深度长文分析!对AI原生游戏的探索!超长文章超多古法手搓!!

AI从"会答"走向"会协作"
先从开发侧正在发生的一个变化说起。
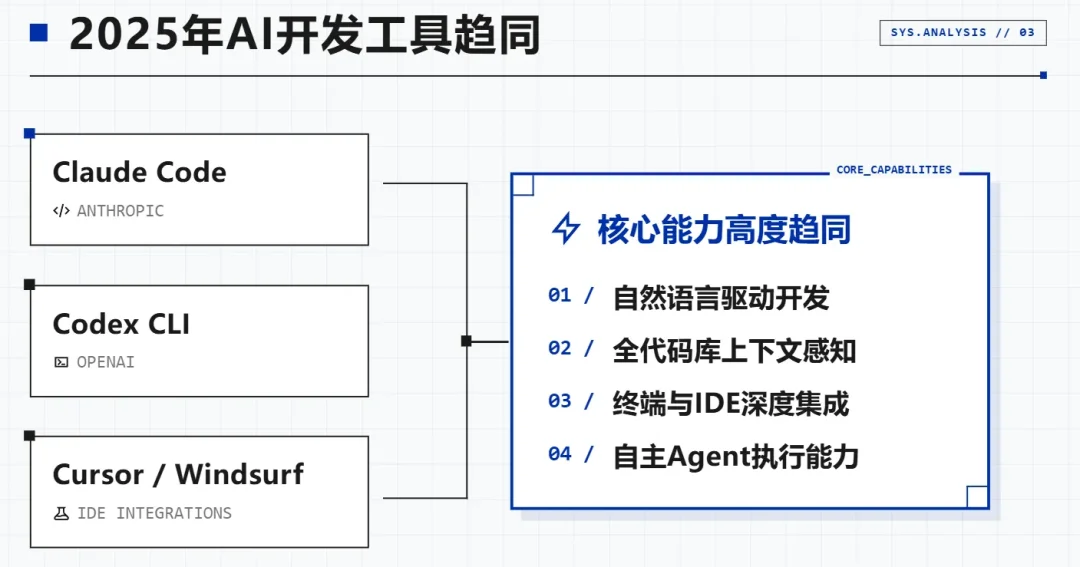
2025年出来的这一批AI开发工具,Claude Code、Codex CLI、CodeBuddy,名字不同,出处各异,但核心能力高度趋同——能读懂你的代码库,能真的动手改代码、跑命令,理解你的一句话需求。 不只是给建议,是真的在替你干活。
这些工具放在一起,说明的是同一件事:AI正在从"会答"走向"会做",再走向"会协作"。以前AI像一个聪明的顾问,现在更像一个初级同事。这个变化,比"回答更准确"重要得多。
从开发侧到运行时
讲完这些工具,我其实一直有个问题:
如果AI在开发侧已经能理解意图、读上下文、分步执行、调工具实操,那它为什么只能帮我们做游戏?它能不能进入游戏运行时本身?
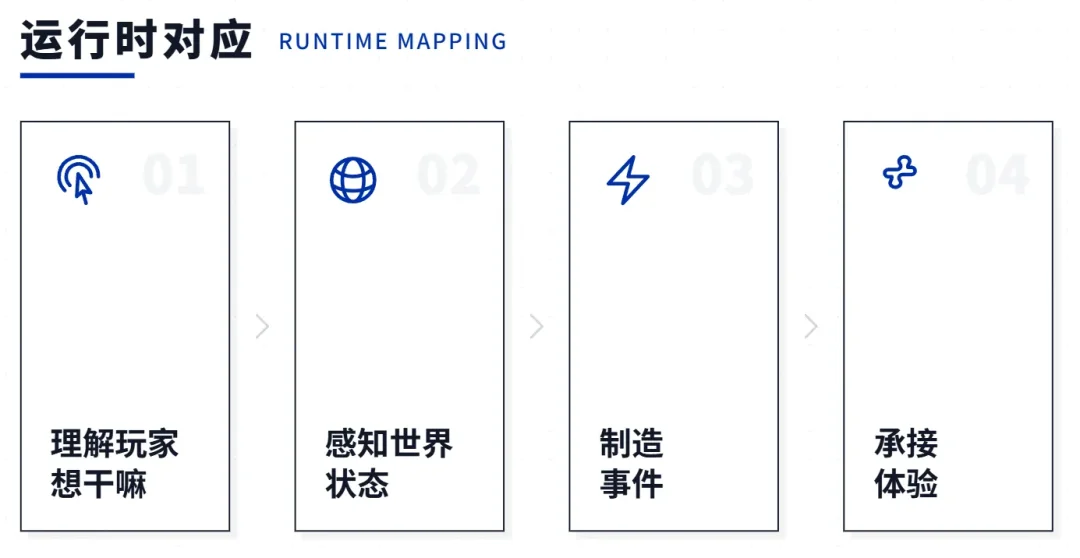
这些能力放到运行时里其实都有对应的事可以干——理解玩家想干嘛、知道世界现在什么状态、推动体验往前走、在合适的时候制造事件、下次玩家回来还能承接。
但其实并不好搬。
开发侧的东西有明确边界,测试过了就是过了,文件写了就是写了。 运行时全是模糊的:什么叫"体验好了"?
同一个事件不同人感受完全不一样。所以AI进运行时,中间必须加一层架构来兜住这些模糊性。
所以我今天想聊的其实不是AI怎么帮我们做游戏,而是AI能不能直接参与到游戏运行时里面去。
现有产品的困境
这两年AI角色扮演产品出了不少,SillyTavern、Character.AI、星野、Fables……在座可能有人玩过,至少听过。
每次刚开始玩都觉得"哇,好厉害"。但真的玩久了,几个小时之后,你会发现一个共通的问题:越玩越怪,越玩越没意思。
3.1 酒馆和Character.AI分别走到了哪
先说SillyTavern,也就是"酒馆"。
开源社区里最成熟的AI角色扮演前端。世界书的关键词触发越来越精细,加了RAG向量检索,社区还做了结构化记忆插件。但不管技术做得多精细,它的工作方式始终是一个: 在一个可能不是很恰当的时机把恰当的文本塞进提示词。没有一个独立的逻辑层在说 "现在该升压了"、"玩家快无聊了"。
而且用户得频繁手动干预——回溯、重说、手动编辑记忆。这不像在玩游戏,更像在调试AI。
Character.AI呢,2025年记忆系统做了好几轮升级,能自动提取对话里的关键信息了。
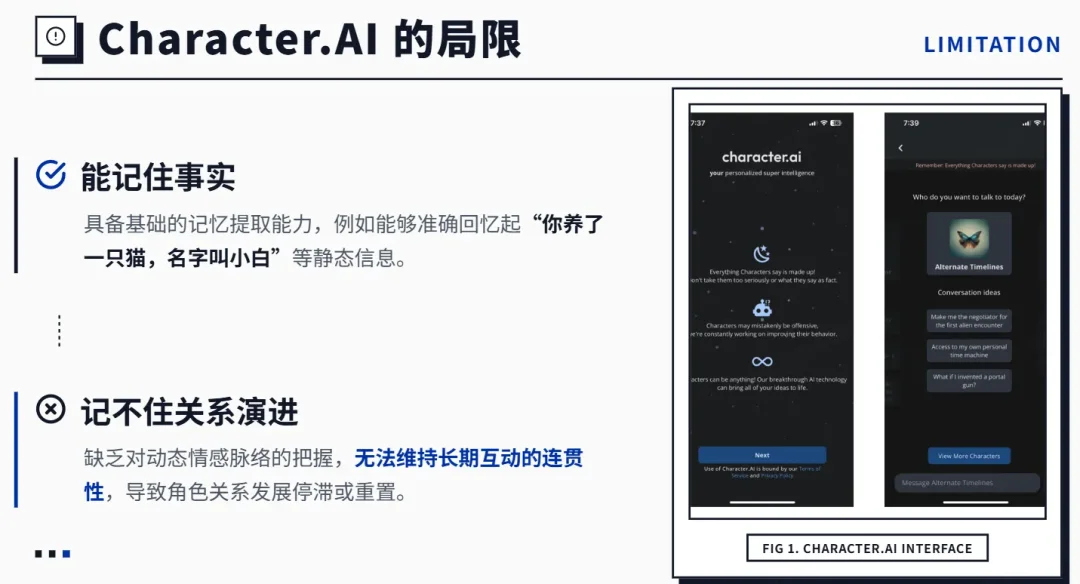
但它能记住"你有一只叫小黑的猫",记不住"你们从互相防备到彼此信任的过程"。后者才是长期角色扮演真正有价值的东西。 而且AI角色太顺从了——模型倾向于取悦用户,玩久了就是无意义的循环和复读。不是不聪明,是太听话了,听话到没有冲突、没有意外、没有惊喜。
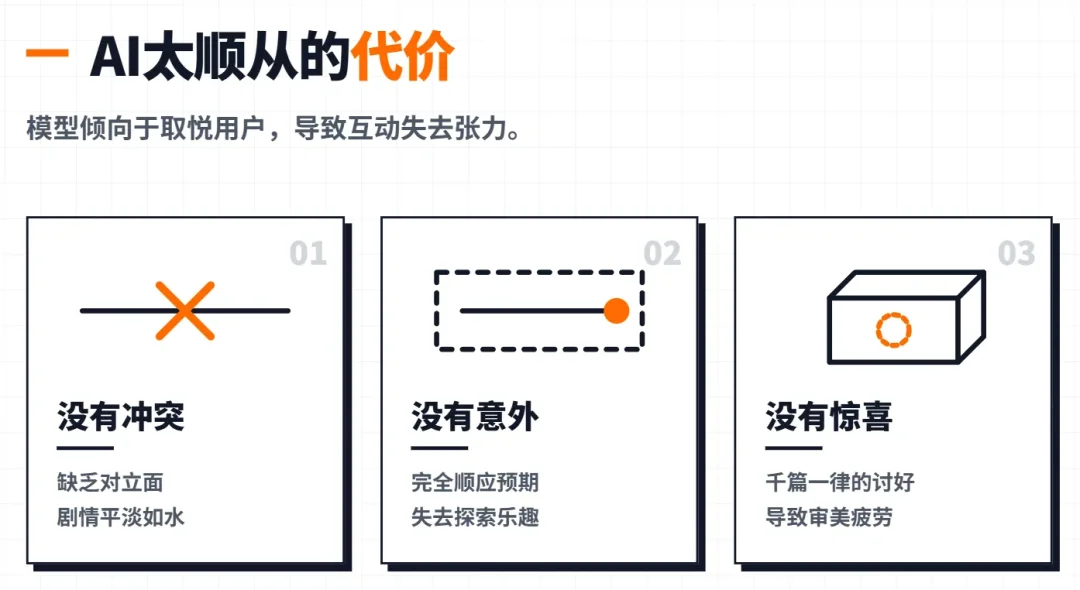
