一觉醒来,AI的新潮流变成了养猫???
火速围观一下,刚刚全球流式音视频模型赛道闯进了一匹黑马,能力SOTA级,模型名字就叫缅因猫(MaineCoon)。
养过缅因猫的朋友都知道,这个品种有个外号叫「猫狗」,意思是几乎你走到哪儿,它就跟到哪儿,相当粘人,互动感MAX。
而模型MaineCoon和它几乎是如出一辙,不会一股脑生成完就跑,而是一直陪着你、follow你的状态,实时地往下走。
比如这样:
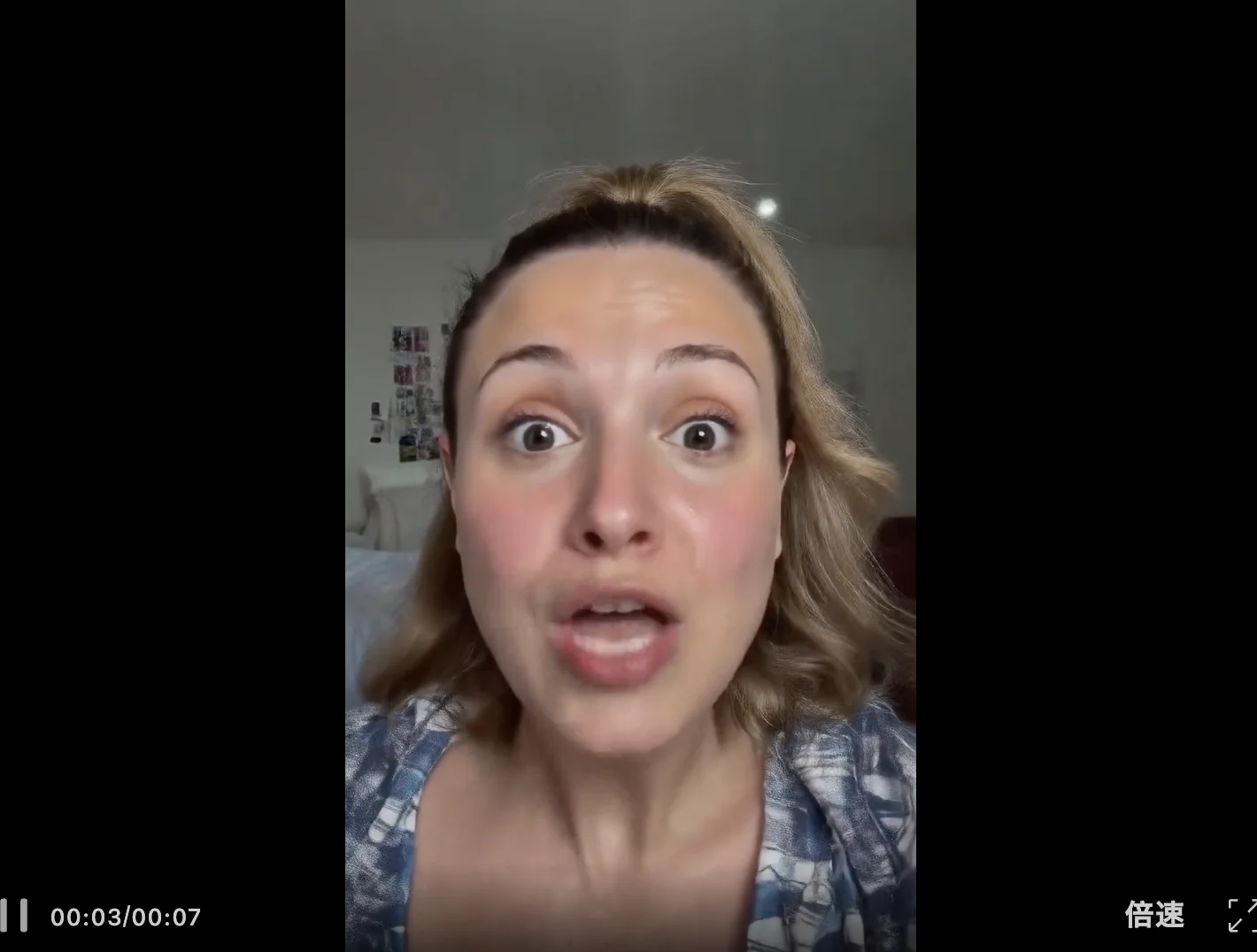
给它一段文字,它直接边生成边播放,还能做到音画同出,效果就像是在和真人主播1V1视频对话,而且永远不会卡顿。
时长可达30分钟以上,这也是业界首次实现这个长度。
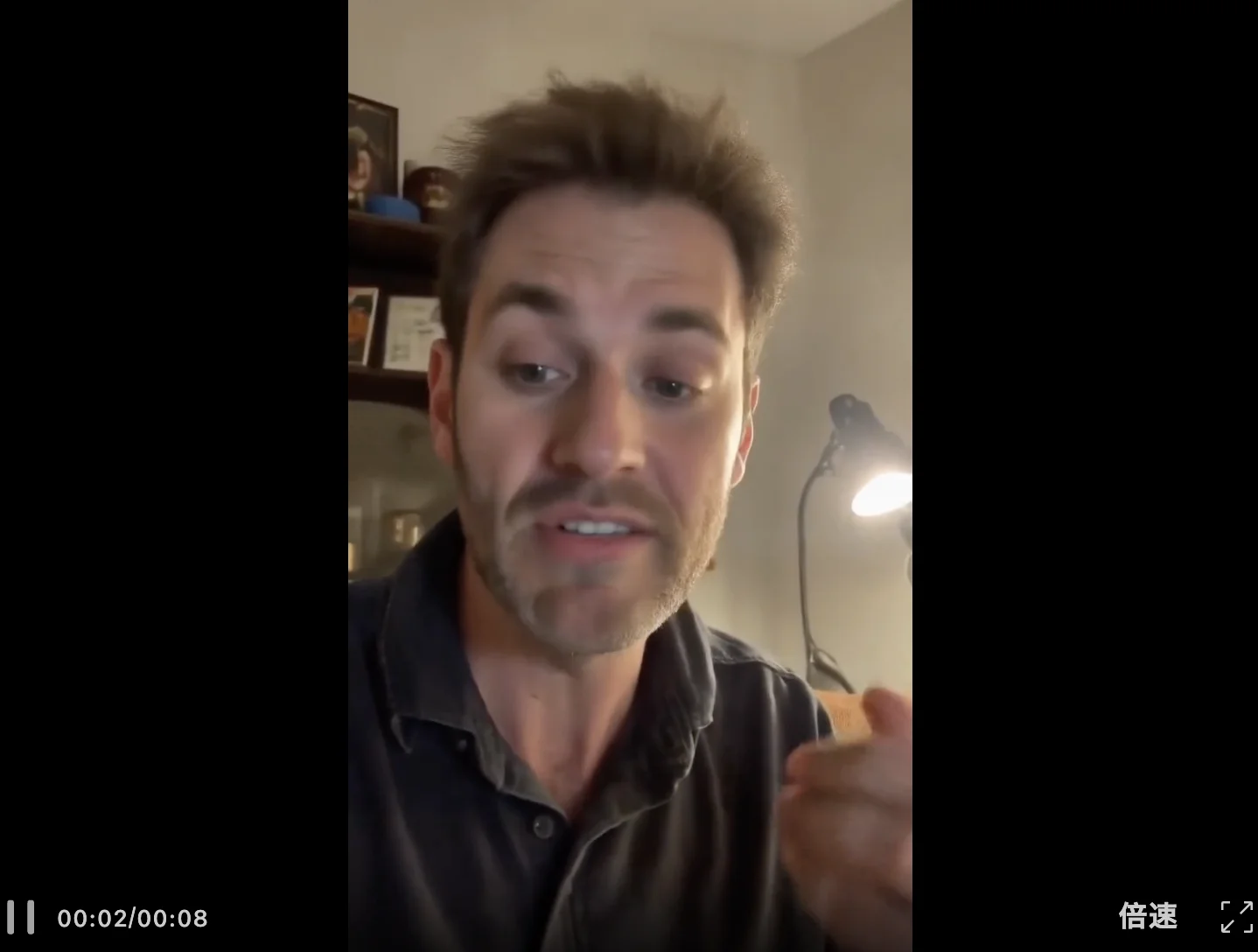
此外,MaineCoon的推理速度也很突出——
22B参数的大小,却能在单张H100上跑出47.5 FPS,同赛道速度位居业界第一;即使是在只有H100一半成本的推理卡RTX Pro 6000上,也能稳定保持30 FPS以上的实时运行速度。
具体什么概念呢?
