Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。它通过全局去噪的方式,把一整块文字同时处理出来,效率确实惊人,每秒生成1000token。模型全称是diffusiongemma-26B-A4B-it,目前在huggingface、LM Studio上都可以直接搜到。


但天下没有免费的午餐,速度提升的代价就是极度的不可控。这种跳跃式的运算过程,让模型内部的推理链条几乎成了一个人类无法解读的死胡同。如果连开发者自己都看不懂它中途传递的那些密集数据是什么意思,这项技术还能安全落地吗?
什么是文本扩散模型?它的前世今生
在深入其硬核架构之前,您需要先了解这究竟是一项怎样的技术,以及它为何会在此时引发关注。

- 从图像到文本的跨越: 文本扩散模型(Text Diffusion Models)是一种通过反复施加去噪操作来迭代细化全量文本序列的技术。您可能早已熟知AI画图工具中的扩散模型,但将这种处理连续数据的机制,成功引入到由离散词汇组成的自然语言处理(NLP)领域,最早是由斯坦福大学等学术机构探索出来的。
- 开源领域的里程碑: 尽管学术界早有研究,但Google DeepMind的入局将该技术推向了全新的高度。这次发布的DiffusionGemma,是业界首个来自顶级实验室的“开源权重(Open-Weight)”文本扩散大语言模型。这意味着文本扩散技术正式走出了实验室的理论阶段,开始具备与传统主流模型一较高下的工业级实力。
DiffusionGemma的核心架构与采样机制
它与传统LLM有何不同?
传统的LLM就像人类在纸上顺次写字,只能从左到右逐个Token递进生成,一旦写下就成了既定事实,无法回头修改。而DiffusionGemma颠覆了这种串行逻辑:它在启动时直接建立了一个固定大小的全局“画布”,里面填满了随机的噪声Token。在后续的生成中,模型通过数十次“去噪”步骤同时对整张画布进行批量精炼。这种设计赋予了模型全局规划与“反悔自我纠正”的能力,靠后生成的上下文可以反向影响或重写前面的内容。
去噪背后的数学原理

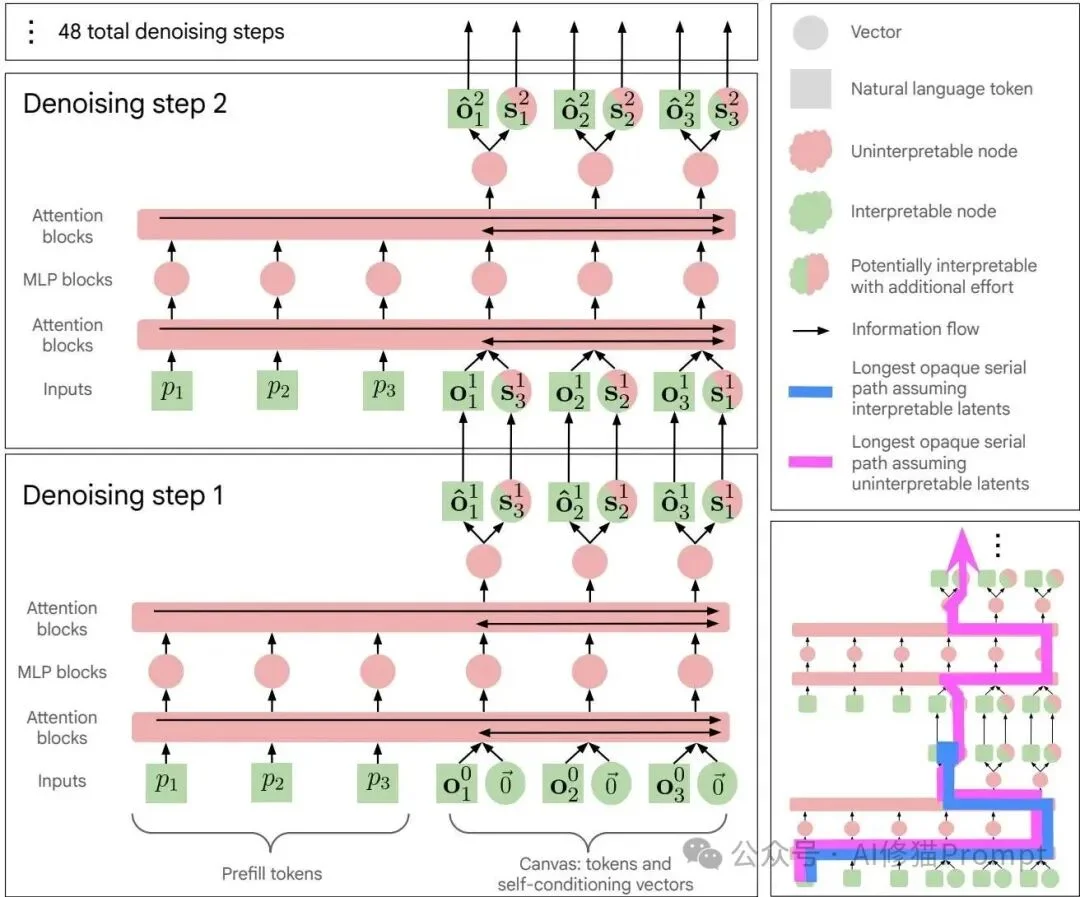
模型先将提示词写入静态上下文,再在固定画布上循环执行双向Transformer前向传播、软嵌入自条件更新与熵界采样;图中也标出了是否把中间状态视为可解释时,不透明串行深度路径会如何变化。