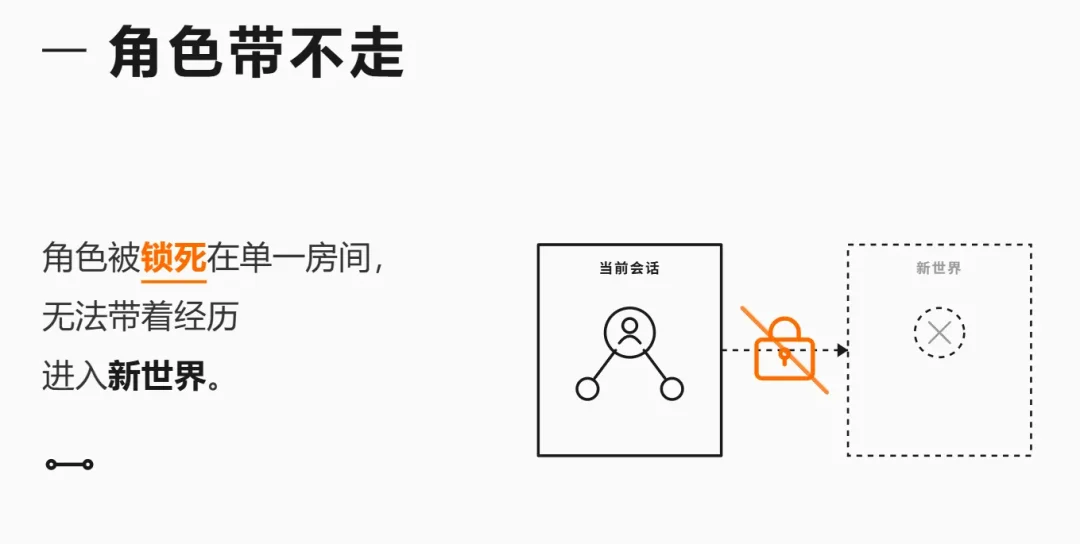
还有一个共同的问题:角色带不走。你跟一个角色聊了100轮,想把他连同经历和关系带到另一个世界观里? 做不到,角色卡只有初始设定。
3.2 问题出在哪
这些产品都在疯狂优化"对话质量"——更长的上下文、更好的记忆、更拟人的回复。 但它们缺的不是对话能力,而是对话之上的东西。
对话是媒介,并非体验本身。

你让模型更大、上下文更长、回复更拟人,这些都是好的改进。但它们解决不了一个根本问题:剧情还是会原地打转,世界还是没有真正的变化。
玩家跟角色聊了50轮,关系演进甚至会逐渐遗忘,做过的选择重新再roll一遍可能会让整个世界都变样...
这些问题其实不止在对话层,在对话之上。
传统游戏怎么解决这些问题的?状态机追踪世界状态,数值系统量化关系和资源,事件系统在合适时机推动剧情,导演逻辑调节难度和节奏。
这些东西,现在的AI角色扮演产品里几乎都没有,或者有一点点,但不成体系。
用游戏设计的话说,这些产品没有在维护玩家的心流。
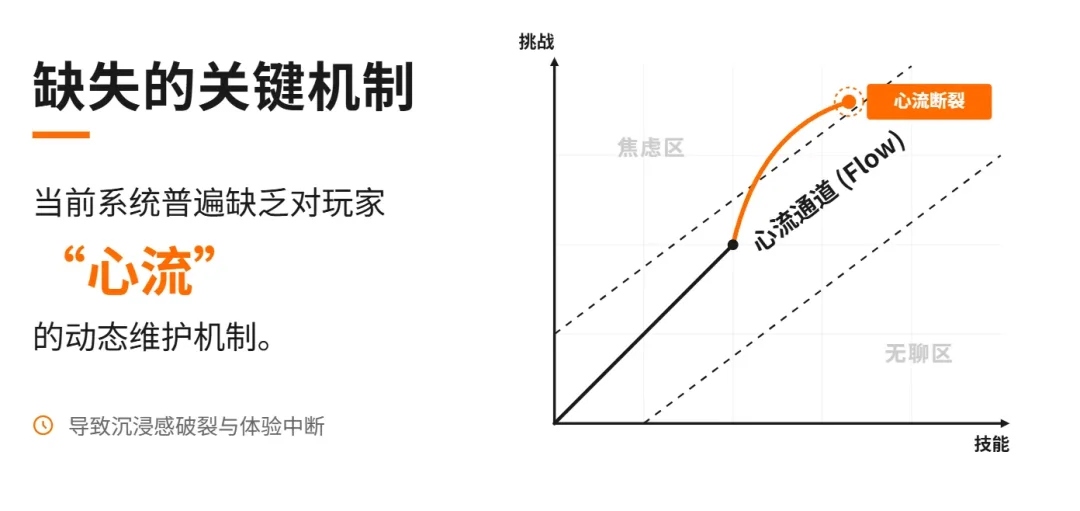
心流需要挑战和能力之间持续匹配——太简单无聊,太难焦虑,刚刚好才会沉浸。
传统游戏靠关卡设计和难度曲线来做这件事,AI角色扮演产品目前没有任何机制在管这个。
这就像让一个特别会说话的演员,同时兼任编剧、导演和场务。他再厉害,也扛不住。
所以我今天核心观点其实就是:AI聊天对话类产品的聚焦点,就不该是对话体验,而是游戏体验。
让AI文笔更好、聊天更自然,那是大模型厂商的事。
应用层面该做的是用游戏化的思维去优化用户体验。
规则驱动的导演系统
4.1 先说行业背景
问题讲完了,说说我们的做法。
在导演系统这个观念上,游戏行业很早就做过类似的事。
2005年,Michael Mateas和Andrew Stern发布了Façade,可能是最早的AI驱动的交互戏剧游戏。

玩家通过自由打字与两个AI角色互动,而游戏背后有一个Drama Manager在实时编排叙事节奏。
它会根据玩家的行为判断当前的戏剧张力,决定接下来该推进哪一段剧情、该让角色做出什么反应。
这在2005年就说明"规则驱动的体验导演"是可行的方向。
2008年,Valve在《Left 4 Dead》里做了一个AI Director,用规则系统监控玩家的压力曲线,追踪团队的血量、弹药、最近受到的伤害频率。
然后动态调整僵尸生成密度、特殊敌人出现时机、物资投放位置。它用的正是规则加参数化调控,而不是AI决策。

近年来,LLM的出现让这个方向有了新的可能性。ACL上的一篇论文提出了"导演-演员"协作架构,一个前置的导演Agent负责可控的叙事引导,演员Agent负责角色表演。

从Façade到L4D一路走来,现在有了LLM,导演能调控的东西从参数升级到了体验。我们做的是在这条线上继续往前走,同时用规则来保证稳定性。
4.2 先澄清一个误解
当说到"导演系统"的时候,可能很多人第一反应是:让另一个AI来当导演?让GPT-5来指挥GPT-4?
