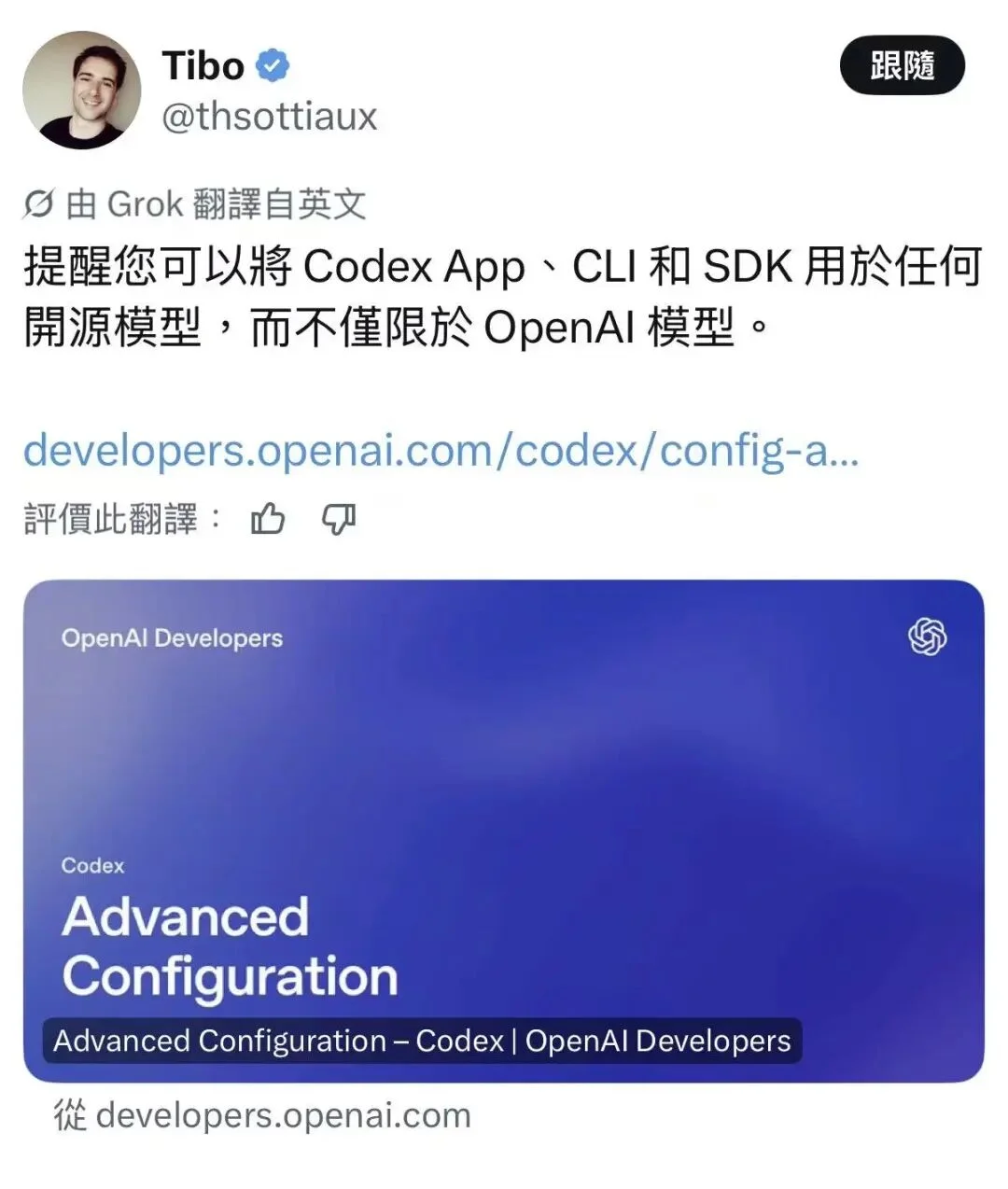
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。他还直接贴了官方配置文档的链接,指向 OSS 模式和本地 provider 的部分。看到这条消息的时候,我第一反应其实挺意外的,因为 OpenAI 长期以来给人的印象一直是比较封闭,这次突然把自定义模型供应商的门打开,确实有点不一样。
主要是,Codex 并不一个普通的工具,它本质上是一个完整的工作台,能让模型读文件、写文件、调用 shell、抓取网页、执行命令,还能根据工具返回的结果继续推理判断,最后输出可交付的成果。也就是说在 Codex 里,模型不光要会说话,更重要的是得真能干活。
(图源:X)
过去很多人吐槽 OpenAI 封闭,其实不光是因为模型不开源,更核心的原因是它的工具、模型和工作流都被整个包在自家体系里,你可以用,但很难拆开重组。尤其是 Codex 这种 Agent 工具,本质上是模型能力、工具调用、上下文管理、权限控制和本地环境的组合。也就是模型越强,工作台越完整,用户就越不容易离开。现在 OpenAI 给 Codex 留出了 custom model provider 入口,至少在产品姿态上不再只把 Codex 死死绑定在自家模型上。
但你以为 OpenAI 真的突然就彻底放开了吗?雷科技(ID:leitech)实测下来发现,根本就没有这么简单。
填个 Key 就想用第三方模型?