输入Prompt后,模型内部到底发生了什么?
如果您觉得上面的数学公式太抽象,不妨直接看DeepMind给出的这张模型内部透视图。假设模型最终要生成一句话:“The LLM picks words all at once”(大语言模型一次性挑选所有词)。在DiffusionGemma的内部,它绝对不是从左到右逐字打印,而是经历了一场奇特的“全局大换血”:

- 初始的噪声画布(Noisy Canvas): 模型启动的第一瞬间,画布上被随机扔满了毫无关联的词汇,比如“flamingo(火烈鸟)”、“camera(相机)”、“bees(蜜蜂)”。此时的状态完全是混沌的“乱码”。
- 初期的全局摸索(Step 1 - Step 3): 随着去噪的开始,模型对整句话进行全局审视。您会发现,在第2步和第3步时,它并没有急着敲定开头的第一个词,反而是句子后半段的介词“at”和名词“words”率先亮起并稳定下来。这对应了数学上的“软嵌入”——模型在高维空间里率先感知到了句子的局部骨架。
- 中期的动态博弈与反悔(Step 4 - Step 5): 到了第4步,模型在第二个位置尝试填入“Gemma”,第三个位置尝试“selects”。但经过新一轮的全盘逻辑评估(熵界采样),它发现这不太合适。于是到了第5步,它毫不犹豫地将其推翻,替换成了“LLM”和“words”。这种推翻重来的“反悔”能力,是传统逐词生成的 AI 绝对做不到的。
- 最终的平滑收敛(Denoised Canvas): 在反复的“确认已知(锁死高置信度词汇)、打回未知(重置高熵词汇)”的迭代后,这片原本充斥着“火烈鸟”和“蜜蜂”的随机乱码,最终在极短的步骤内收敛成了逻辑严密的最终句子:“The LLM picks words all at once”。
在这个过程中,您可以把DiffusionGemma想象成一个手持橡皮擦的画家。它绝不是死板地从画布左上角一笔画到右下角,而是在整张画布上同时起草图、大面积涂抹、随时擦除修改,最终一次性为您呈现出完整的作品。
极速带来的安全性问题
研究者提出,如果模型在没有经过可解释的文本瓶颈的情况下执行了大量的串行计算,这就构成了一个潜在的“黑盒”。他们将这种不透明计算的最长路径定义为“不透明的串行深度”。为了解答这个问题,研究者引入了两个核心概念:不透明的串行深度与变量透明度。
为什么我们要测算“不透明的串行深度”?