并非如此。这里要讲的导演系统,不用LLM来做决策。
为什么?因为AI做单次判断可以很准,但做跨轮次的决策一致性不太行。
你让AI判断"现在该升压还是降压",它这一轮说"升压",下一轮同样的局面可能就说"降压"了。单次看都有道理,但连起来节奏就飘了。
不是不聪明,是它没法保证连续十轮的判断方向是一致的——而体验编排要的就是这种长程一致性。
对话层面,每次稍有不同没关系。但游戏的节奏曲线不能每次都随机漂移。
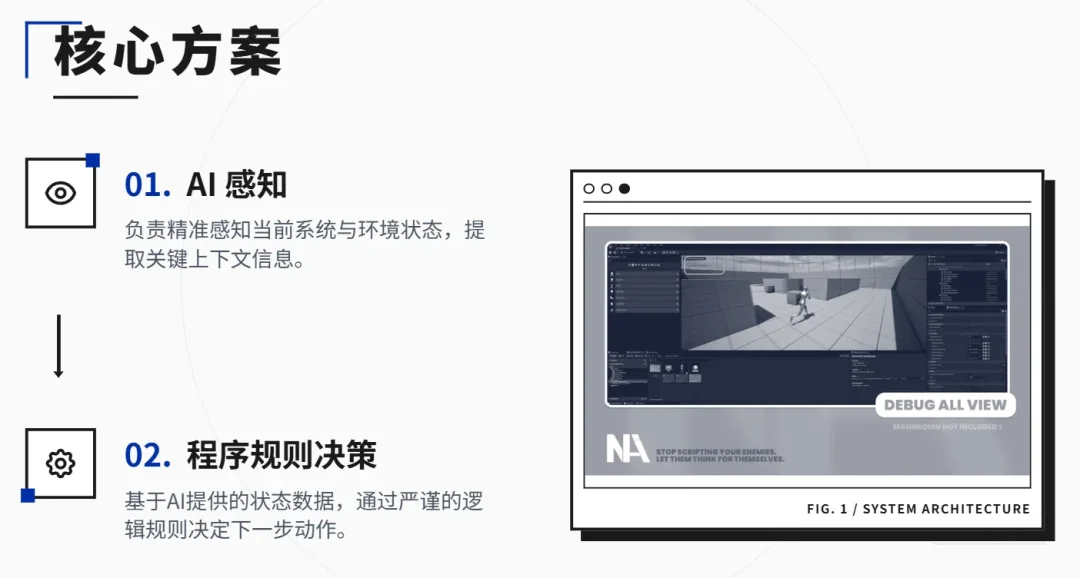
所以我们的方案是:AI负责感知,程序负责决策。模型每轮告诉系统"现在场上是什么情况",至于"接下来该怎么办",由程序规则来判断。
4.3 导演系统怎么工作
但导演要工作,得先能"看见"当前发生了什么。所以我们做了两件前置的事。
一个是把模型输出协议化。模型每轮不只输出给用户看的叙事文本,还通过 @@s这个隐藏通道回报结构化状态。
输出被拆成了"玩家看到的故事"和"系统拿到的状态"两层。
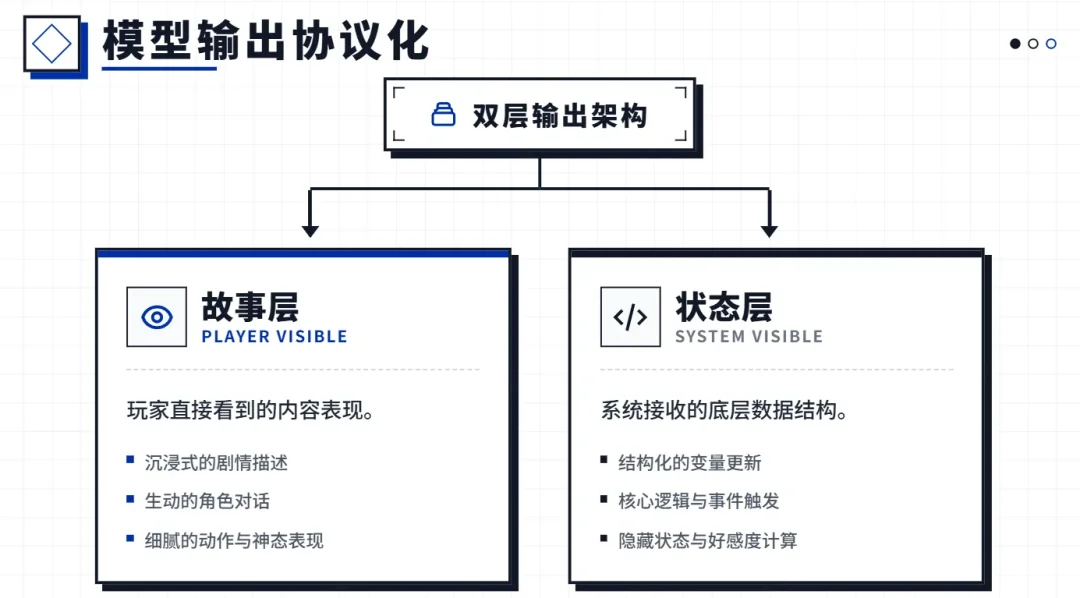
另一个是在聊天记录之外,维护一套独立的结构化运行态,包括当前场景、角色状态、隐藏信息、待触发事件这些东西。
这些状态不是摆设,导演系统每轮都在读它们。
有了这两层,导演才有数据可用。
接下来说导演拿到数据之后干什么。
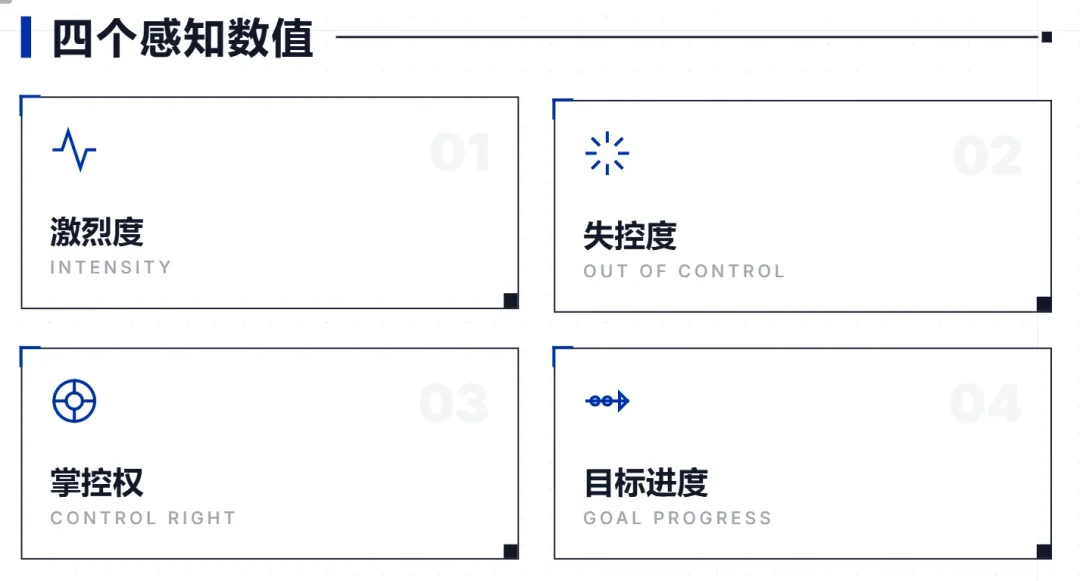
模型每轮除了写故事,还会通过隐藏通道回报四个数值:
当前场景有多激烈、局势离失控有多近、玩家对剧情走向的掌控权有多大、眼前的目标推进到什么程度了。
你可以把它理解成演员演完一场戏回来跟导演说:"刚才那场挺紧张的,主角快撑不住了,不过观众还觉得自己有的选。"
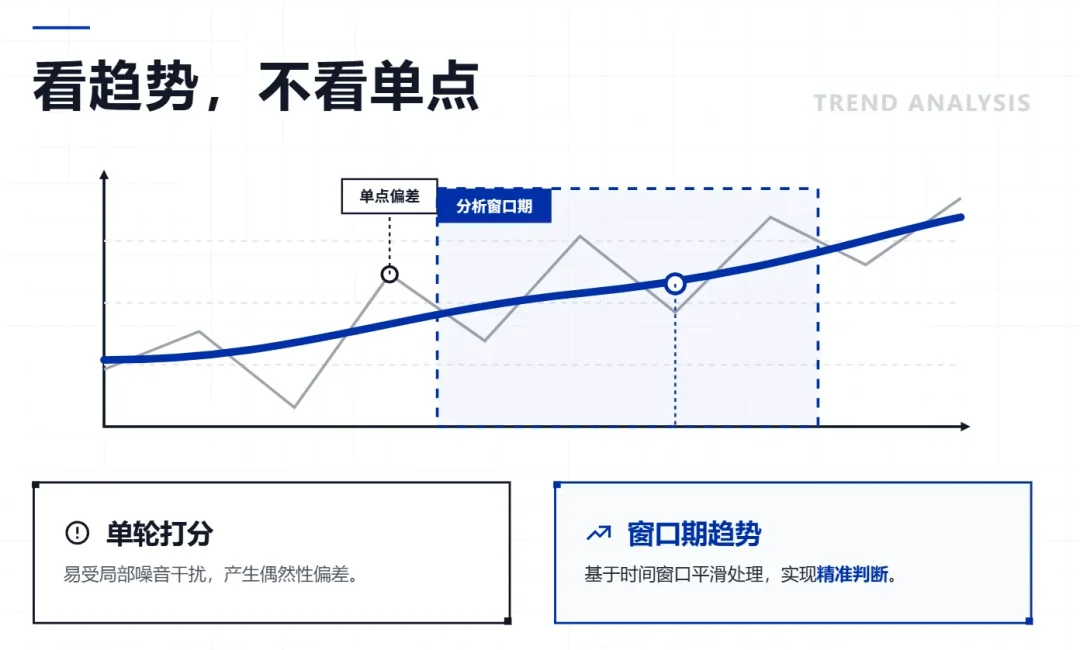
这些数值单轮肯定会有偏差——AI打分嘛,打歪个一两分很正常。
所以导演系统不看某一轮的绝对数值,而是看一段窗口内的趋势:连续几轮在涨还是在降。偶尔歪一次没事,趋势不会被带跑。
程序拿到趋势之后,从一组预设的动作里选一个注入到下一轮的模型输入里。
这些动作听名字就能理解——"缓冲降压""给予突破口""增加阻力""制造推动"——就是告诉AI接下来该松一松还是紧一紧。