假设我手里有一张GPU,用MaineCoon生成一条10秒的短视频,⾸帧将在3s以内出现,随后开始流式输出,新增prompt与实时输出无缝衔接,全程过渡丝滑自然。
成本直接被打下来,每秒成本控制在0.001美元以内。
如果在GPU占满的状态下,每秒推理更是仅需0.00025美元,是Veo 3的1/2000、Seedance的1/560。

而这些,来自一家base中国的10人初创团队,名叫Catnip(猫薄荷)。
几天前,他们刚刚在𝕏上发布了技术报告,就迅速收获多方关注,其中LTX官⽅也注意到了这家新面孔,并主动寻求合作。
话不多说,来看具体效果。
效果show time
其实MaineCoon和一般的音视频生成模型还不太一样,它首次将场景垂直落地在社交交互中。
何为社交?就是活人感。
且看各家现有的生成模型卷到飞起,Benchmark表现一个赛一个亮眼,但依旧有硬伤:
要么速度太慢,要等完整生成后才能看到效果,根本没法实时,对创作者并不友好;要么做得了视频,却顾不上音频,音画永远分开走。
这类通用音视频模型更擅长模拟物理规律和场景叙事,天空中的云怎么飘、水面的光怎么反射,它们拿捏得很准,但一到人物表现上就屡屡翻车。
于是判断AI视频与否,大家总结出一条心照不宣的经验——看脸。
要做社交距离也不露怯的视频,关键在于人物细节是不是够自然,比如眼神的变化、嘴角的抽搐、说话的节奏等等,还要音画高度同步、生成过程中随时可切换指令。
难度系数拉满了,但这些细节才是决定活人感的关键。
所以MaineCoon瞄准的,正是这个被整个行业忽视掉的缺口。
具体来说,它做到了三件此前没有模型能同时做到的事。
音视频流式生成
先科普一下,什么是流式生成?
这并非新鲜概念,最早ChatGPT一个字一个字往外蹦,就是流式输出。简单来说,就是让模型能够边看边生,推理到哪儿,就生成到哪儿。
但视频的一帧涉及到成千上万个像素,还要和音频在时间轴上精准对齐,和单纯文字流式生成的难度完全不在同一个量级上。
而且生成片段越小,就意味着每一帧能依赖的历史上下文越短,模型就更容易露馅。