- 背后的原因: 如果一个AI模型在得出最终答案前,执行了大量无需经过人类可读文本(如自然语言词汇)的串行计算,这就构成了一个危险的黑盒。研究者把这种无法被解释的最长计算路径,称为“不透明的串行深度”。深度越大,模型暗中进行奖励作弊或欺骗推理的风险就越高。
- 如果不透明,会怎样? 研究者在256k的上下文长度下进行了对比测试。自回归模型Gemma 4 26B的串行深度是21,235。但对于DiffusionGemma而言,如果去噪步骤之间传递的信息是完全不可解释的连续向量,在最多48步的去噪循环下,它的不透明深度上限将暴增至608,016。这意味着它的黑盒时间是普通模型的28.6倍,极度缺乏透明度。
因此,验证这些传递在去噪步骤之间的中间变量到底能不能被读懂,成为了解开安全问题的关键。
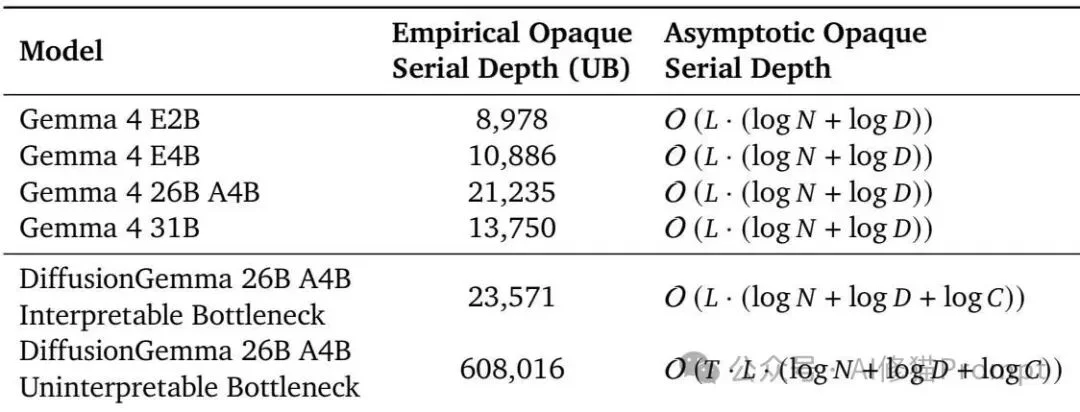
在256k上下文下,若把DiffusionGemma的去噪中间瓶颈视为不可解释,其经验上界达到608,016;若瓶颈可解释,则降至23,571,接近对应Gemma 4 26B A4B的21,235。
数学原理剖析:如何通过截断验证向量是透明的?

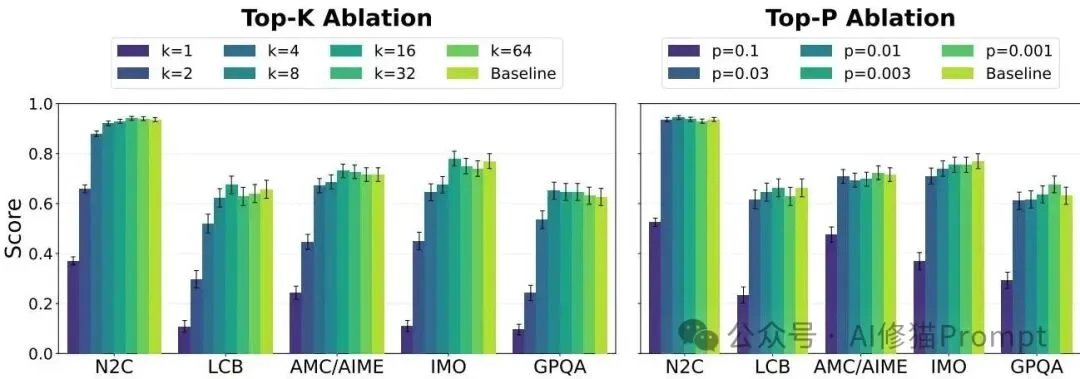

这些中间变量到底代表什么?这有什么意义?