AI收到之后自己去发挥,把这个方向变成一段具体的叙事。
怎么推交给规则,怎么写交给AI。
4.4 为什么这样设计
两个原因:稳定性和可调控性。
稳定性是指程序规则的判断是确定性的。同样的输入,永远得到同样的输出。
它不会今天心情好就给你开高难度,明天心情不好就让你无聊到睡着。

可调控性是指规则是人写的,人可以改。如果玩家反馈"游戏节奏太快了",我改一下规则参数就行。
如果让AI自己判断,我根本不知道它是怎么做决策的,也没法精确调整。
这里我想说一句很重要的话:不是让AI当导演,而是用规则系统约束AI。
规则系统是骨架,AI生成是表演。
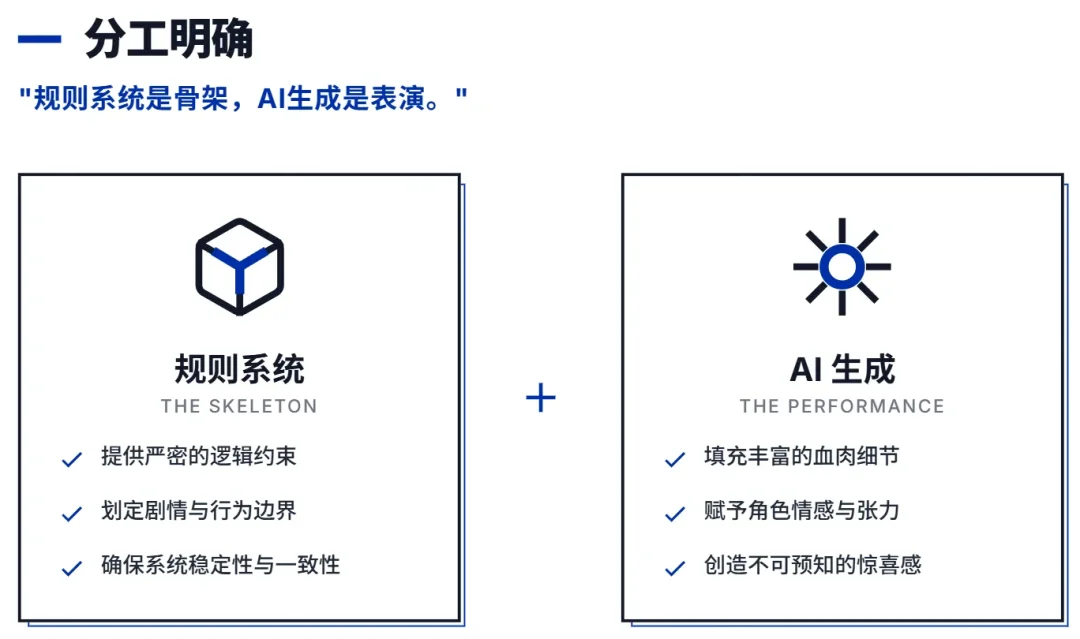
AI擅长的是表达——这句台词怎么说,这个场景怎么描述,这个角色什么语气,它比我们写得好。
但什么时候该升压、什么时候该揭示信息、什么时候该让玩家的道具派上用场——这些需要稳定,不能每次都碰运气。这部分交给规则。
说到底导演系统在做的事情,就是维护心流。前面说过,心流需要挑战和能力持续匹配。
导演系统就是那个在后台不断微调这个匹配关系的东西—— 玩家太顺了就加阻力,卡住了就给突破口,节奏平了就制造推动。
它不是在替玩家做决定,而是在保证体验的张力曲线不会塌掉。
4.5 具体例子:道具困境设计
让我举一个具体的例子。
影视创作有个经典原则叫"契诃夫之枪",如果第一幕墙上挂了一把枪,那这把枪在后面一定要开火。

顺带一提,我本科专业是影视技术,这个概念在课上反复被老师洗脑过。
游戏上也差不多。玩家获得的道具不应该被遗忘,但会更自由松散一些。
说回导演系统。
假设玩家在第3轮对话时获得了一把"寒冰匕首"。导演系统记录下这个事件。 接下来10轮对话,玩家一直没用这把匕首。
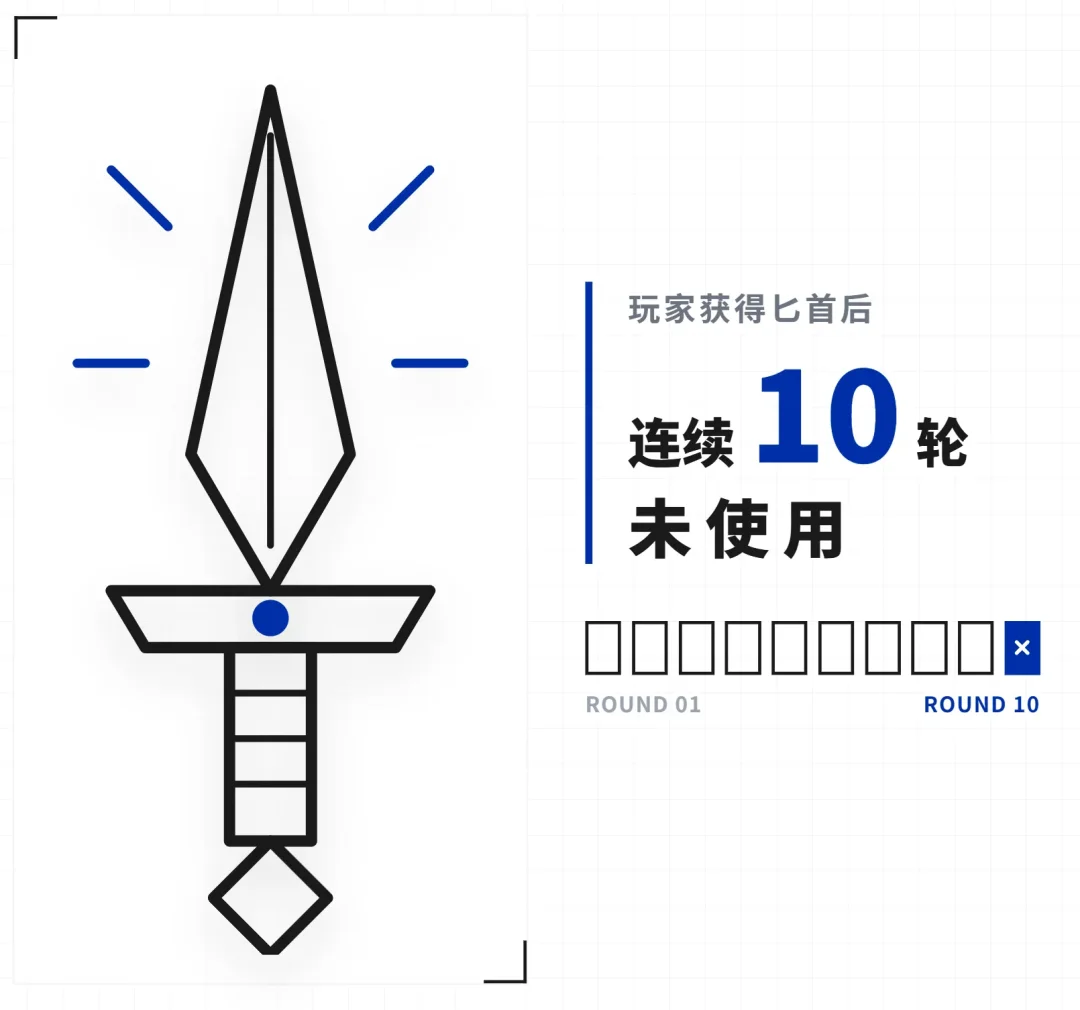
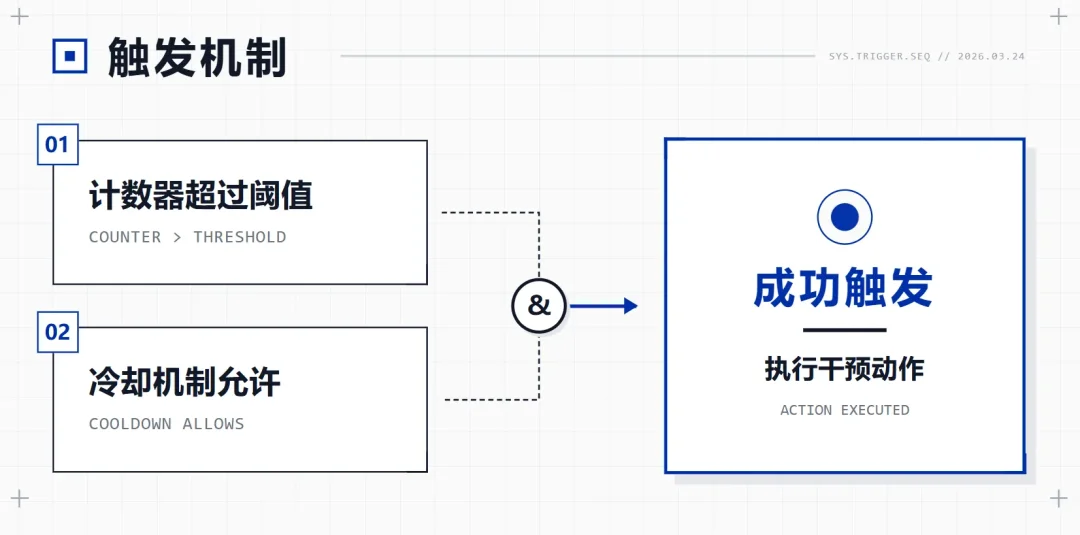
到第13轮,计数器超过阈值。但这不是说到了就一定触发——系统还有冷却机制,到了阈值还得看最近是不是刚干预过、连续干预了几次。
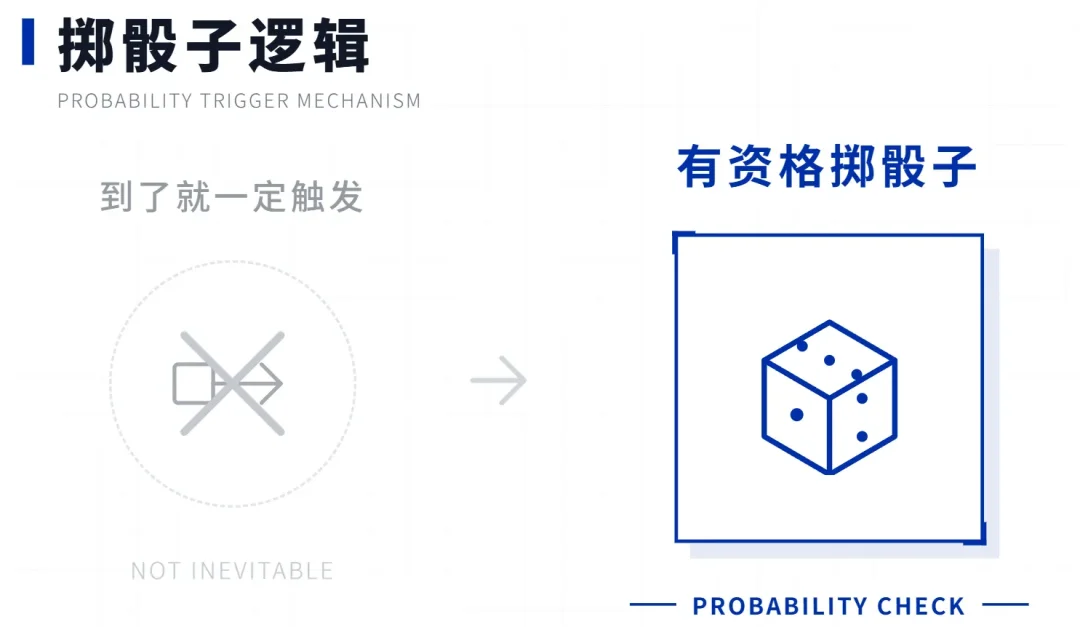