MaineCoon则把这个单元极致压缩到了亚秒级,指令输出后1秒内就出首帧,低延迟和高质量两手抓。不止快了一点,更是生成方式的彻底改变。
比如下面模拟人物对话,初始Prompt要求人物语气平静且深思熟虑,结果无论是角色的面部肌肉走向,还是语气停顿,都精准遵循指令。
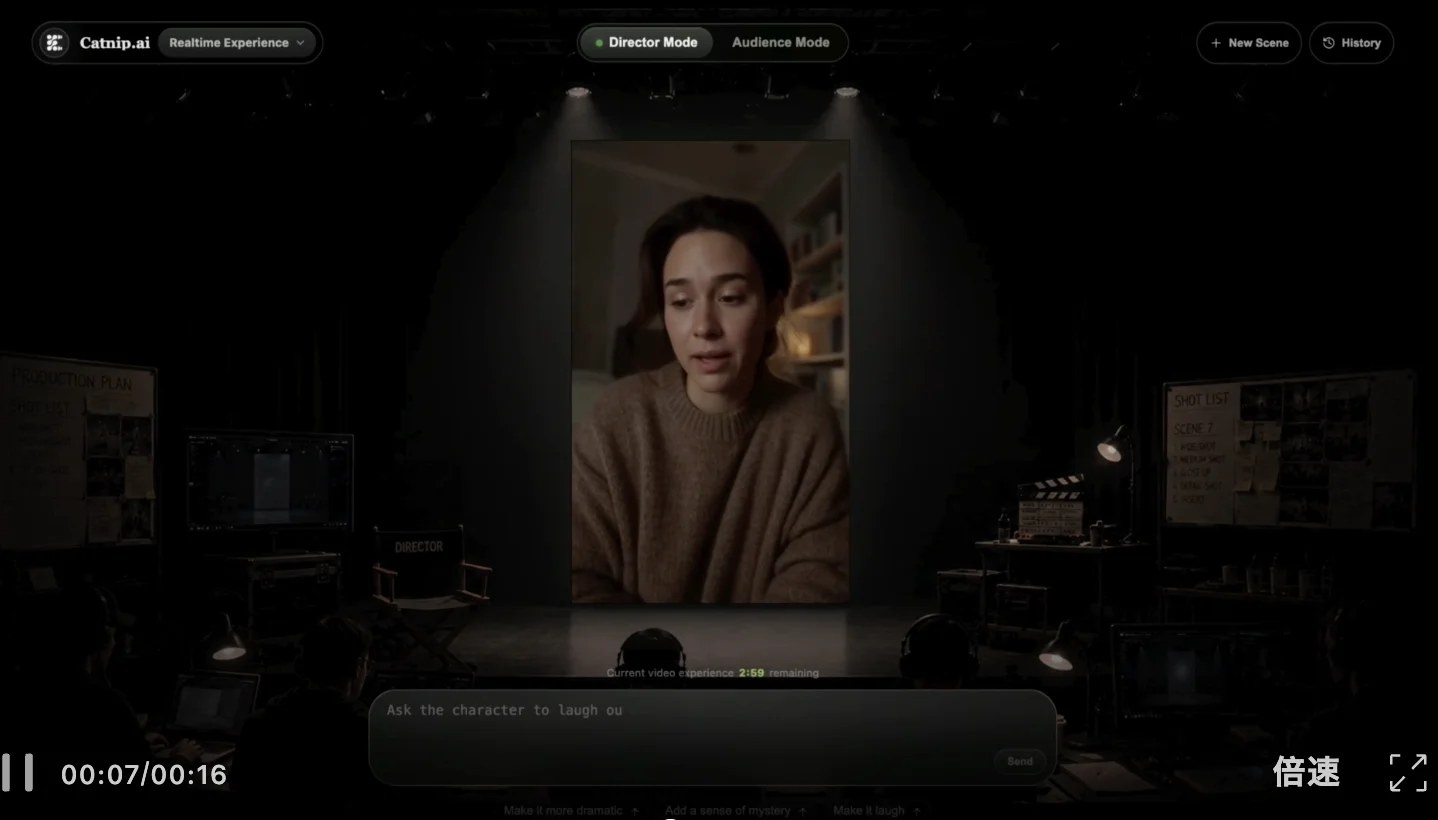
中间实时输入新的指令,模型也能及时调整:
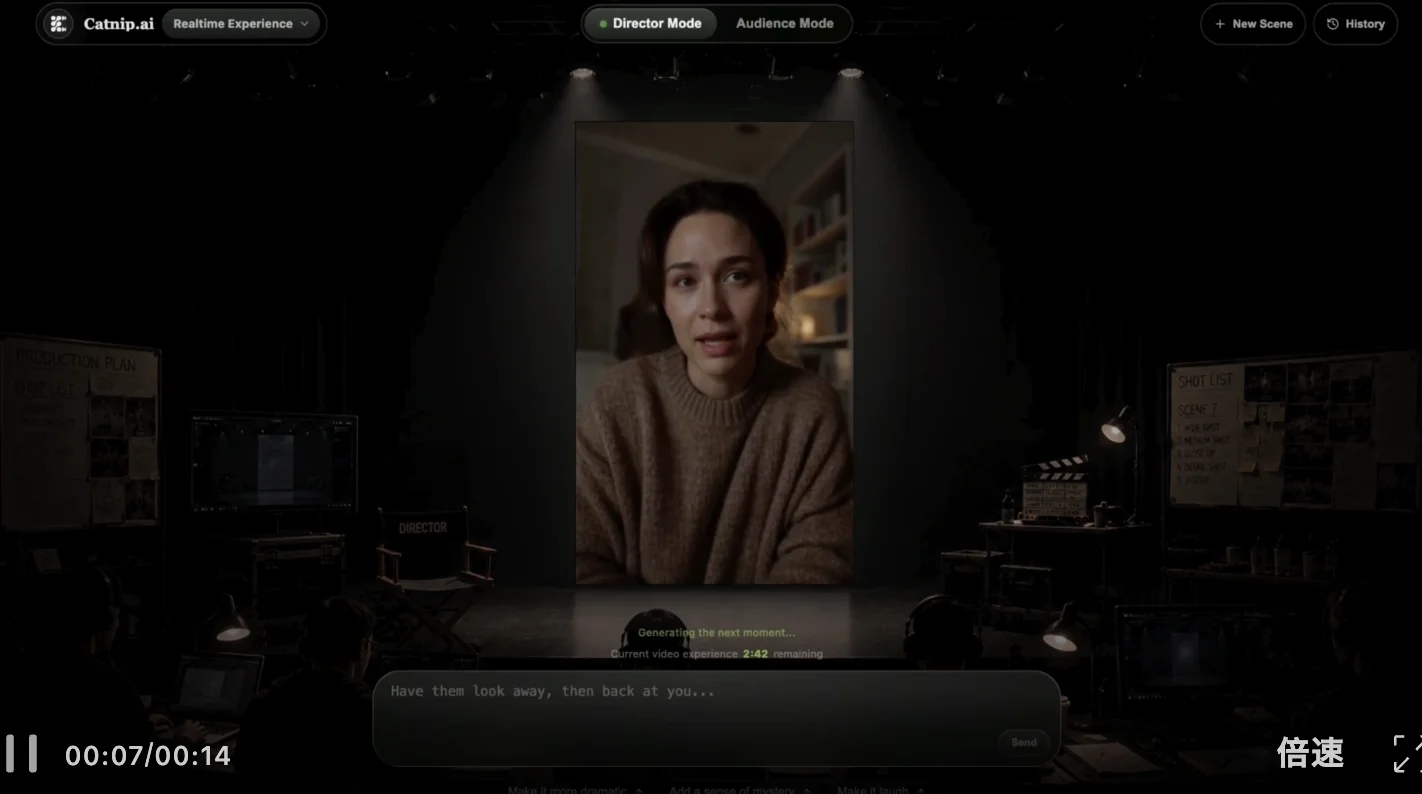
让角色做大幅度表情,也同样表现优秀:
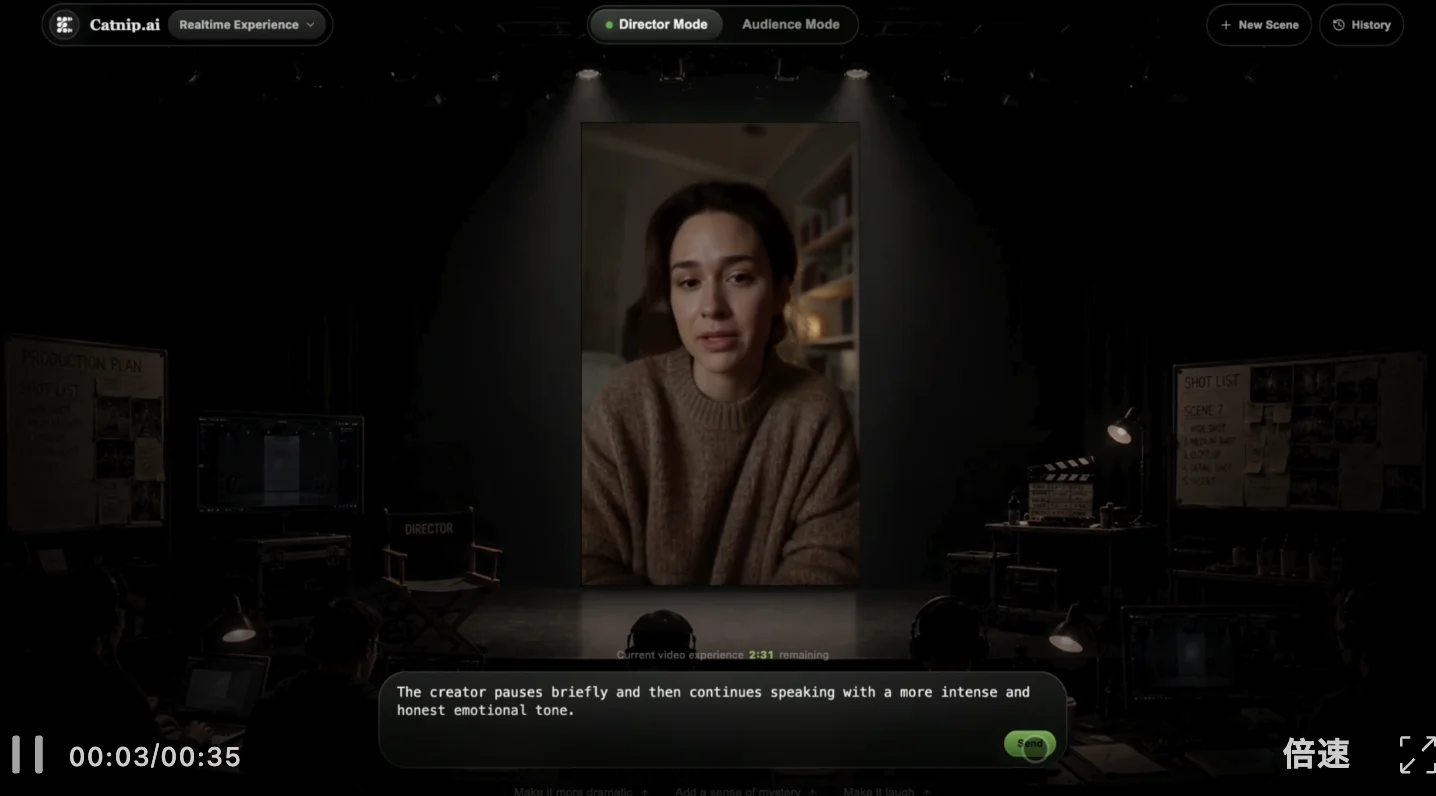
也可以随时提出问题让角色解答:
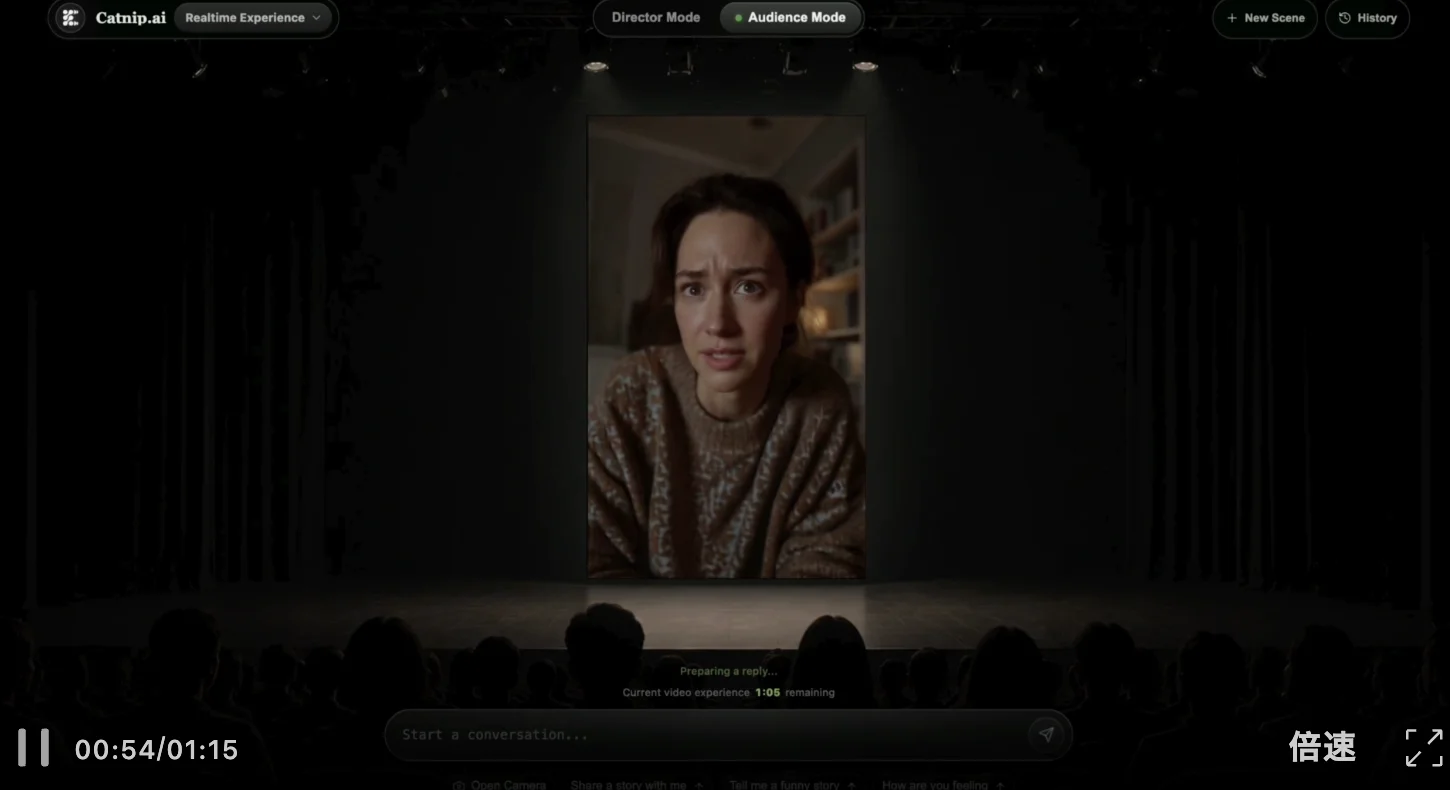
不得不说,相比过去AI一句指令就出一堆回复的生硬别扭,MaineCoon的最大差异在于给予用户真人聊天的即视感,会接用户的话,也会给用户情绪。
这大概就是养猫人常说的——你以为你在撸猫,其实猫也在撸你。