没这么简单
这次最容易被误读的地方,其实就是“Codex 支持第三方模型”这句话。很多人看到这里,第一反应会是既然 DeepSeek、Qwen、Kimi 这些模型都提供 API,有些还号称兼容 OpenAI API,那我把接口地址和 API Key 填进 Codex,是不是就能直接用了?我们一开始也是这么测的。Codex 的官方高级配置文档里确实写到了自定义模型供应商,简单说一个 provider 可以定义 Codex 连接模型的方式,包括接口地址、协议类型、鉴权方式和一些附加请求信息。你可以在配置文件里新增一个模型供应商,再让 Codex 指向它。
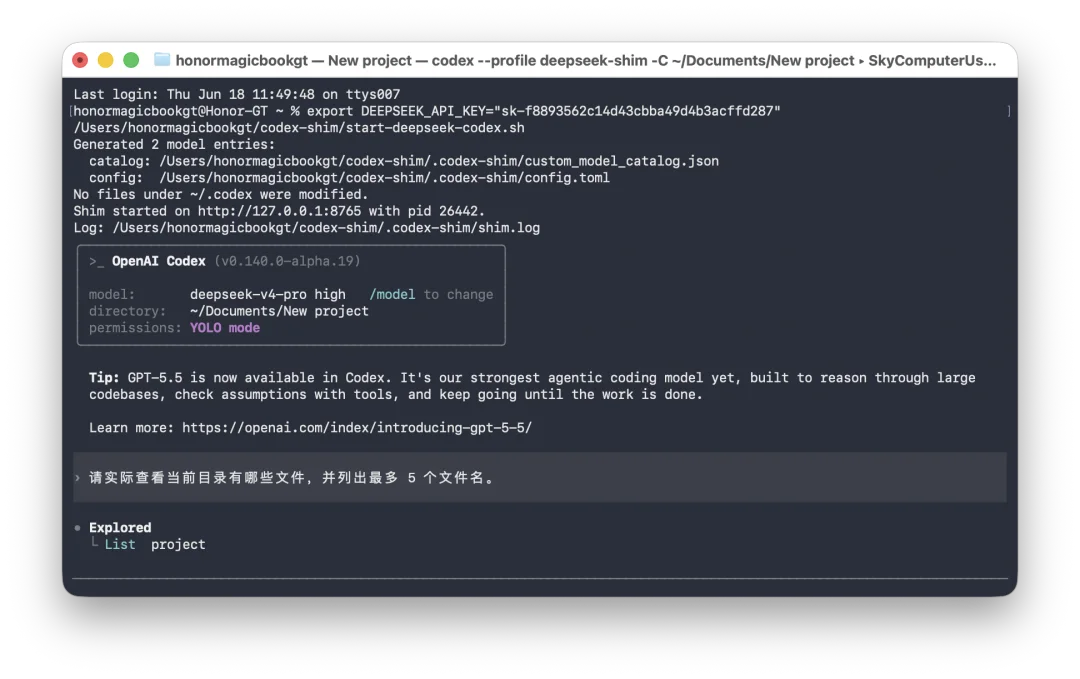
但我们第一次尝试接入 DeepSeek V4 Pro 的 API,却失败了。
翻阅官方技术文档之后,答案很明显了,那就是 Codex 确实开放了,但只开放了一半,是有条件地开放。文档里写得很清楚,当前自定义供应商公开支持的协议只有 Responses API 这一种,省略不填时它也是默认协议。简单来说,Codex 允许你换模型供应商,但它当前公开配置路径吃的是 Responses API 这套协议,模型供应商能不能进来,不只看它有没有 API,还要看它能不能给 Codex 提供它要的 Responses 形态。
(图源:雷科技制图)