你可以把它理解成跑团里的骰子:条件满足了相当于你有资格投骰子了,但投出来点数够不够,还要看当时的情况。
不是"到了10轮就一定出现",而是到了10轮你才有机会掷这个骰子。
如果触发了,导演系统会选择"制造推动"这个动作。
然后系统要从资产池里选出最合适的那张卡——满足导演条件的候选卡可能有好几张,系统会综合语义相关度和出场间隔来排序,选出跟当前场景最贴合的那一张, 把它注入到下一轮的模型输入里 。
AI收到这个信号,自己去理解、去发挥,在接下来的叙事里自然地把这个元素编织进去。
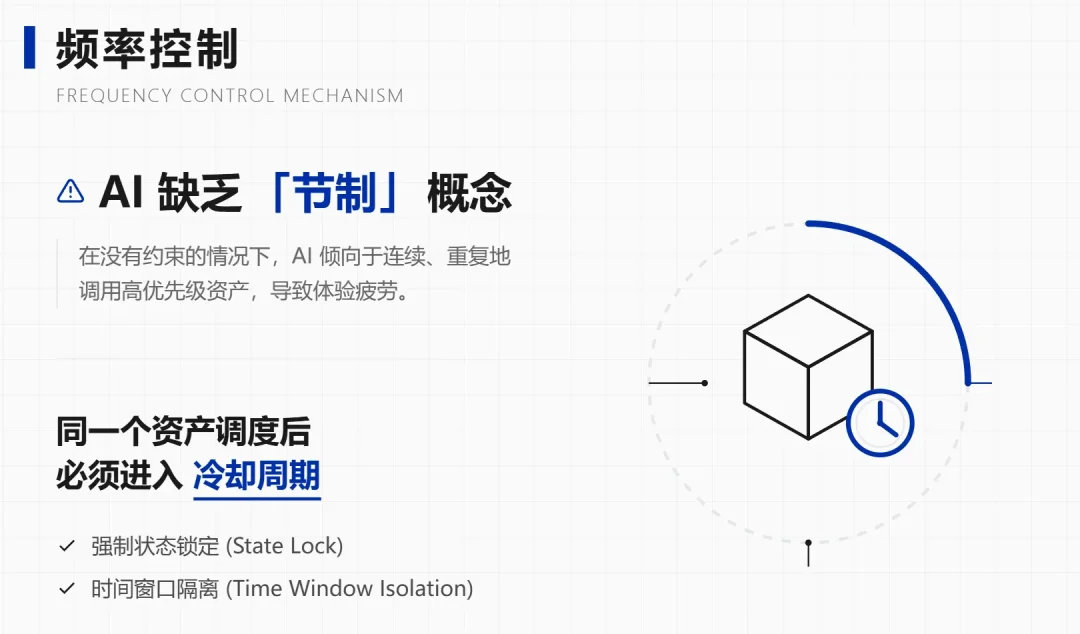
还有一点:同一个资产被调度过之后会进入冷却,不会反复出现。
这种频率控制AI自己很难稳定做到,它在多轮对话中经常丢掉节制这个概念。
剧情资产与语义命中:导演手里的卡
如果有同学用过UE或者Unity这类引擎,大概知道做一段关卡演出是怎么回事——事先在指定位置放一个碰撞框,检测玩家是不是到了这里,到了就触发相应的事件。其实只要稍微玩过一些游戏基本都能理解这个概念。
这些东西就不应该是运行时AI临时拍脑门的,而是需要作者提前设计好的。
我们的系统里已经有了这个能力,也就是剧情资产系统。
5.1 作者做的是什么
作者做的不是一大块提示词,而是一张张"剧情卡"。
每张卡有内容、有适用条件、有导演动作和优先级,结构化地描述一个可能发生的事件或信息。
其中有一个字段叫触发提示,作者在这里写的不是关键词,而是一段自然语言的情境描述——"玩家面临致命威胁,隐藏角色xxx出现前来救场"这种。
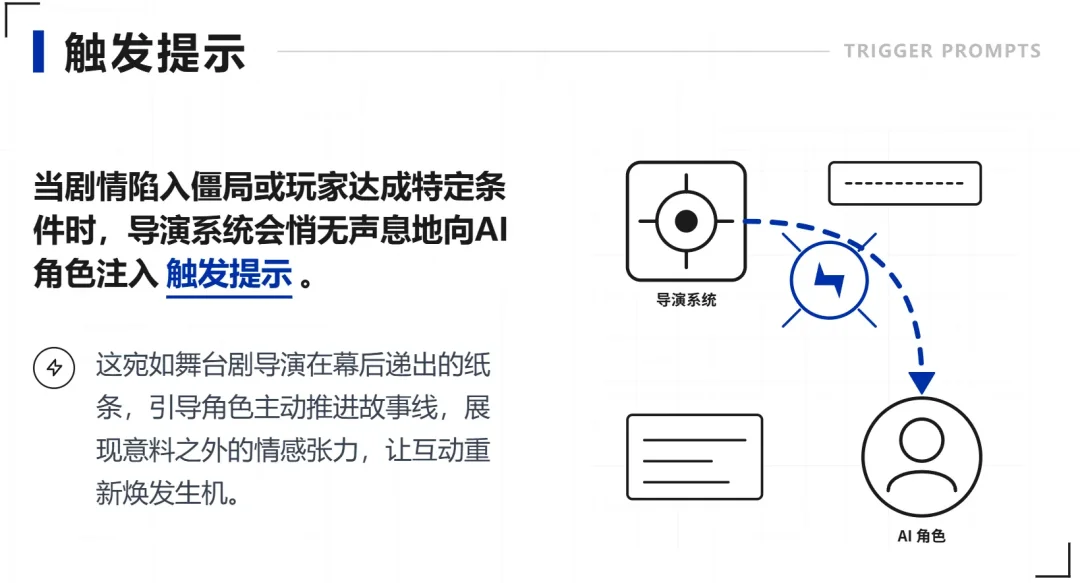
为什么要写成这样,下面讲命中逻辑的时候就明白了。
5.2 怎么决定出哪张卡
这些卡在触发条件满足之前就安静地待在资产池里。每轮对话,系统要决定两件事:该不该出卡、出哪张。
这个决定不是靠单一条件,而是综合打分。
首先得过导演这关——导演选了什么动作、四个数值落在什么区间、哪些角色在场,这些决定了此刻适不适合注入新内容。
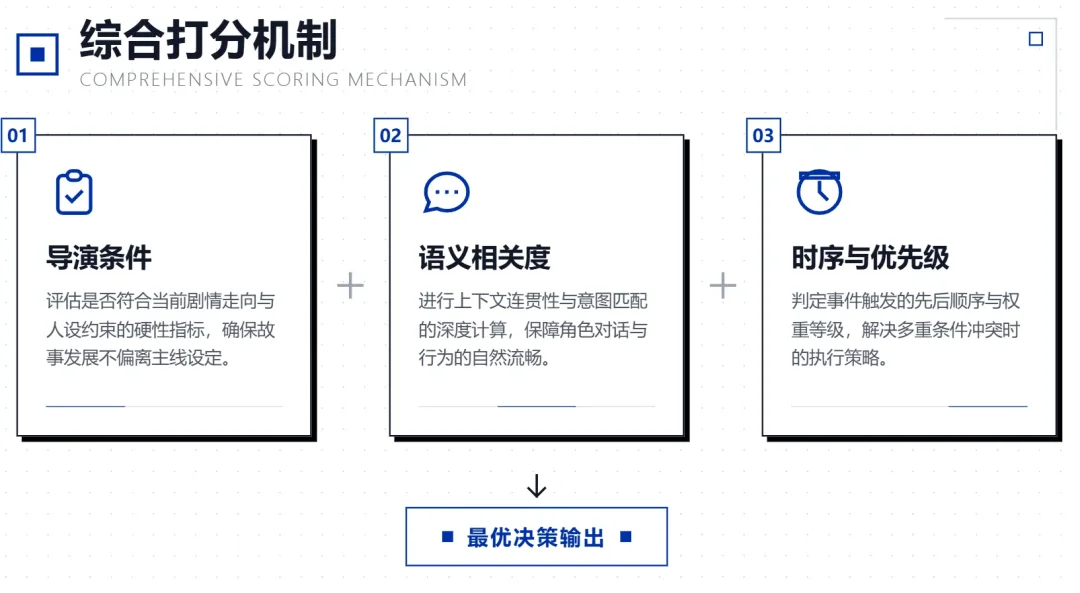
过了这关之后,系统要在候选卡里挑最合适的那张。