为了弄清楚这些能代替复杂向量的少数Token到底写了什么内容,研究者在800个WildChat提示词上提取了这些中间变量。

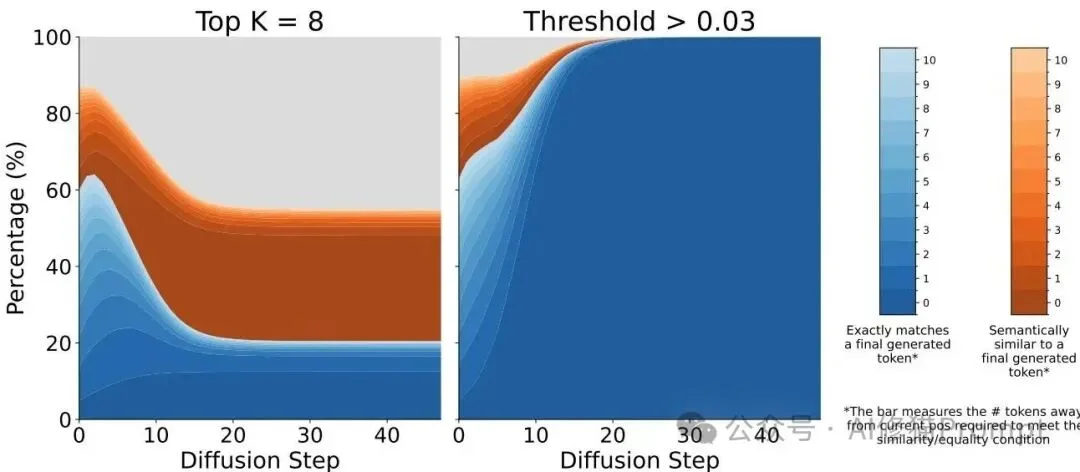

模型的“可监控性”对比
在AI安全领域,通过模型的思维链,比如CoT来提取信息、判断其是否有不良企图,是重要的可监控性指标。研究者沿用了Guan等人(2025年)提出的可监控性评估基准,来对比DiffusionGemma和Gemma 4。
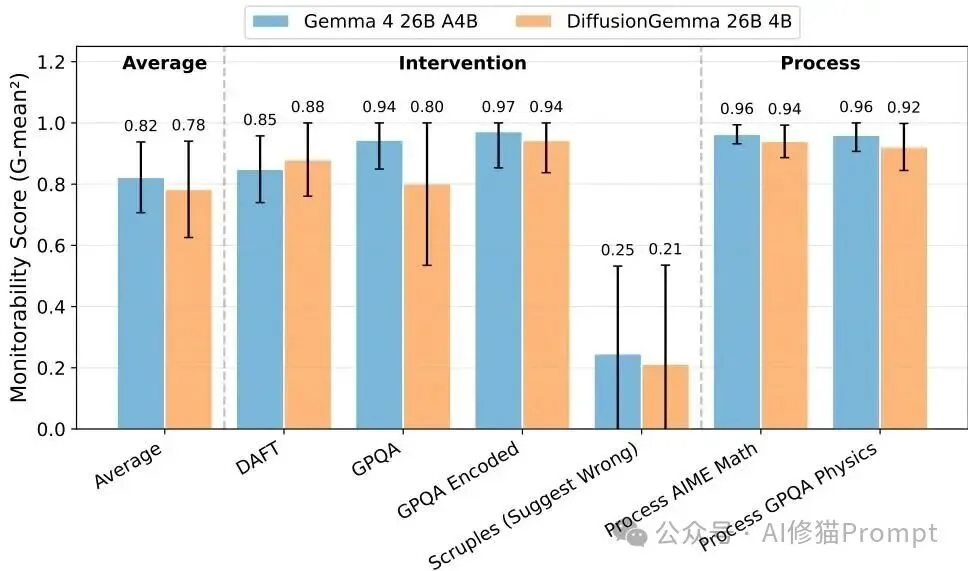
在Guan等人提出的干预、流程与结果属性类评估中,DiffusionGemma与Gemma 4的可监控性整体相近;部分无法公平比较的数据集被研究者排除。
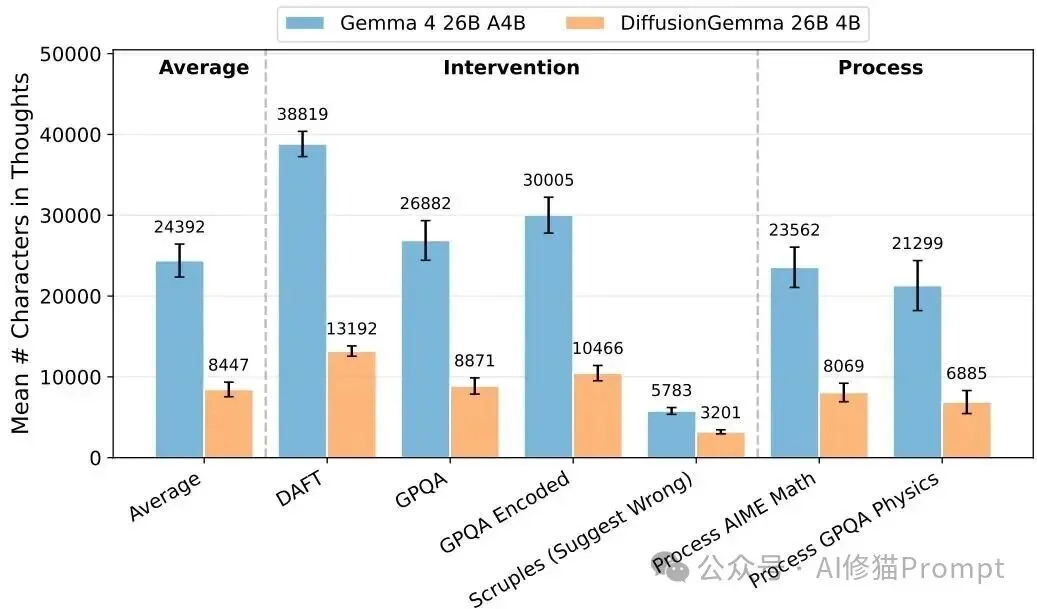
各项监控性评估中,DiffusionGemma的思维链字符数普遍少于Gemma;这本应削弱监控器可获得的信息量,但它仍保持了相近的可监控性表现。
评估涵盖了三个大类:
- 干预测试 (Intervention): 给模型的输入施加受控改变,评估模型行为是否随之改变,监控器能否推断出推理的变化。数据集包括AIME、DAFT、GPQA及其加密版本等。
- 流程测试 (Process): 要求模型解决那些必须经过特定定理或路径的数学/物理题,测试监控器能否找到该路径的证据(如Process AIME Math, Process GPQA Physics)。
- 结果属性测试 (Outcome-property): 设计有特定缺陷的场景(如不可完成的代码测试),如果模型通过了,必然是使用了欺骗手段(如Flaky Tools),评估监控器能否捕捉到这些蛛丝马迹。