业界最快的推理速度
速度更不必多说,亲测体验下来,同类流式音视频模型的速度普遍在6-7 FPS,MaineCoon快了整整7倍。
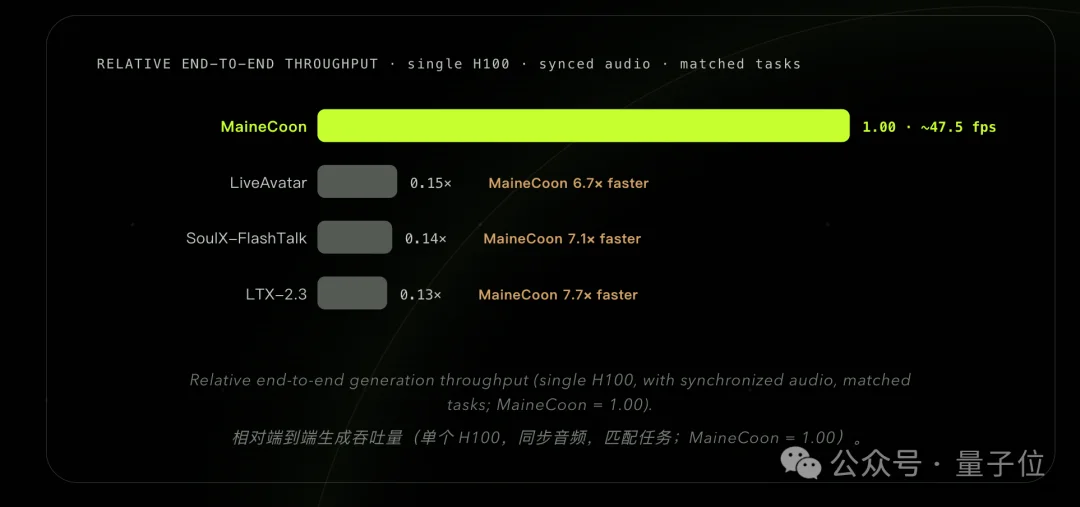
即使是持续生成一整天,成本也都能维持在一个合理范畴内。模型虽然有22B,但单卡就能部署(最高47.5 FPS)。
相比1.3B的轻量流式视频模型(19.1FPS)也要快2倍以上,轻松满足实时播放需求。
更关键的是,这样的速度不仅没有牺牲质量,反而情感表达更丰富,动作也更连贯稳定。
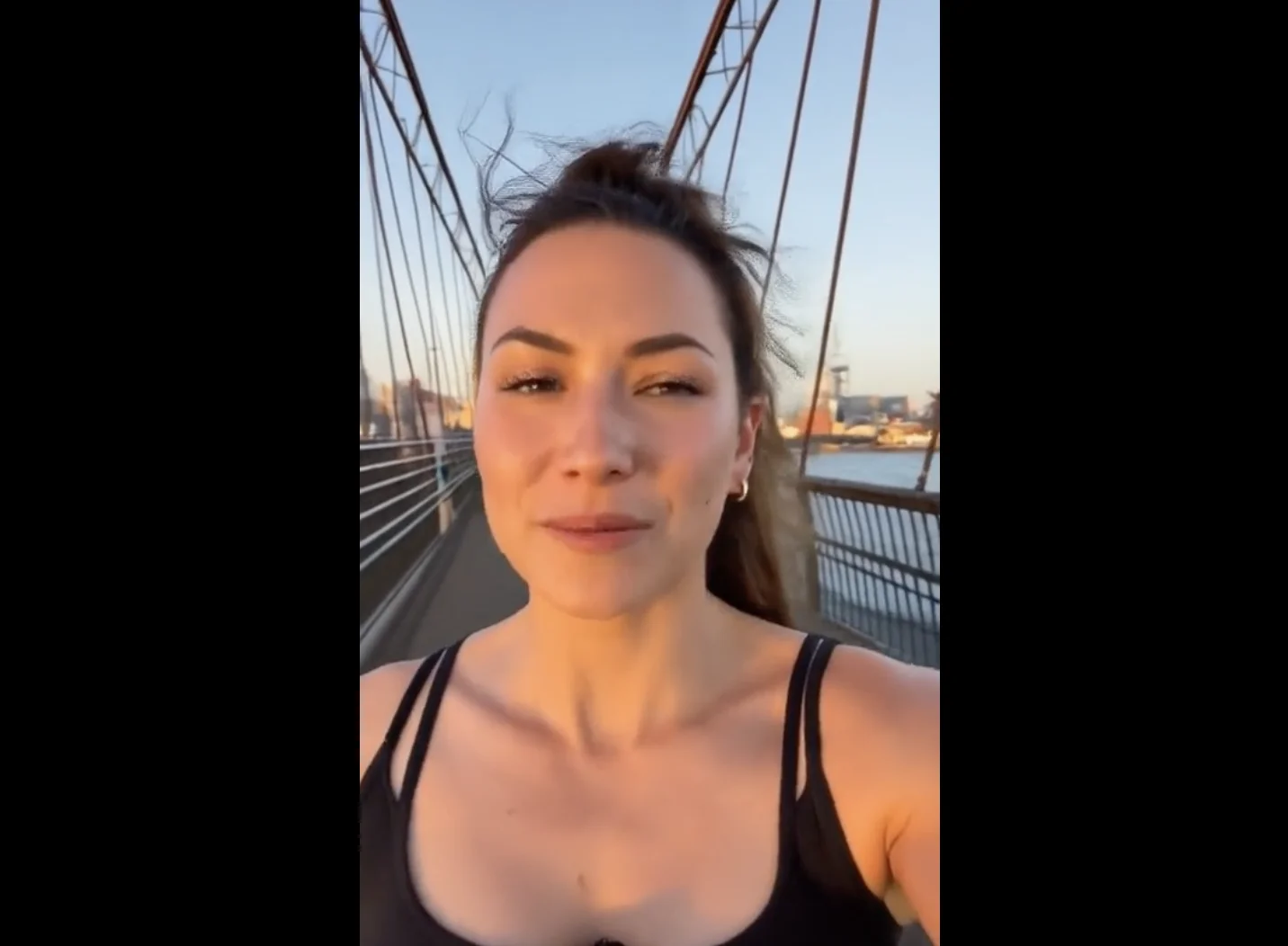
比如我们把场景搬到室外,日落时分的光影结合角色随风飘扬的发丝,说是真人博主在随意记录自己的City Walk也不为过。
无限时长生成
根据官方介绍,MaineCoon还能做到连续生成10分钟以上的音视频内容,期间保持画质、一致性、音画同步都不崩。
毫不夸张地说,MaineCoon的架构甚至完全可以无限生成。