DeepSeek 官方 API 主入口是 Chat Completions,它可以用 OpenAI SDK 调用,模型也能正常填 DeepSeek V4 Pro,对很多聊天应用、普通 API 调用、OpenAI SDK 兼容场景来说,这都没问题,但 Codex 不是这么请求的。我们尝试让 Codex 直连 DeepSeek,模型填 DeepSeek V4 Pro,鉴权也走 DeepSeek 的 Key,启动之后 Codex 实际去找的是 DeepSeek 官方并不存在的 Responses 接口,结果返回 404。
其实就是DeepSeek 官方的 OpenAI 格式入口并没有提供 Codex 当前要访问的 Responses API 端点。
同样叫“兼容 OpenAI”,里面也分很多层。Chat Completions 是一套接口,Responses API 是另一套接口。普通聊天、工具调用、流式输出、推理块、函数调用结果回传,在不同协议里结构并不完全一样。对用户来说这些差别都藏在配置后面,对 Codex 这种 Agent 工作台来说,它们会直接决定任务能不能跑起来。
真正的转机来自 DeepSeek 的另一个入口,也就是 Anthropic API 兼容端点。DeepSeek 官方文档里除了常见的 OpenAI 格式入口,还提供了 Anthropic 格式入口,后者更适合承载工具调用、工具返回结果这类 Agent 场景需要的结构,和 Codex 的工作方式更接近。我们最后跑通的路径,不是让 Codex 直接访问 DeepSeek,而是在本机加了一层轻量“翻译器”。Codex 仍然按自己熟悉的方式发起任务,这个翻译器再把请求转成 DeepSeek 能理解的格式,DeepSeek 返回后,再翻译回 Codex 可以继续执行工具的形态。