这里靠的是语义相关度。每张卡的触发提示在保存时会被系统自动算成一个语义向量,运行时系统拿"玩家这轮说了什么 + 上轮叙事描述了什么"也算一个向量,然后比两个向量的距离。

距离越近,说明这张卡跟当前正在发生的事情越贴合。
这就是为什么触发提示要写成情境描述而不是关键词——向量检索比的是语义相似度,完整的情境描述比零散关键词出来的匹配精准度高得多。
玩家说"我被逼到墙角了,那个怪物越来越近",一张写着"玩家面临近身危险"的卡就会拿到很高的语义分,哪怕一个关键词都没重叠。
除了语义,还有时序和优先级。同一张卡出过场之后会冷却一段时间,从来没出过场的卡有额外加分——这控制的是叙事节奏,同一个元素不会反复出现。
作者觉得重要的卡优先级设高,普通的设低。
几项打完分,加权求和,最高分的那张进 prompt。调试面板能看到每张候选卡的各项得分和最终排名——为什么选了这张而不是那张,一目了然。
5.3 同一套引擎也用在角色设定上
顺便说一下,这套语义命中不只用在剧情资产上。
作者给角色写的特殊设定——比如"这个角色童年被火灼伤过,极度恐惧火焰"——也走同样的语义匹配。
玩家说"我们点个篝火取暖吧",系统自动判断这句话和哪条角色设定语义相关,相关的才激活注入。
不需要作者去凑关键词,写的就是自然语言描述,系统自己能理解什么时候该用。
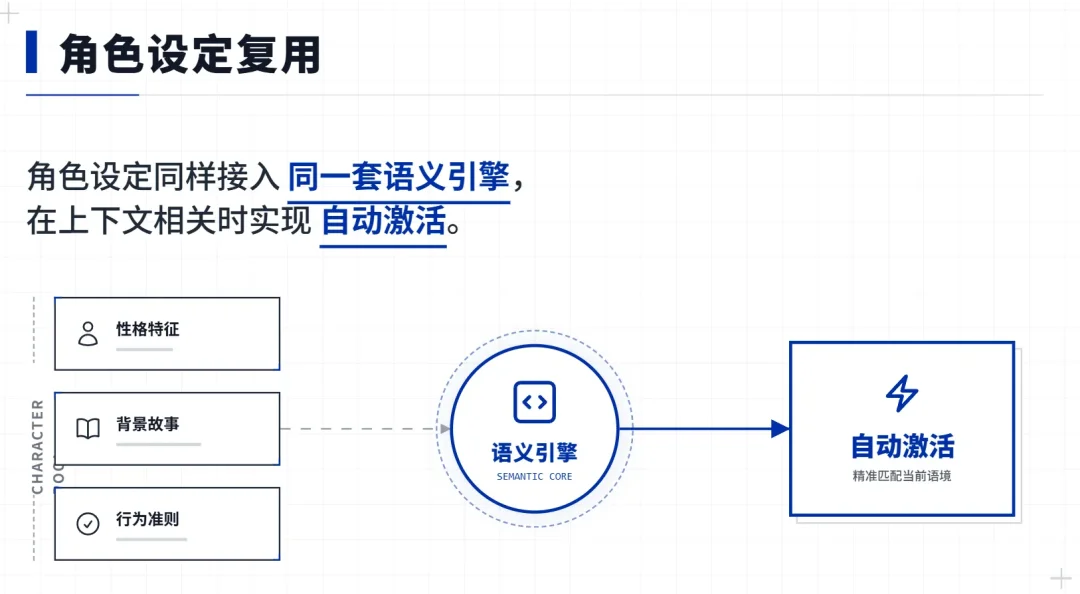
剧情资产和角色设定共享同一套语义引擎,每轮只需要算一次查询向量,两边同时用。
角色记忆:让角色真的会成长
前面讲了作者写的特殊设定会走语义命中——"对火焰恐惧"这种条目存在那里,相关的时候自动激活。
但有个问题:作者写的设定是静态的,写完就不变了。
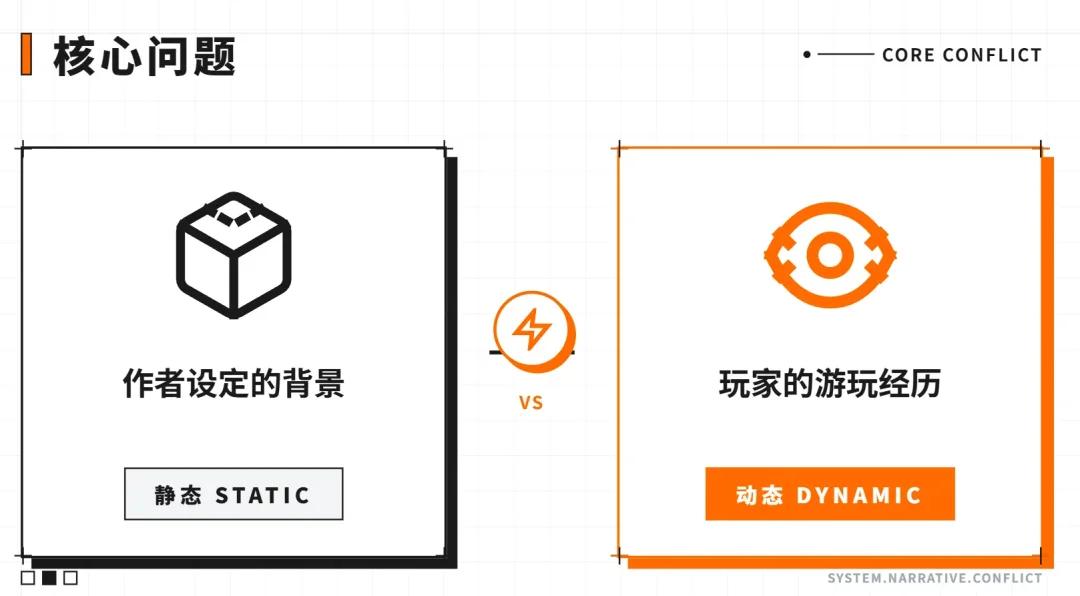
角色在游玩过程中经历的事情呢?比如某个角色在废墟里被火焰陷阱困住、玩家冒险把她拉出来、她从此对玩家产生了信任——这些是玩的过程中发生的,作者没法提前写好。
如果这些经历只存在聊天记录里,几十轮之后被压缩掉了,角色就"失忆"了。
这也是前面分析平台时反复出现的痛点——角色记不住"你们从互相防备到彼此信任的过程"。
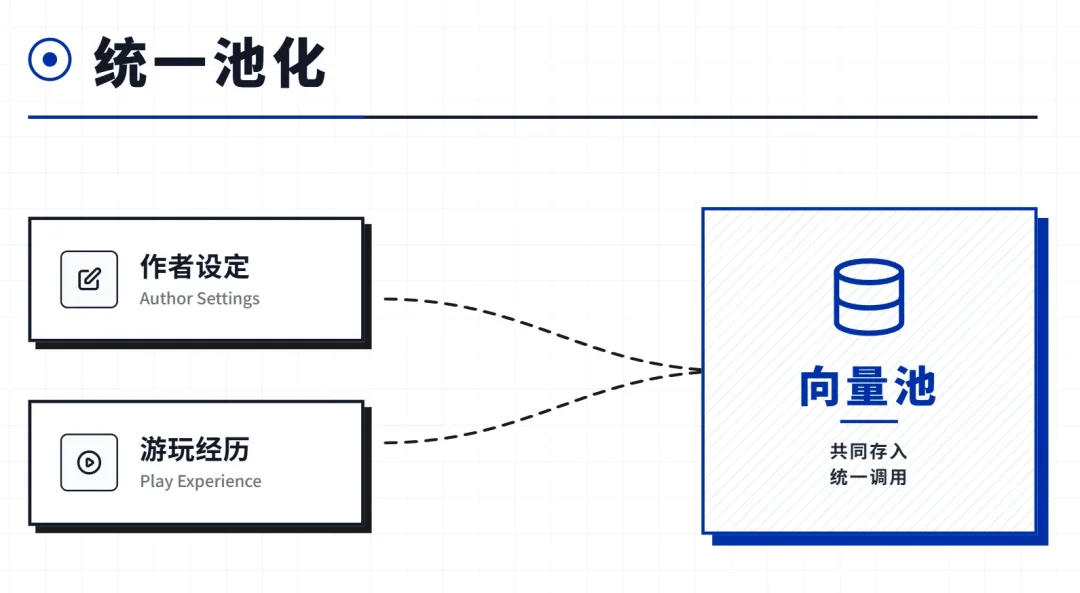
我们的做法很简单:角色的经历也往同一个池子里扔。

前面说过,作者写的角色设定是一条条文本,存在池子里,向量化,语义命中。角色的记忆也是一条条文本——只不过来源不是作者手写,而是系统在游玩过程中自动生成的。
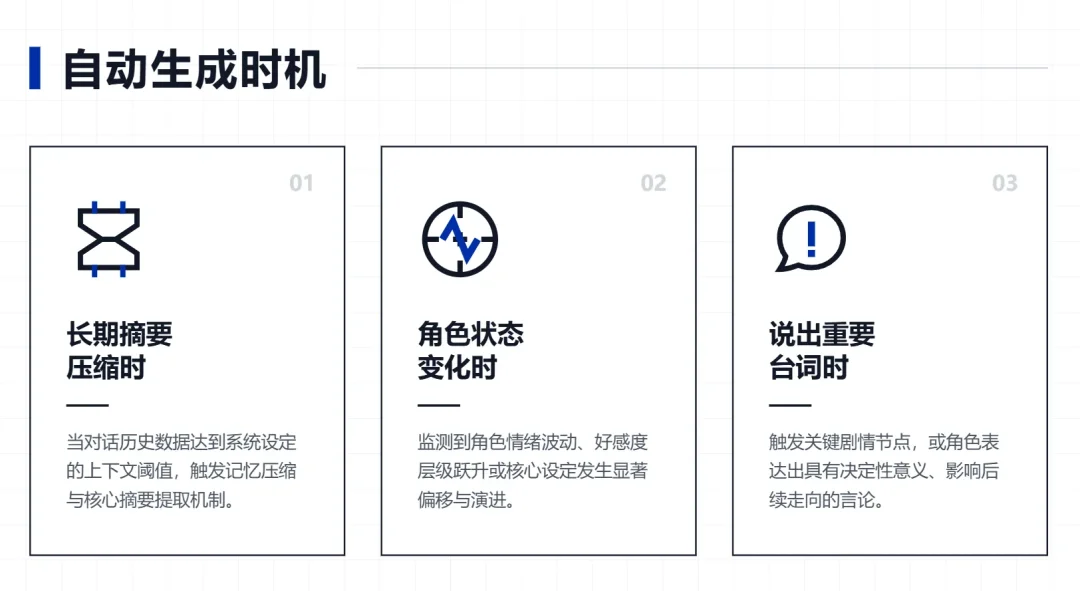
具体来说,系统在几个时机往角色的条目池里追加新条目:
系统做长期摘要压缩的时候,会顺带把跟该角色相关的事件拆出来,写成一条经历——"在地下城被队友背叛,独自逃出"。
模型通过隐藏通道回报角色状态变化的时候,也会生成一条——"对陌生人的信任度很低,倾向于单独行动"。
角色在关键场景里说过的重要台词,也可以存一条。
这些条目写入的时候自动算 embedding,跟作者写的设定混在同一个池子里。
系统不需要区分"这是作者写的"还是"这是玩出来的",对语义引擎来说都一样——都是一条条带向量的文本,该命中的时候自然会命中。
比如后来玩家遇到一个NPC要求组队,系统就会命中"被队友背叛"和"信任度低"这两条记忆。
模型看到这些,自然就知道这个角色此刻该犹豫、该抗拒,甚至可能在对话里提起那次经历。
作者从来没写过"遇到组队邀请时如何反应"这条规则,但角色的过去自己替她做了这个决定。
角色就这样在玩的过程中慢慢积累自己的经历、性格变化和关系变迁。
量大了怎么办?前期不用担心,向量检索本身就是为大量条目设计的,几百几千条检索速度几乎没区别。
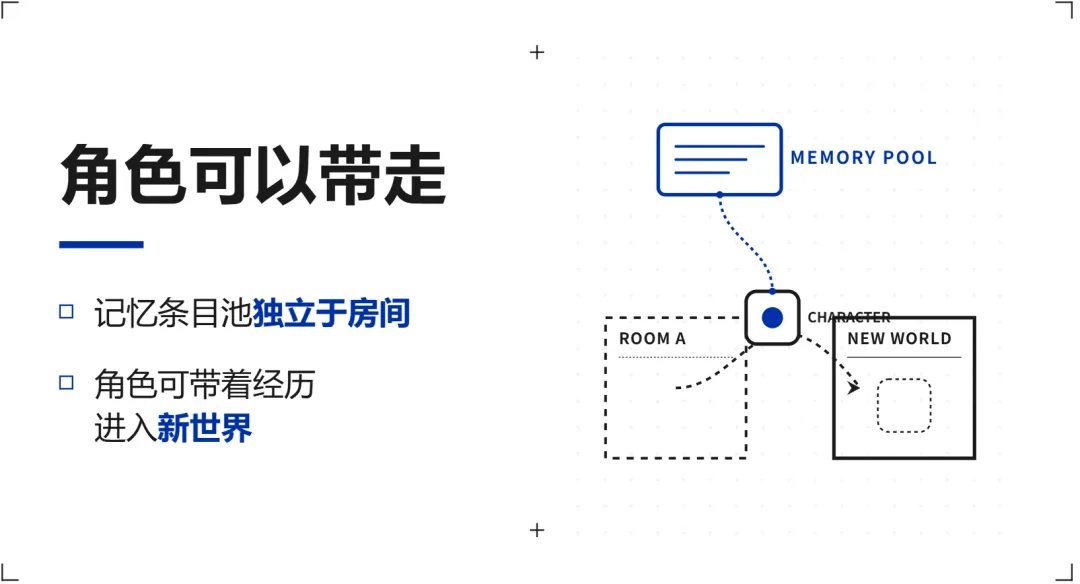
这套东西还有一个好处:角色可以带走。
角色的条目池是独立于房间的,可以导出成一份本地文件。开新房间的时候选择导入,这些条目就进了新房间的检索池。
系统不需要做什么特殊处理,下一轮对话算查询向量的时候,这些记忆条目自然就参与语义命中了。
该想起什么、该表现出什么,检索引擎自己会找到。
前面分析的几个平台都有一个共同的问题:角色被锁死在一个对话框里,带不走。 但用上述方法构造的角色是跟着玩家,而不是跟着房间走的。
时间连续性:让世界有呼吸感
先问大家一个问题:你上次玩一个单机游戏,打到一半存档退出。
过了一周,你再打开游戏,读档继续。这时候游戏世界是什么状态?