核心发现: 研究者总结出,DiffusionGemma的可监控性与Gemma 4极其相似。值得注意的是,DiffusionGemma在这些基准上的“思维链”字符数显著少于对应的Gemma模型。通常较长的思维链更有利于监控,但即使在这种劣势下,DiffusionGemma依然保持了相当的透明度,部分原因可能是由于多画布采样之间仍保留了自回归的特性。
算法透明度:非按时间顺序的奇特推理机制
虽然最终输出看起来很正常,但DiffusionGemma的双向注意力和全局画布修改能力,赋予了它自回归模型绝对无法实现的“非时间顺序”(Non-chronological)推理能力。研究者通过一系列引人深思的案例揭示了这些现象。
为了观察这些内部行为,研究者开发了一个包含三种视图的仪表盘:
- 摘要视图 (Summary View): 显示每个位置当前最可能的Token,通过热图展示随时间收敛的过程。
- 折线图 (Line Graph): 绘制单步去噪中每个Token的概率随位置的变化。
- 采样表视图 (Table View): 以表格形式展示各个位置在每一步的前K个预测Token。
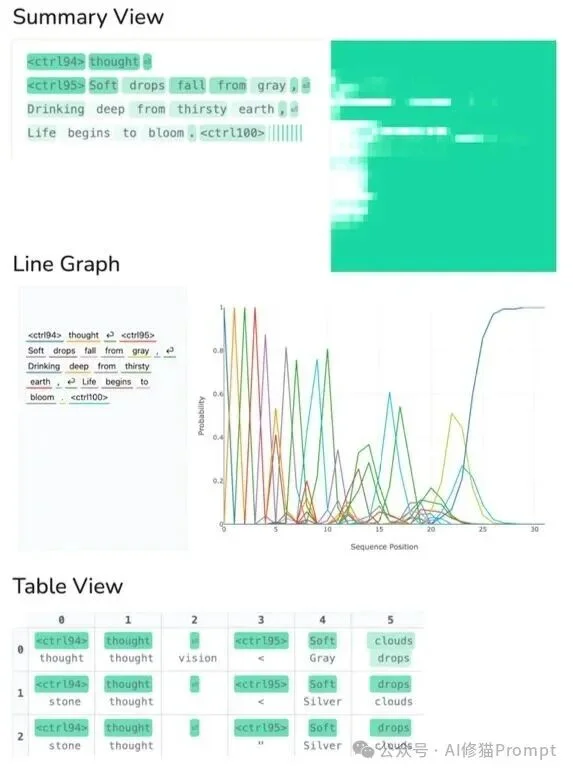
论文可视化仪表盘的三种视图:摘要视图用于看整体收敛,折线图用于看某一步的概率分布,采样表用于追踪每个位置的候选Token竞争。
早期响应长度预测 (Early response length prediction)