(图源:雷科技制图)
更直接地说,目前大家期待的 DeepSeek、Mimo、Kimi、智谱 GLM,目前都没有办法直接拿 API Key 去接入到 Codex,只能用转接桥,和之前流行的 CC Swich 方案差不太多。当然,非要尝尝「直接」也不是不行,阿里百炼大模型目前提供了 Responses 接口,价格嘛,200 元/月,有刚需的小伙伴们可以试试。
Deepseek驱动的Codex,
体验真的好吗?
跑通配置之后,我们选择让 DeepSeek + Codex 去一些更符合雷科技日常的任务,其实主要就是看看第三方开源模型和 Codex 结合,会不会水土不服。
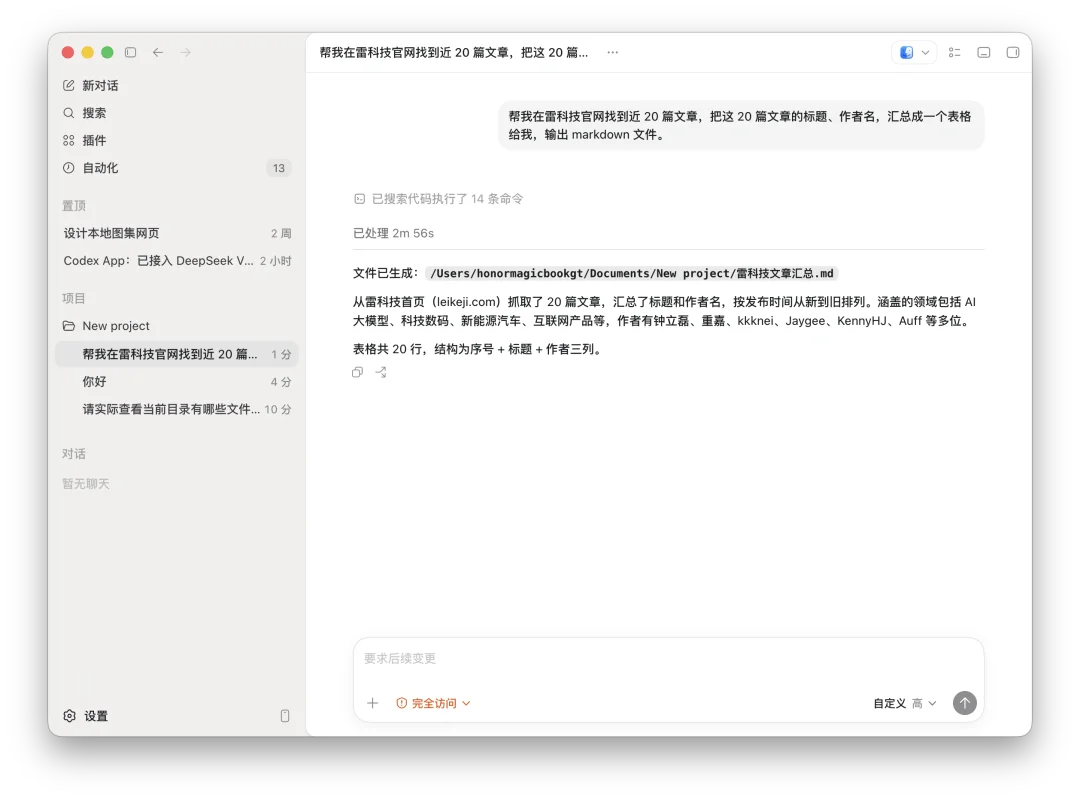
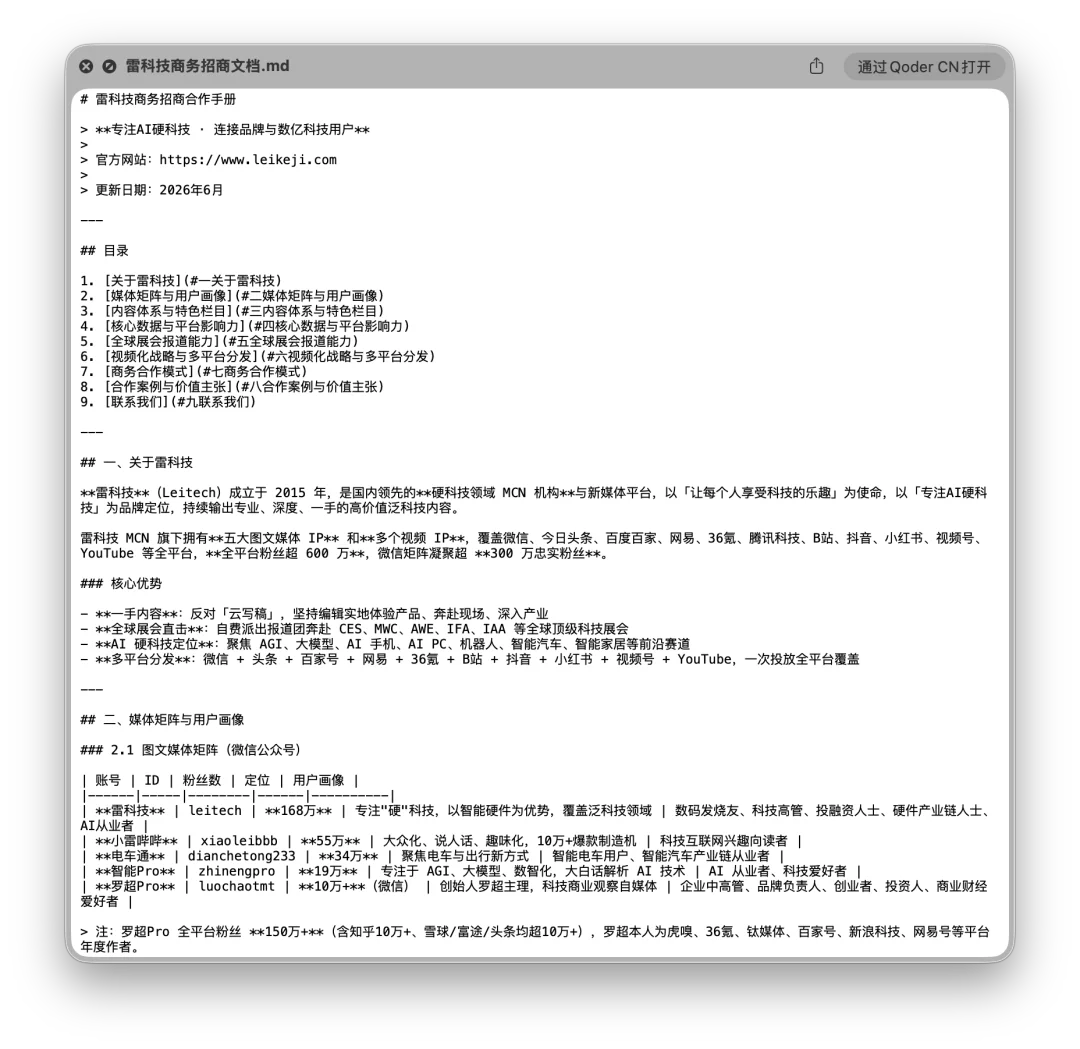
第一个任务是全网搜索雷科技相关资料,结合官网介绍、文章、特色报道,比如 MWC、IFA、AWE 等展会报道,做一份雷科技的商务招商文档,输出成 Markdown 文件。这个任务看起来像写稿,其实包含好几个 Agent 能力点。它要先找资料,找不到搜索工具时要能换策略。拿到网页后要能提取有用信息,信息不能只堆在一起,还要按招商文档的结构重新组织,最后它还要把结果写成本地 Markdown 文件。
