:https://huggingface.co/papers/2605.19577
- GitHub:https://github.com/xiaoxuanNLP/GoLongRL
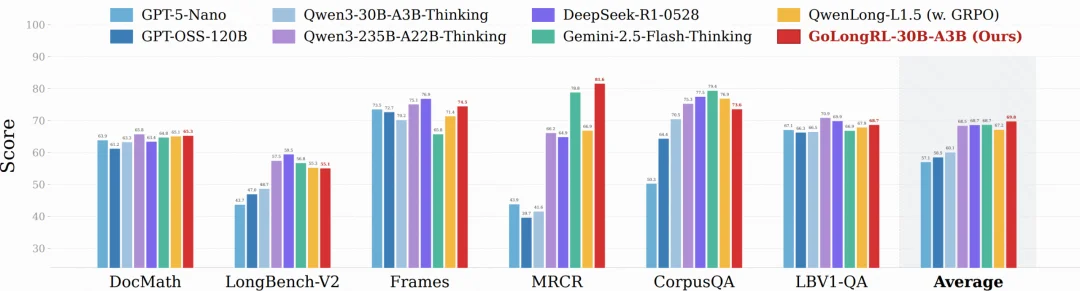
图 1:GoLongRL-30B-A3B 与各顶级模型的长上下文综合评测对比
为什么现有的长上下文 RL 方法不够好?
当前主流的长上下文 RL 方法(LoongRL、LongRLVR、QwenLong-L1.5 等)有两个共同问题:训练数据基本围绕 “在更长文本里找更难找的答案” 这条路走,任务覆盖高度同质;奖励设计被压缩为单一的精确匹配或准确率,排序、摘要、穷举检索这些能力几乎没有直接监督。
数据:以能力为导向
三大设计原则
GoLongRL 的数据构造遵循三大原则:能力导向、奖励与任务语义对齐、真实文档优先。
能力导向。参考 LongBench Pro 提出的能力分类体系,定义了 9 种核心任务类型,覆盖长上下文理解所需的关键能力维度。T1-T4 构成训练主干(占比超过 90%),覆盖基础长上下文能力;T6-T9 的样本量相对较少(合计不足 4%),但每种任务都保留了其最自然的奖励形式,确保完整的能力覆盖。
这 9 大任务类型及其对应的能力维度如下:
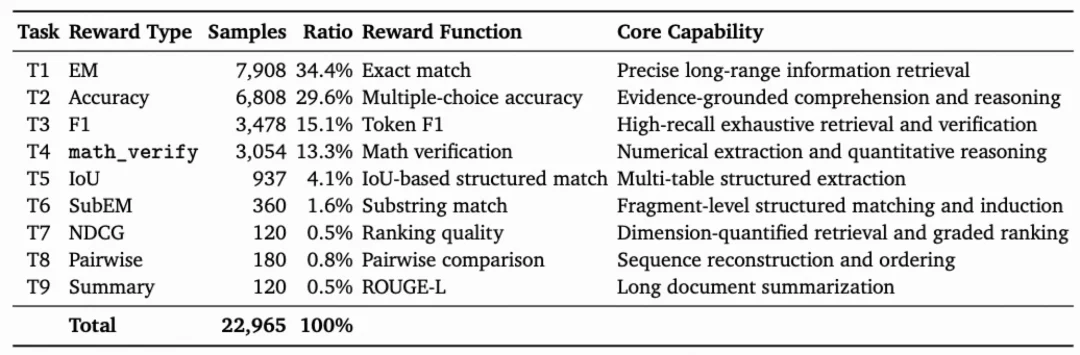
表 1:GoLongRL 数据集能力类型及其对应奖励
奖励与任务语义对齐。长上下文任务在评估维度上差异显著:摘要依赖 ROUGE,排序依赖 NDCG,抽取依赖 F1,将其统一压缩为单一指标会损失大量任务特有的语义信息。GoLongRL 为每类任务单独配置最契合其目标的评估指标作为奖励函数,使 RL 训练中的反馈信号与任务本身的评估逻辑保持一致。
真实文档优先。基于模板的合成数据存在一个结构性风险:当多段短文档被拼接为长输入时,段落边界与格式标记本身携带了可被利用的位置信息,模型容易习得依赖这类浅层线索作答的捷径,而非形成真正的跨段落理解能力。因此 GoLongRL 以书籍、学术论文、法律文书和财务报告等真实文档为主要训练来源。对于标注稀缺的领域,仅在真实文档上合成问答对,而非生成文档本身。
图 2:训练数据的 UMAP 投影
数据来源:开源策略与合成策略并行
数据集的 22,965 个样本来自两个互补的池子:
- 约 14K 开源样本:从 CLongEval、LongBench Pro、MultiTableQA、CAIL2018 等已开源的长上下文语料库中改写,这些样本已有人工验证的标注,覆盖法律案例、财务报告、文学小说和多轮对话等多个领域。
- 约 9K 合成样本:问答对由真实源文档生成,源文档包括 Project Gutenberg 图书、arXiv CC0 等自然长文素材。合成的是问答对本身,而非文档。
四阶段构造 pipeline
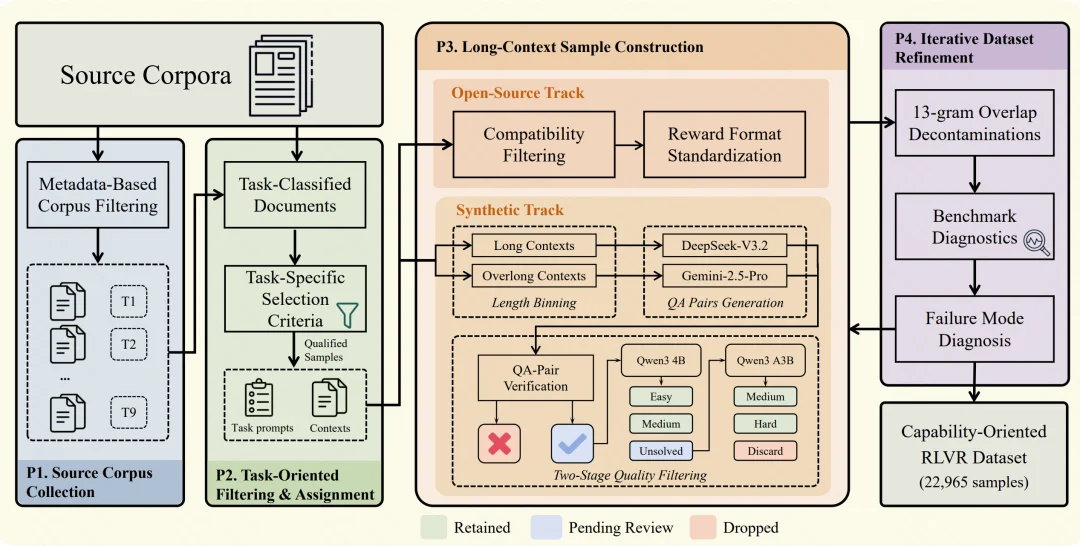
图 3:GoLongRL 数据构造四阶段 pipeline
整个数据集通过统一的四阶段流水线生产:
- P1 源语料收集:按 9 类任务分别收集有标注的开源数据集和无标注真实文档,尽量覆盖不同领域、文档结构和长度区间。
- P2 任务过滤与分配:对每个样本按任务语义分配唯一标签。比如 CLongEval 里定位单一事实的样本归 T1,CAIL2018 里需要聚合多条法律条款的归 T3,对话记忆子类(T2)只保留超过 50 轮、30K Token 以上的对话。
- P3 样本构造:开源数据做兼容性过滤和奖励格式标准化(如把数值答案改写为 math_verify 可解析格式)。合成数据按文档长度分桶,普通长度用 DeepSeek-V3.2 生成问答对,超长文档交给 Gemini-2.5-Pro;生成后经两阶段质量过滤 —— 先由 Gemini-2.5-Pro 验证答案唯一性和无幻觉,再用 Qwen3-4B 和 Qwen3-30B-A3B 的多级通过率测试剔除标签噪声。
- P4 迭代精化:先做 13-gram 重叠过滤防数据污染,再训练并做基准诊断。某维度停滞就排查奖励作弊、答案歧义等问题并清除;信号不足就回到 P1–P3 定向补数据,循环至性能和质量稳定。
TMN-Reweight:面向异构多任务的优化算法
能力导向的数据集带来了 9 种不同的奖励函数,它们的数值尺度和方差分布各不相同。在标准 GRPO 框架下进行混合训练时,优化过程面临两个相互纠缠的问题。

TMN-Reweight 的核心思路
TMN-Reweight 将尺度归一化与难度校正解耦为两个独立步骤。

实验结果
主要结果:4B 模型达到 SOTA
4B 规模上的实验设计使得数据贡献和算法贡献可以独立评估:
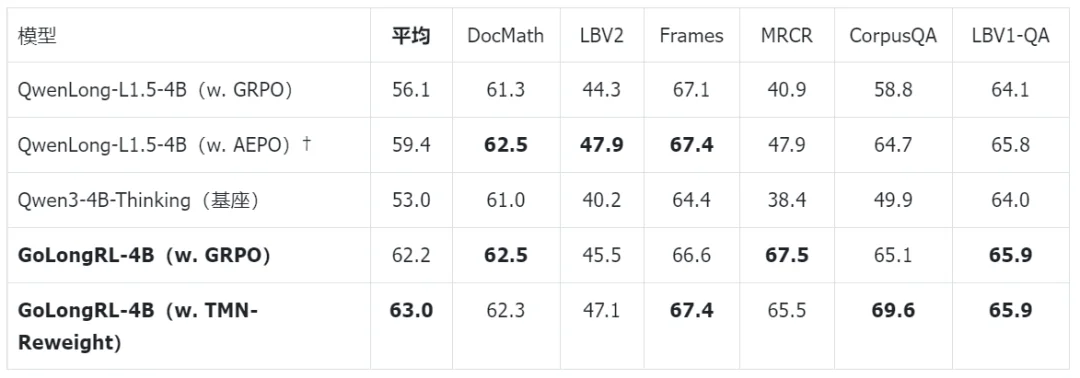
表 3:主实验 - 4B
4B 规模:仅凭数据,vanilla GRPO 已比 QwenLong-L1.5(GRPO)高 6.1 分(62.2 vs 56.1),甚至超过其专用算法 AEPO 版本(59.4 分)。加上 TMN-Reweight 进一步提升至 63.0。
主要结果:30B 模型超越顶级旗舰模型
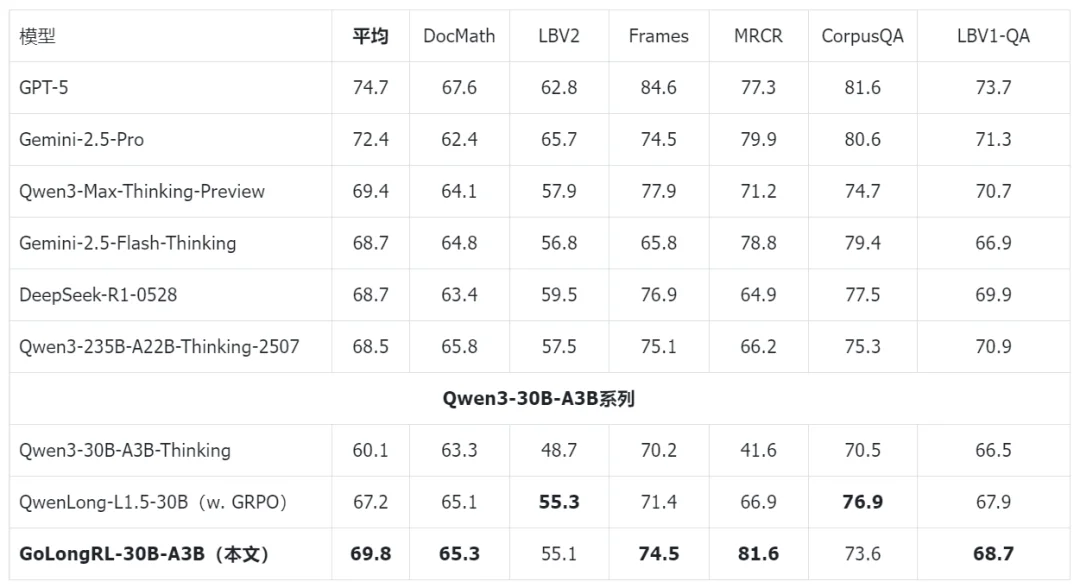
表 4:主实验 - 30B
30B 规模:GoLongRL-30B-A3B 以 69.8 分超越 DeepSeek-R1-0528(68.67)、Qwen3-235B-A22B-Thinking-2507(68.45)和 Gemini-2.5-Flash-Thinking(68.73),也全面超越同等算法(GRPO)训练的 QwenLong-L1.5-30B(67.2)。
通用能力保持与迁移
长上下文 RL 训练没有带来负迁移。通用推理上,4B 和 30B 模型在 MMLU-Pro、AIME24/25、GPQA-Diamond 上均有小幅提升,两个规模的模型趋势一致。
更值得关注的是迁移效果。Agentic Memory 的 Memory-Vec 和 Memory-Rec_Sum 两项任务训练中从未出现过,但 4B 模型 Memory-Rec_Sum 仍提升了 9.7 分,30B 提升 4.5 分。对话记忆(LongMemEval)两个规模均提升 13.6 分(4B: 47.6→61.2;30B: 61.6→75.2),30B 超过 QwenLong-L1.5-30B 的 72.2 分。说明长上下文 RL 学到的信息整合能力能迁移到训练中没见过的任务上。
长度外推能力
GoLongRL 训练上下文为 160K,但能力可以泛化到更长的序列。4B 模型在 MRCR 128K–512K 提升 12.27 分、512K–1M 提升 3.50 分;30B 更明显,MRCR 128K–512K +12.61、512K–1M +5.45,CorpusQA 1M +2.74。160K 训练习得的能力没有被局限在训练长度范围内。
总结
数据覆盖度和奖励多样性是长上下文 RL 的主要瓶颈,而非算法本身。把任务从 "复杂检索路径" 扩展到更全面的能力维度,并为每种任务匹配语义合适的奖励函数,即使较小的模型也能达到与旗舰模型相当的长上下文性能。
数据集、模型和训练与评测代码已完整开源。
文章来自于微信公众号 “机器之心”,作者 “机器之心”
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md