它还停在你上次退出的那一秒。NPC站在那儿一周了,一动没动。
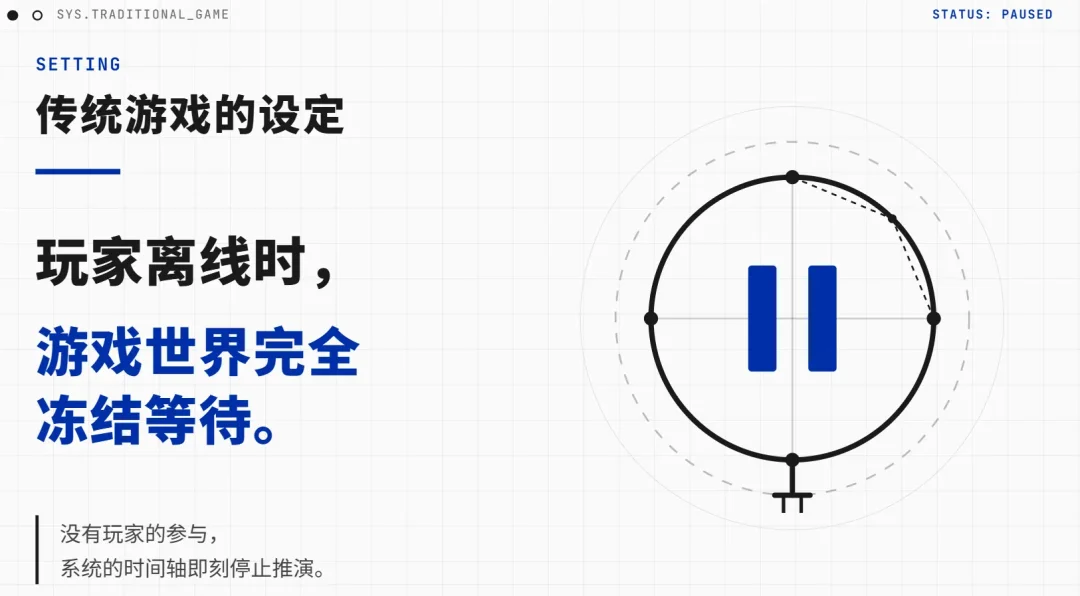
我们已经太习惯这种设定了,以至于觉得它是理所当然的。但这其实很奇怪:玩家现实里已经过了一周,但游戏世界完全冻结了。
AI原生游戏已经可以做一件新事情:玩家离线后,世界不必完全暂停。
这不是在玩家离线时真的持续运行模拟。实际的机制很简单:
当玩家回来发起新的对话时,系统把"你离开了多久"和推进边界作为额外的上下文交给LLM,在你回来的那一刻一次性生成这段时间里"发生的事情"。
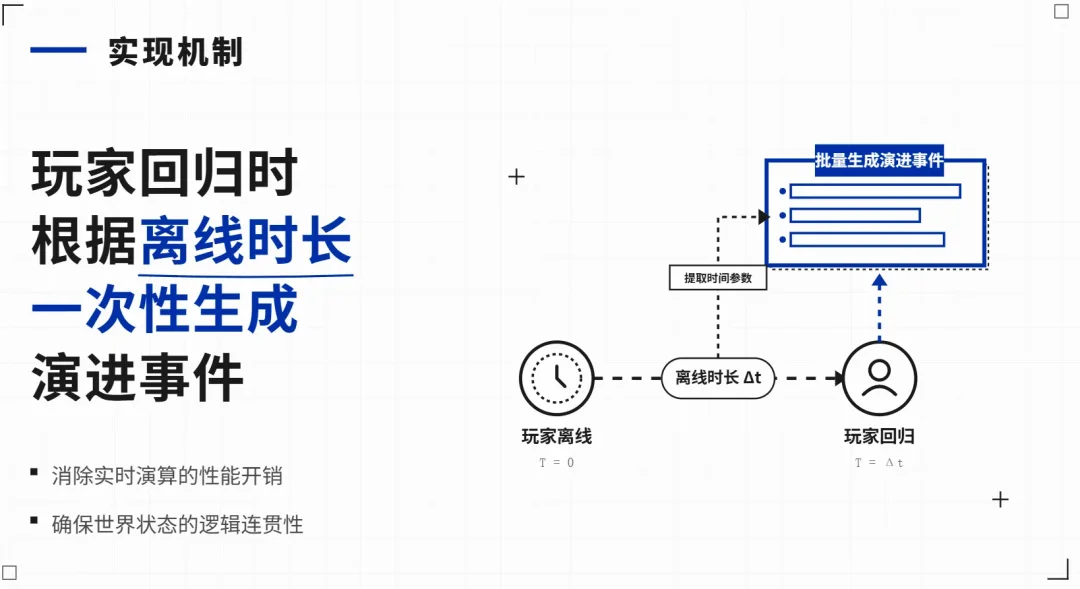
这些"发生的事情"受到导演系统的约束:如果你离线前正处于危机时刻,世界只推进很少;如果你离线前把事情都处理好了,世界可以推进更多。
关键原则是:世界不会推进到让玩家觉得被抛下的程度。所有需要玩家做决策的节点都会冻结等待,只有日常性的世界演进会自动发生。
更有意思的是,你可以在离线前给出指令。 比如你下线前对同伴说:"你们先去打听一下镇上的消息,我明天回来。 "然后你第二天打开游戏,同伴会告诉你他们做了什么。他们真的去做了这件事,而且结果是合理的,做一半,留一半,留下需要玩家参与的部分。
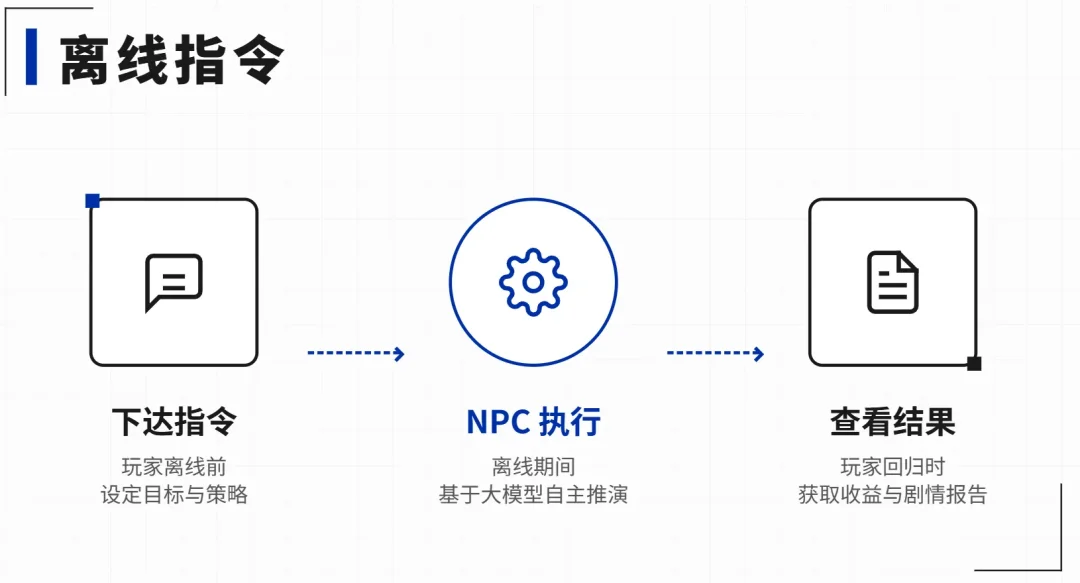
回归体验也要设计好。 不要给系统报告,要让世界自己体现变化:同伴自然地提起"你去哪儿了?这两天可发生了不少事",环境自己体现村子里的变化,关系带着变化出现。 世界要接住玩家,而不是给玩家一份邮件周报。
你离开了,世界继续运转,但不会把你甩下。关键剧情等你回来,日常世界自己演进。让玩家感到世界在前进,但不是被世界抛弃。
总结
到这里这次分享差不多也就结束了。
今天讲的东西其实就一条线:AI角色扮演产品越玩越无聊,问题不在AI,在于没有人管体验该怎么走。我们填充的就是这一层。
为好的故事讲究"意料之外、情理之中"。
意料之外AI天生就会,每次重roll都可能是差别非常大的结果。但情理之中得要兜底。用规则去约束,把数据给记录住,不管AI怎么发挥,体验的底线不会塌。
都看到这里了,求个点赞收藏不过分吧?~QWQ
目前该项目正稳步推进中,定位类似酒馆,等待成品版本开发稳定后会放到github开源,欢迎各位同学B站关注我私聊讨论!!
个人主页:某驾校校长的个人空间-某驾校校长个人主页-哔哩哔哩视频
文章来自于"LitGate",作者 "某驾校校长"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