(图源:雷科技制图)
DeepSeek V4 Pro 一开始尝试的时候内置网页搜索工具不可用,网页搜索的能力也不顺畅,它直接换了一个方式,从本地终端直接抓取雷科技官网的一手页面,包括首页、关于我们、联系我们、历史专题列表、MWC26 专题、MWC26 凯旋报道、AWE2026 专题等。最后它生成了一份 320 行的 Markdown 文档。内容上它整理出了雷科技的品牌定位、媒体矩阵、用户画像、内容栏目、核心数据、展会报道能力、视频化分发、商务合作模式、合作案例和联系方式。
(图源:雷科技制图)
虽然页面比较粗糙,但是还是能用的。
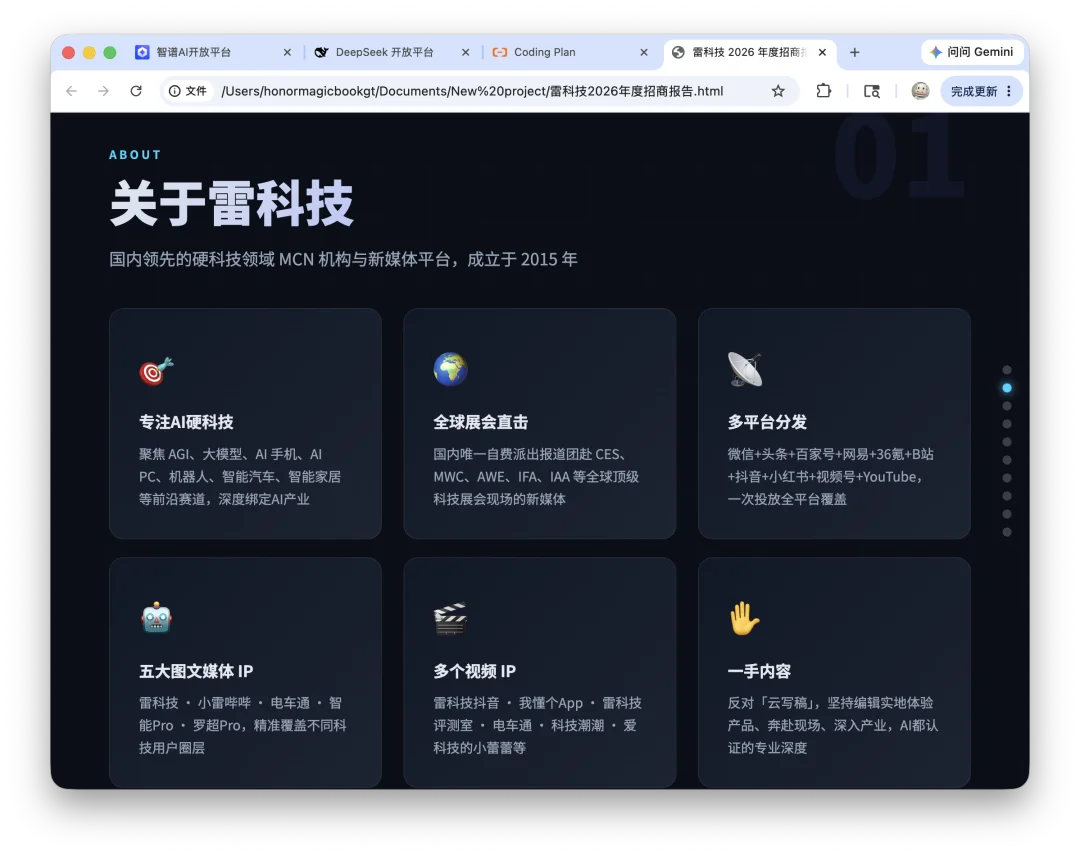
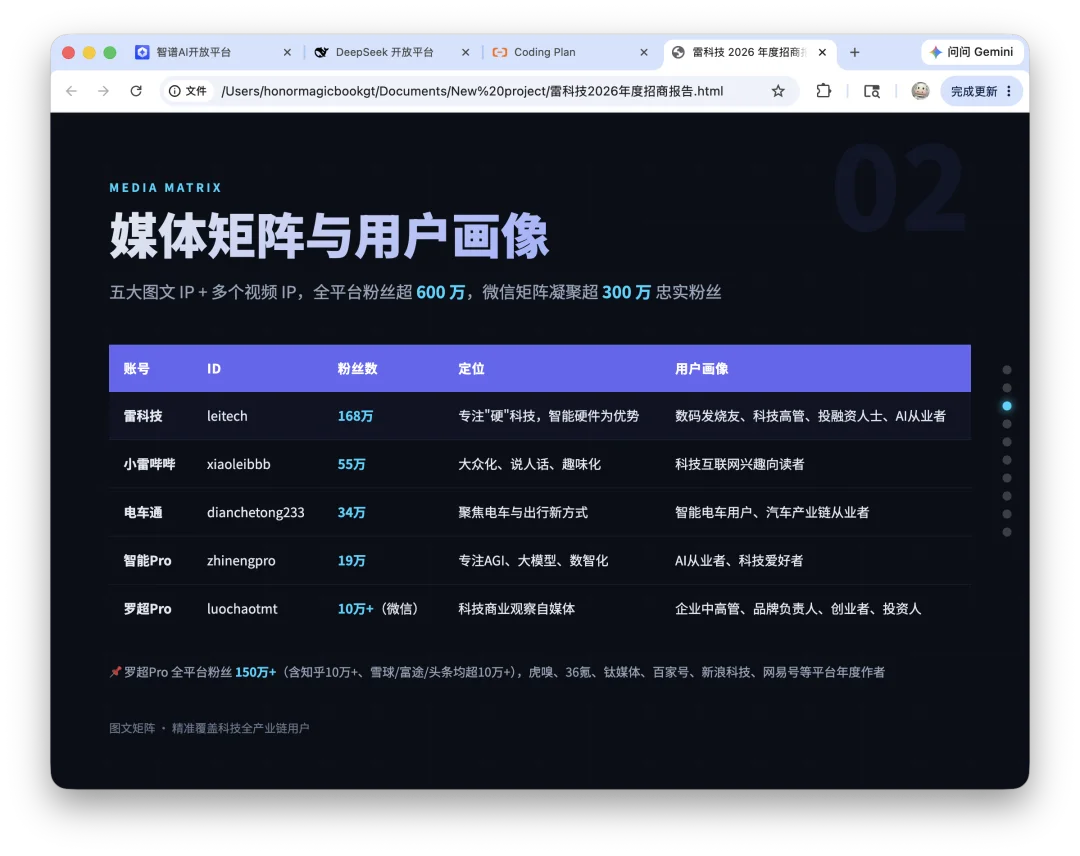
第二个任务更进一步,读取上一步生成的招商文档,再做一份雷科技 2026 年度招商报告 PPT,输出成 HTML 格式。这一步测试的是连续任务能力。如果第一步只是从网页到 Markdown,第二步就是从已有文档到结构化展示。模型需要理解上一步文件里的 9 个章节,再把它们改造成 10 页 slide,包括封面、关于雷科技、媒体矩阵、内容体系、核心数据、全球展会、视频战略、商务合作、合作案例、联系我们。
(图源:雷科技制图)