这里以一个长达2分钟的MaineCoon视频为例,直到最后,人物都没有出现明显bug。
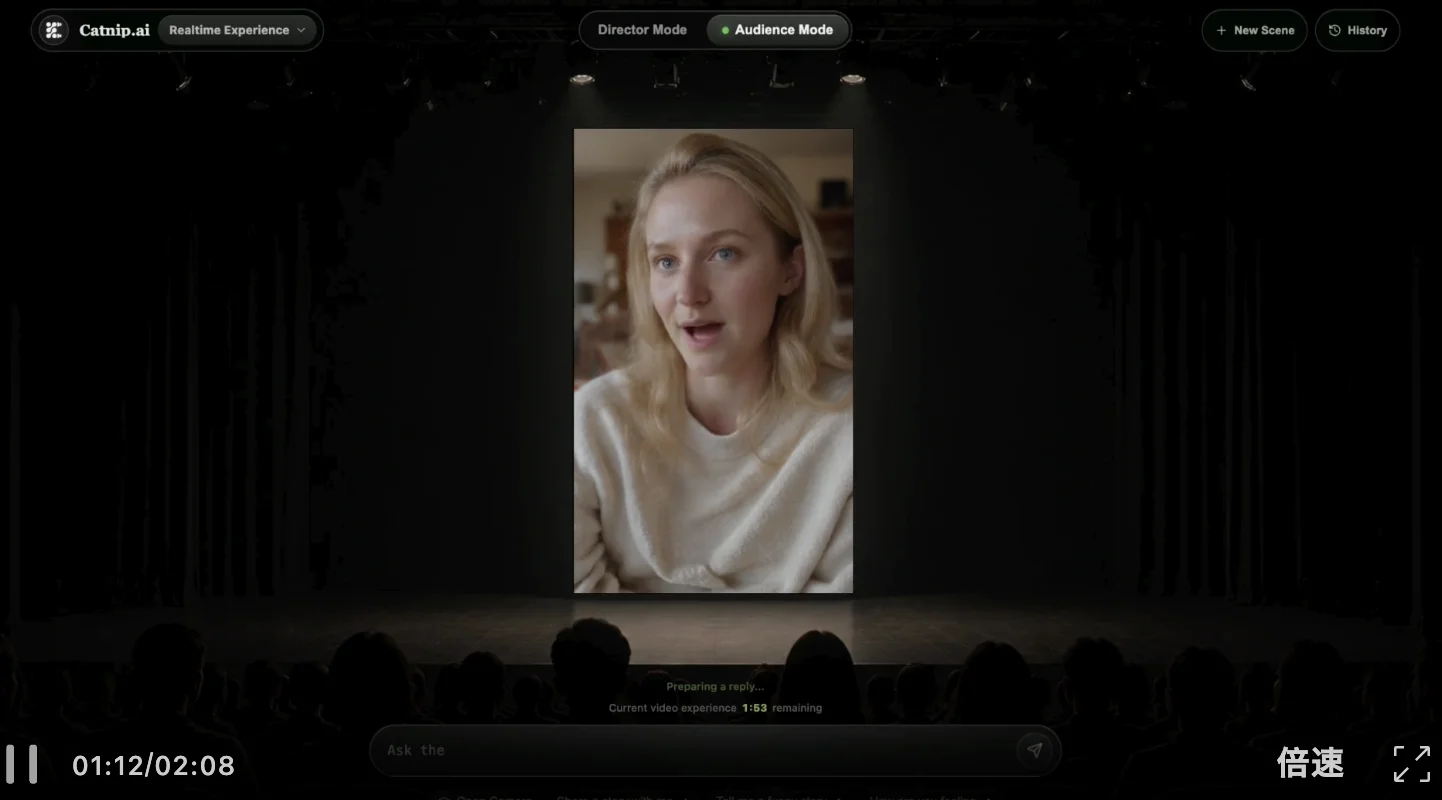
即使是动画风格的Minecraft小人,长时序也能稳稳接住。
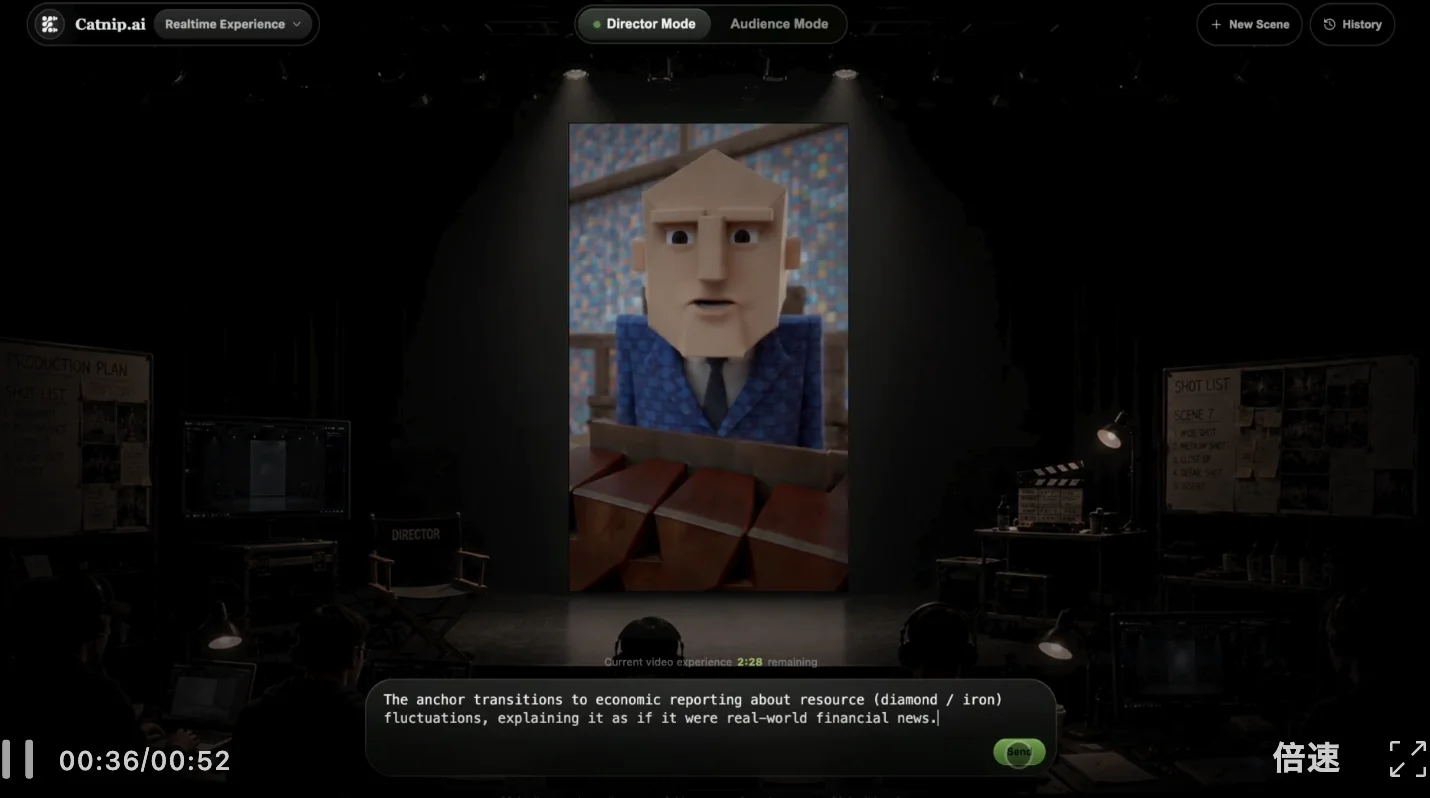
Catnip还同步自建了首个社交短视频专用基准测试SocialVideo Bench,以直观展示MaineCoon的表现。
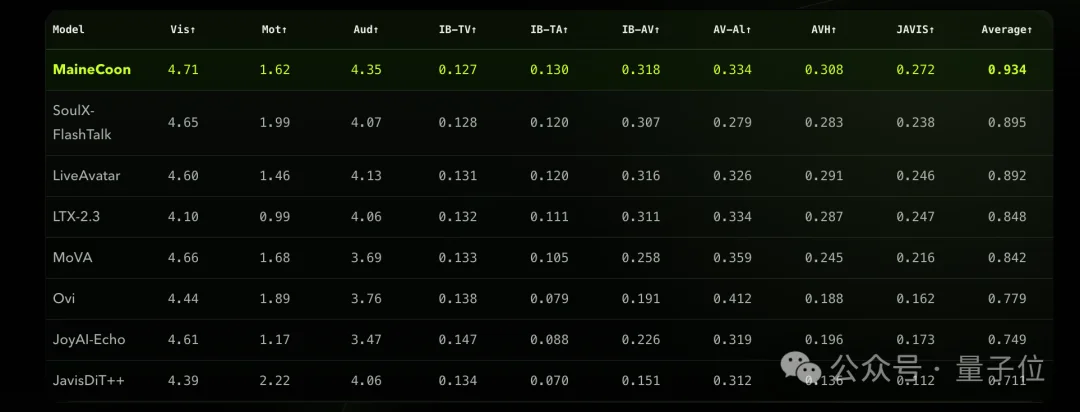
SocialVideo Bench涵盖密集演讲、双人互动、音乐演唱、情绪表演、舞蹈、创意挑战、社交梗七大场景,九项指标全面考核视觉质量、运动质量、音质、音画对齐。
其中,MaineCoon均超越主流的7款音视频生成模型,综合得分0.934,远超最优基线SoulX-FlashTalk(0.895),刷新SOTA。
问题是——MaineCoon是如何做到的?