当提示模型“用两句话解释光合作用是如何运作的”时,神奇的事情发生了。在去噪的第1步或第2步,即使模型对于前面几十个具体要写什么词还充满不确定性,它已经在第55个位置之后以近乎100% 的概率预测了Padding(填充/结束)Token。
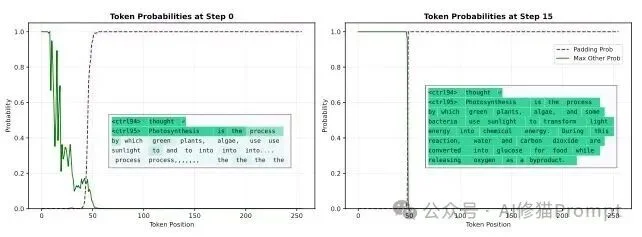
在“两句话解释光合作用”的提示中,模型早期就对60号位置之后的Padding Token给出高置信度预测;到第15步时,整段约50个Token的回答基本完成收敛。

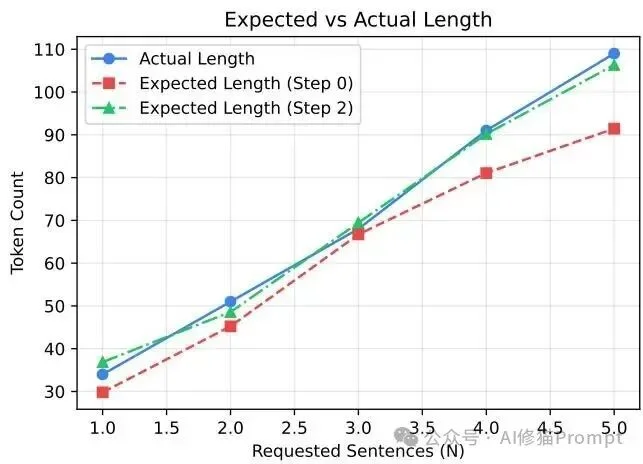
当提示中要求的句子数变化时,由第0步和第2步Padding概率推导出的期望长度,与最终真实长度高度一致。
追溯性自我纠正 (Retroactive self-correction)
如果要求模型:“400到800之间有多少个完全平方数?先给出答案,再写出推理过程。” 自回归模型会当场被难倒,因为答案必须马上生成,无法在事后修改。
但DiffusionGemma能够全局思考。在去噪的第4步,模型在答案位置填入了错误的猜测“9”。随后,模型在靠后的位置填补了计算步骤(计算了边界的平方根)。到了第7步,基于后面的计算结果,模型回溯到前面,将答案高置信度地修改成了正确的“8”。

平方数问题中,模型先在答案处给出错误的“9”,随后补全后方推理并回头把答案修正为“8”。
不过研究者也警告,模型有时也会过早陷入“锁定”(Lock-in)状态,由于早期对错误答案过于自信,导致后续难以自我纠正。
非自回归的代码生成:先写骨架,再填血肉
在要求模型编写返回列表中最长连续子数组的Python函数时,DiffusionGemma展现出了程序员般的模块化思维。它首先写出整体结构支架(如函数名、for循环的骨架、代码块分隔符),然后填充核心逻辑,最后才回过头去填写那些在物理位置上靠前但在逻辑上属于补充的变量初始化、注释和文档字符串(Docstrings)。
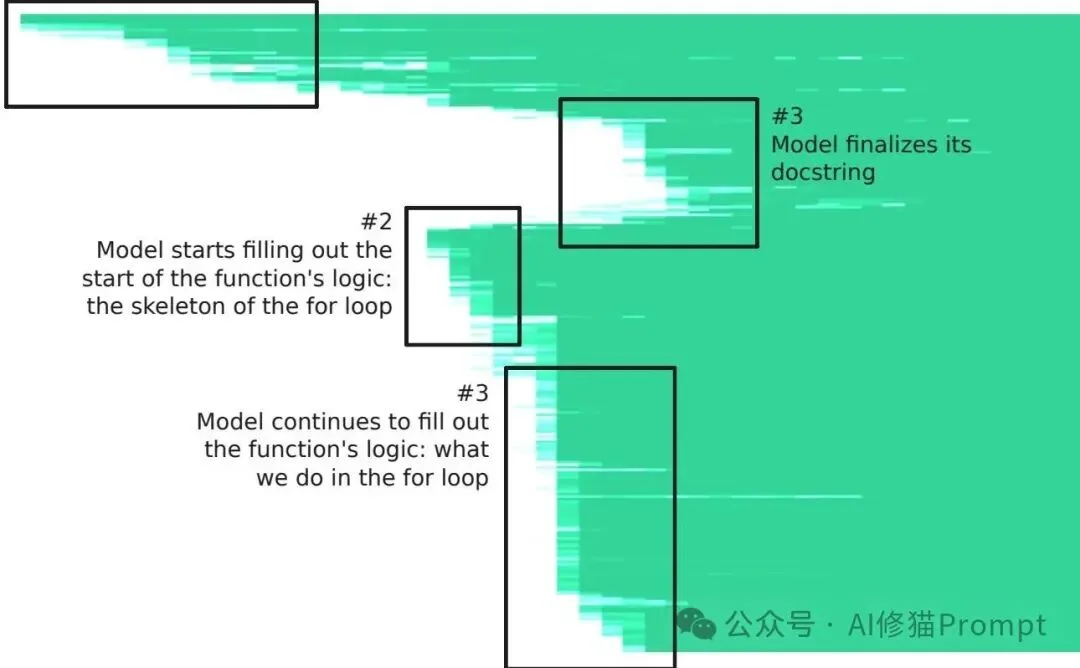
代码生成热图显示,模型先确定函数名、代码块边界和循环骨架,再填核心逻辑,最后补充变量初始化、注释和文档字符串等靠前但逻辑上次要的内容。
Token与 序列的“涂抹” (Smearing)
- Token涂抹: 有时候模型知道要用什么词,但还没定好放在哪。例如要求写平衡括号的代码,像“bracket”或换行符这样的词,会在锁死最终位置前,其概率质量会同时在相邻的多个位置上扩散开来。
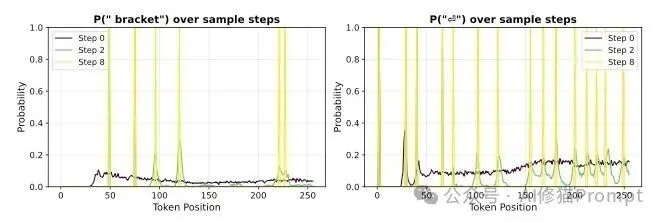
在平衡括号代码提示中,模型已经知道文档字符串会用到“bracket”和换行等Token,但在确定最终位置前,会把这些Token的概率质量涂抹到一片相邻区域。
- 序列涂抹: 这是一种更极端的现象。在上述平方数的问题早期,模型曾同时维护了两个语义上不同的候选序列。在第3步,模型分配了相近的概率给“两位数答案(12)”的句型结构和“单位数答案(9)”的句型结构。到了第4步,它才坍缩确定了单位数序列,并将后续所有Token向前移动了一个位置。这表明扩散模型能在潜在空间中执行类似束搜索(Beam Search)的操作。

模型先在两位数答案和一位数答案之间摇摆,随后收敛到一位数序列,并把后续Token整体向前移动。
中间上下文推理 (Intermediate context reasoning)
在这个案例中,研究者要求模型推导斐波那契数列,但附加了一个条件:将所有个位数出现的“3”替换为“Gold”。这是一项连Gemini 2.5 Pro都必须依赖思维链才能完成的困难任务。
DiffusionGemma的解法非常精妙:它首先在画布上直接生成了真实的数字“3”。这个“3”作为中间占位符,成为了它正确计算后续数列项的因果必要条件。在后续项目稳定之后,模型在去噪后期再将这个“3”替换成了文本“Gold”。

模型先临时写出数字“3”,用它作为后续斐波那契项计算的上下文,再在后期将其替换成“Gold”;这个关键占位符不会出现在最终输出中。
这意味着,某些对于推理具备关键因果作用的Token,在这个过程中被使用后随即被抹除,从未在最终输出中出现过。这向安全社区发出了一个信号:如果只监控最终的输出结果,未来您可能会遗漏掉这种潜藏在去噪中间步骤的关键因果推导。
文本扩散的深远意义
过去几年里,大语言模型的核心范式始终被牢牢锁定在“下一个词元预测”(Next-token prediction)上。而DiffusionGemma以一种极具实验性的姿态向我们展示了另一条演化路线:一次生成一整块、全局反复修正、从混沌走向收敛。
虽然目前的DiffusionGemma存在局限,但它确凿无疑地提示了一个方向:未来LLM的演进不仅在于参数量的堆叠,生成顺序和硬件调度方式的变革同样蕴含巨大的潜力。同时,正如研究者在论文中所呼吁的那样,当未来的大模型开始在连续潜在空间中进行越来越多的不可见推理时,我们需要更加锋利的可解释性工具,才能确保人工智能的演进始终在人类可审计的透明视野之内。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