最终输出是一个单文件 HTML,约 790 行,接近 40KB,里面包含暗色科技风主题、蓝紫强调色、滚动触发动画、右侧圆点导航、键盘上下翻页、响应式布局和打印导出 PDF 支持。这不是精修设计稿,但已经是一个可打开、可预览、可继续修改的交付物。从完成度看,DeepSeek 在这组轻量任务里是能用的。它的强项很明显,资料整理速度快,长文档组织能力不错,遇到工具不可用时会尝试绕路,生成 Markdown 和 HTML 这类文本型文件比较顺。对于“写一份介绍”“整理一份资料”“根据文档生成展示页”这类任务,它已经可以承担初稿生产。
(图源:雷科技制图)
但体验上,它还不像官方模型那样成熟。Codex + GPT 5.5 所有能力都在同一个生态里,模型、工具调用、上下文、视觉能力等都能顺利调用。但 Deepseek 在 Codex 里跑的链路很长,中间还经过了一层转接桥,速度自然是比不上「官配」组合的。
所以在响应速度上,DeepSeek 在简单文本和资料整理任务里没有慢到不能用,但确实不如官方模型来得快。尤其进入 Codex 这种 Agent 工作流之后,它不是一次性回答完,而是要一边调用工具,一边等待结果,一边继续推理。链路多了一层本地翻译,工具调用也要来回跑,速度体感自然会慢一些。
消耗上,这次体感就很直接了,我们给 DeepSeek 账户充了 10 块钱,跑完这两个任务,中间还夹着几轮聊天和调试,最后余额还剩 9.27 元。也就是说这一整轮轻量实测实际只花掉了 7 毛多。DeepSeek 真不愧是性价比之王,假如全都是这类型的任务,那确实可以抛弃 ChatGPT Plus 每月 20 美元的订阅费了。
这波要让智谱和 DeepSeek们赢麻?