三层训练,三层推理
先说训练侧。
MaineCoon的训练框架主要分三个阶段,层层递进:
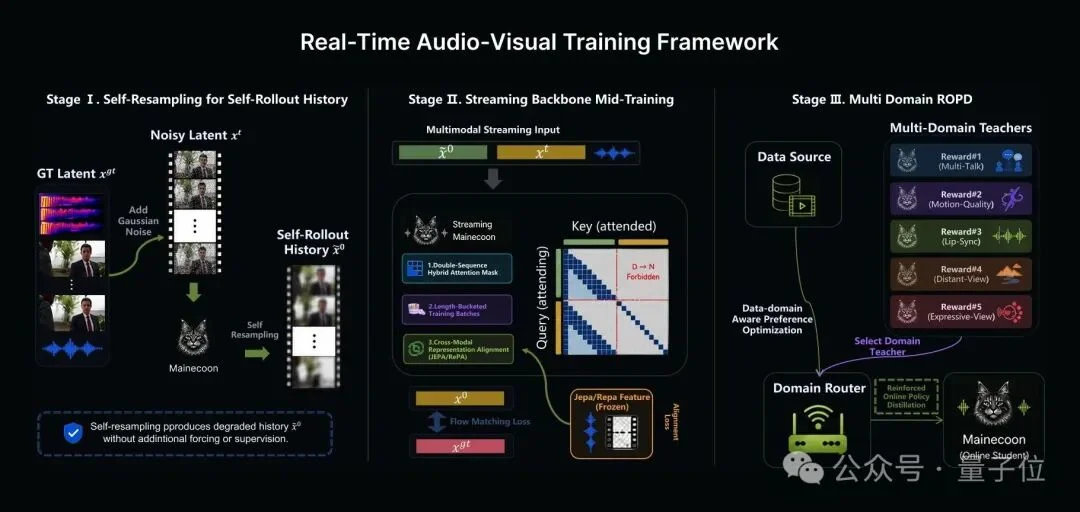
Step 1:自重采样(Self-Resampling)
这一步解决的是推训之间的鸿沟问题。传统训练中会用干净的历史帧做上下文,但真实推理时模型只能用自己生成的帧,二者之间存在偏差,而且时间一久,越生成越跑偏。
自重采样能够让模型在训练时就接触到降质版的历史帧,从一开始就学会在带有轻微漂移、噪声的不完美条件下保持稳定。
Step 2:流式表征对齐(Representation Alignment)
音画联合训练实际上是很慢的,为了加快收敛速度,MaineCoon会引入冻结预训练V-JEPA 2视觉编码器做蒸馏监督。
于是模型能够更快学到跨模态的语义结构,大幅提升训练效率,也可以简单将其理解为一个训练加速器和稳定器。
Step 3:域感知偏好优化(DPO)+强化在线策略蒸馏(ROPD)
这是模型的后训练核心,针对不同社交场景,比如舞蹈看重动态、对话看重唇同步、远景看重人体结构,分别训练专门的偏好专家模型,再通过强化蒸馏统一成一个可部署的流式策略。
这样既精准,又轻量。
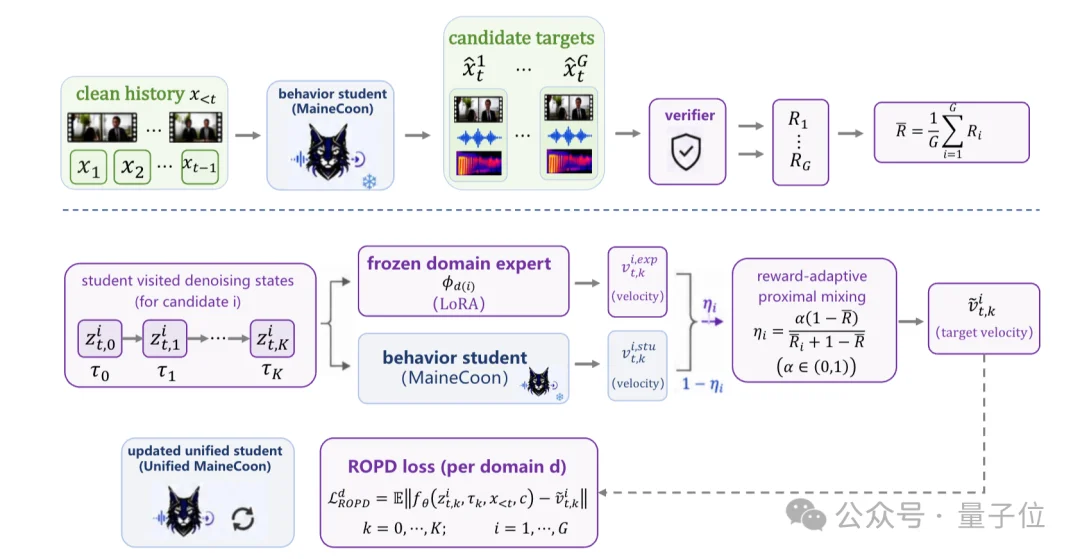
然后在此基础之上,要让模型在有限的算力资源上真正跑起来,团队还精心设计了一套基础设施工程。
毕竟22B模型的参数量太大,不处理,一张卡根本装不下。
具体来说,64张H100分摊参数,长序列切开并行处理,精度和优化器状态则能压则压。
最关键的一步是把视频编码、文本嵌入、教师特征全部提前算好存进磁盘,训练时直接读取,而GPU只做最核心的那一步,不做任何多余的搬砖工作。
结果就是,22B的模型,在10k GPU小时内就训练完成,数据一共不到100万条。
推理侧同样有一套创新的Agentic推理框架,该框架由三个独立的智能控制器构成,分别是Director、Cache Manager和Buffer Controller。
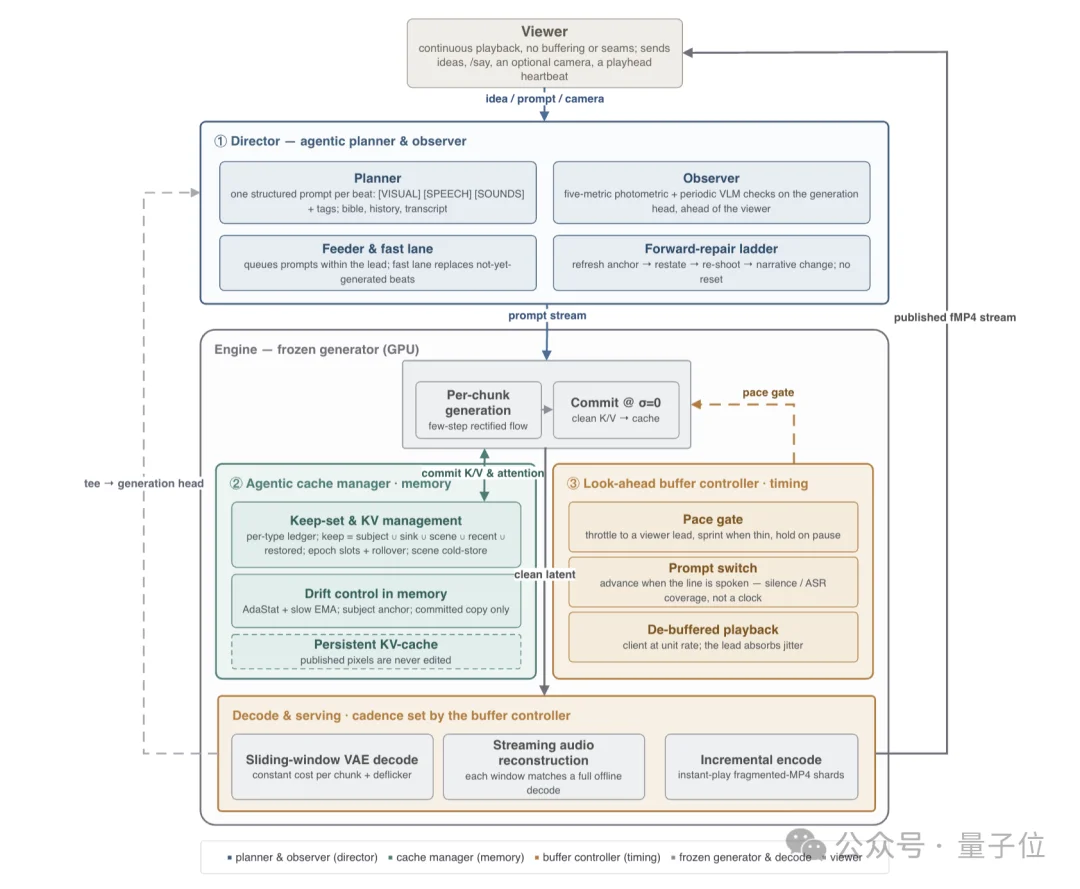
首先是Director,这也是整个系统的认知核心,专门负责叙事与纠错。
Director先通过规划器逐节拍生成结构化提示词(画面描述+台词+环境音),以维持人物人设、避免叙事重复。
然后观测器持续监测生成内容是否出现质量漂移,一旦发现问题就启动前向修复,不中断、不重置,直接在下一帧开始纠偏。
这样做是为了缓解流式长视频最容易出现的问题之一:畸变。
生成时间越长,误差累积就越严重,因为模型在生成当前chunk时,参考的是前一个chunk,但殊不知前一个chunk已经相对第1个chunk偏移了。之后每一步的微小偏差叠加起来,人物就会严重畸变。
所以MaineCoon从推理的第一步起,就试图将偏差遏制在摇篮中。
随后观测器会将观测结果返回给Director,主导记忆的缓存管理器通过拿到Director的输出,开始执行管理KV缓存的保留与清除策略,它会将角色外观、场景建立帧、关键对话帧作为长期记忆锚点保留,同时定期用统计锚点修正全局外观漂移。
同时因为MaineCoon生成速度快于播放速度,会自然积累起一段已生成但未播放的缓冲内容。
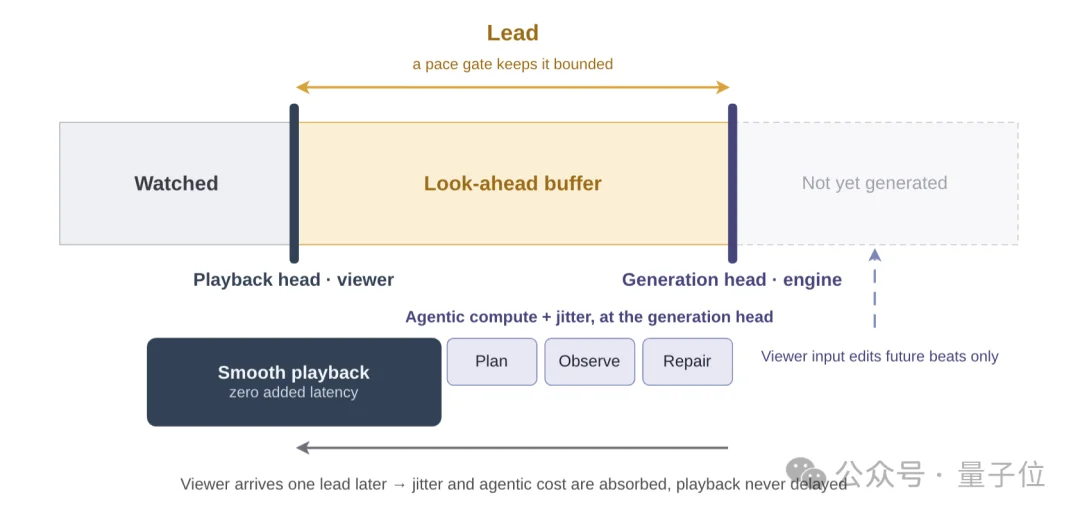
为了平衡实时性与交互响应,前瞻缓冲区控制器会负责把这段超前量控制在合理窗口内,既保证播放不卡顿,又保证用户的交互指令能在合理延迟内生效。
简单来说,这部分就是一个写剧本、一个管记忆、一个控节奏——三者分工明确、互不干扰,共同支撑起了无限续流。
但这还不是全部。
下一步是社交世界模型
MaineCoon甚至还只是Catnip的起点。
他们真正的野心,藏在MaineCoon的定位上——社交世界模型。
这个概念由Catnip独家首次提出,旨在弥补一段行业内长期视而不见的空白:
现有的视频世界模型,无论做得多么精密,本质都还是在模拟物理世界。它们重视苹果如何垂直落地,车辆如何克服摩擦力运动,而人在其中扮演的角色更像是一种会动的物体,辅助场景完成画面。
社交世界模型要做的恰恰相反。
它直接把人当作坐标系的中心,主动观察用户的情绪状态,以人为原点模拟社交行为的走向,然后利用实时音视频的方式做出合理反应。
团队认为其包含三个层面:感知层(读懂用户情绪)→ 模拟层(预测社交行为)→ 渲染层(实时生成音视频)。MaineCoon正是第三层的突破。
选择渲染这一层作为首要切入点,一方面是因为渲染层是最难,但也是整个系统的最终出口,如果没有实时生成能力,前两层再强也没有用武之地。
另一方面,业界始终缺乏一个推理快、成本低、质量高的流式音视频模型,先做这个,也是从商业角度考虑的最优解。
再往后看,下一步就是摆脱传统AI对话的半双工轮流交互模式,实现人类式连续、交错、多模态的实时双向交互。
也就是AI能一边持续生成,一边感知用户的实时反馈(包括文本、语音、视频),像真人对话一样即时调整。
而当这一层被彻底打通,模型和应用层之间的闭环才真正形成。Catnip也在积极推进将其落地为一个可交互的内容平台,支持海量用户实时感应、实时生成。

至于为什么Catnip能率先意识到这一点,我们可以从这支团队入手。
有趣的是,缅因猫这个品种一开始也是工作猫起家,专职捕鼠、保粮仓,基因里自带实用主义。
这与Catnip给人的印象不谋而合——
成立大半年,没有任何公开露面,相当低调,日常就是专注埋头干活,唯一对外的动作就是这次把技术报告挂上arxiv。
不鸣则已,一鸣惊人。
但即便在水下,这支团队也已经被最具洞察的投资人抢着押注。
开年这几个月,就连续收获了红杉、明势等头部VC的天使轮+融资,不仅因为团队是一群00后青春风暴,还罕见拥有一线实战经验,既懂技术又懂商业。
创始人杨姝瑞虽然很年轻,但曾在TikTok和PixVerse做产品,推动过多款爆款模版特效从0-1落地。除此之外,杨姝瑞也是连续创业者,第⼀段创业合伙创办海外社媒营销agency VANZO MEDIA,实现了千万年度营收。
主导算法研发的是⾸席科学家、⾹港科技⼤学(⼴州)助理教授谢泽柯,拥有中科⼤本科、东京⼤学博⼠教育背景,曾在百度研究院参与⼤模型的前沿研究,并⻓期担任NeurIPS、ICLR、ICML等AI顶级会议的领域主席。
另外,团队还有一群02/03年的应届生小伙伴,在极具创造力地工作。
且看MaineCoon的研发过程,据官方介绍,项目正式启动是从今年3月开始,3名核心研究员,只用了2个月时间就完成了模型训练、训练架构、数据基建、推理系统的全栈交付。
方法也很激进,直接全程使用AI Native:人定框架和思路,AI执行具体计划;人搭数据infra,AI跑流水线。
但正是这样的打法,最终效果惊艳,成果说话——MaineCoon火了。
其实用团队的话来说,MaineCoon更像是一只时刻感知用户内心状态的真正的猫。
当生成式AI正在从被动内容工具走向社交主动参与者,作为能感知、回应和记住用户的AI存在,它承载着人类共同的情感交互需求。
MaineCoon是这个方向上踏出的第一步,而且更重要的是它映射出的信号:
下一代社交平台的底层引擎,已经被按下了开始。
文章来自于微信公众号 “量子位”,作者 “量子位”
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