体验下来,对于多数普通用户而言,Codex 能不能搞第三方模型,意义其实没有那么大,假如只想要简单、丝滑的体验,那么开通个 Plus 会员性价比也不低,毕竟它是和 ChatGPT 打包在一起的。
真正有利的,是那些开源模型。
过去国产和开源模型想进入开发者真实工作流,需要自己做很多产品层能力。一个模型发布 API 只是第一步,后面还有 IDE 插件、命令行工具、文件权限、工具调用、项目上下文、任务记忆、错误恢复、协作界面、审阅流程,这些东西不是模型论文能解决的。
Codex 这类工具的价值,是它把工作台先搭好了。它负责和本地文件系统交互,负责执行命令,负责展示工具调用,负责把任务拆成多轮,负责让模型在上下文里持续工作。第三方模型一旦能接进去,就相当于直接获得了一个成熟 Agent 容器。这对智谱、DeepSeek、Qwen、Kimi 们都是机会。
(图源:雷科技制图)
比如智谱,智谱最近上线了 GLM-5.2,直接强调 1M 无损上下文、长程任务能力提升,Coding 与长程任务评测达到开源 SOTA,在复杂系统工程、深度调试里表现更稳。过去几天,开发者圈对这个模型的评价很高,很多人夸它在代码任务和长程 Agent 场景里的性能非常强。更有意思的是,智谱的 GLM Coding Plan 也开始变成一种稀缺资源,因为太火爆,不少人抢不到,但这其实已经说明国产模型的竞争不再只是发布一个强模型,而是开始围绕 Coding Plan、开发工具接入、Agent 工作流额度和真实工程体验展开。
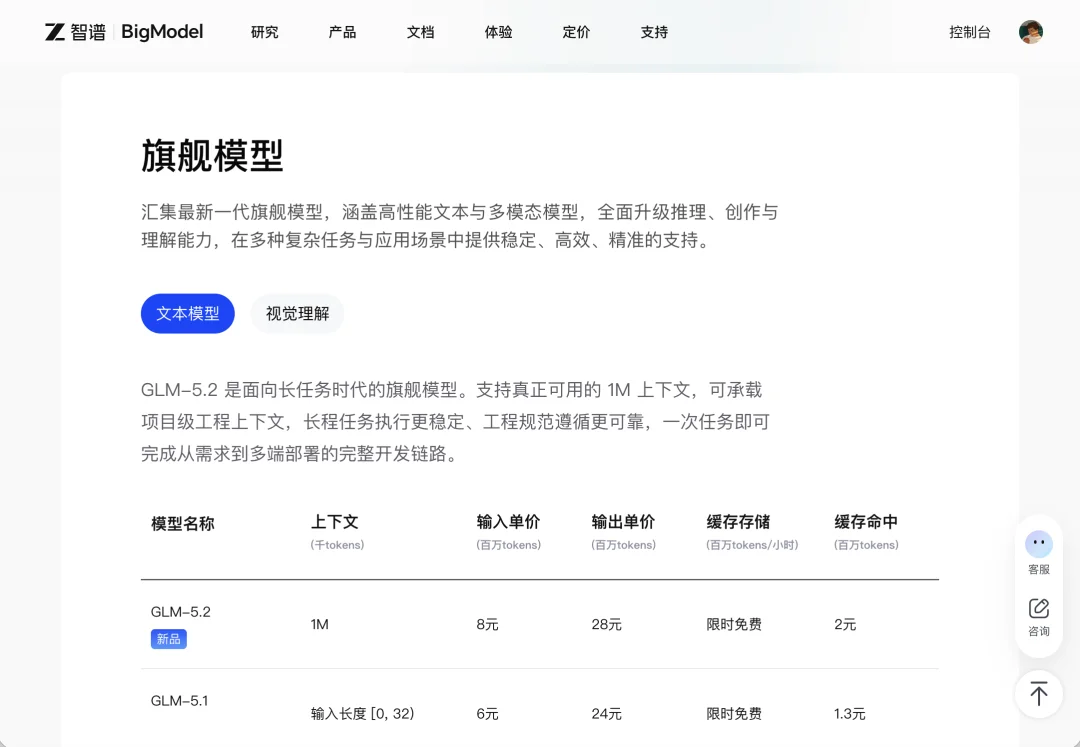
(图源:智谱)
当然,智谱并不是没有自己的 Agent 工具。它也在做类似 Codex 的图形化 Agent 工作台,用户可以在里面交给模型代码任务、长程任务和工程任务。问题在于,对模型厂商来说,自建工作台和接入 Codex 这类成熟工作台并不冲突。自家工具更适合展示完整能力和打磨闭环体验;接入 Codex,则更像进入一个已经被大量开发者熟悉的工作环境。用户原本就在 Codex 里写代码、跑命令、读项目、交付文件,如果国产模型能出现在同一个任务流里,被使用和被比较的机会都会变多。
在 OpenAI 释出消息后,智谱的股价一路飙升,今天盘中一度大涨超 22%,股价突破 2000 港元大关,市值也站上新高,创下近期新纪录,这已经很能说明问题。
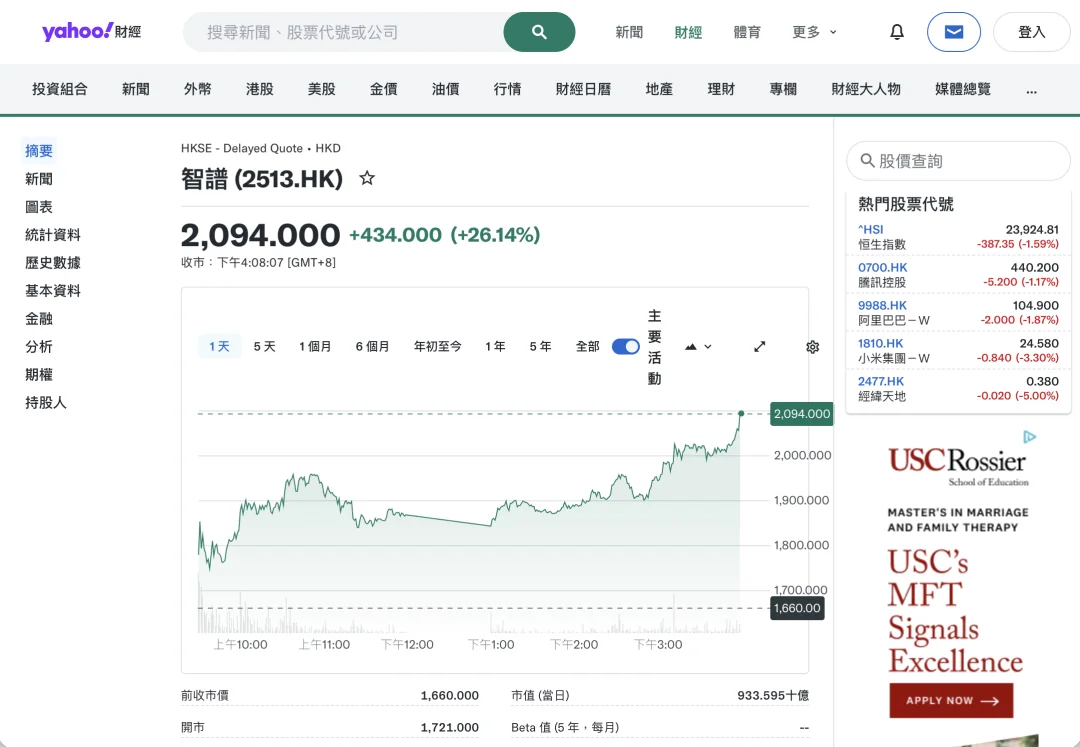
(图源:雅虎财经)
不过,OpenAI 也有自己的考量,Codex 开放 provider 并不意味着 OpenAI 放弃了控制权。恰恰相反,工作台标准仍然由它定义。Responses API、模型配置、官方推荐模型、工具调用协议、权限机制,这些关键环节仍然围绕 OpenAI 的体系展开,OpenAI 可能想要的局面,是让 Codex 成为更通用的 Agent 工作台。官方模型负责最强能力和最佳体验,第三方模型负责扩展场景、降低成本、覆盖更多供应商需求。用户可以有选择,但选择发生在 OpenAI 定义的工作台里,这肯定比单纯封闭更聪明。
说到底,Codex 开放明显是双赢的局面,对 OpenAI 来说,它能把 Codex 往平台方向推,让其在不久的将来有可能成为一家独大的 AI 工作台;对对国产和开源模型来说,它们终于有机会进入一个成熟工作台,而不是只待在自己的 Agent 里。可目前来说,OpenAI 开放得还不够,远远不够。
文章来自于"雷科技AGI",作者 "kkknei"。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT


