Fork 之外,工程深度依然能打。
6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。
关注纷至沓来,短短几天,仓库就收到了 9000+ stars、800+ forks、近 700 个 open issues / PR。然而舆论也很快出现分化,一波是对 Mimo Code 中 checkpoint-writer + 四层记忆这套工程设计的肯定,另一波则在追问,大厂为什么 fork 别人的项目,为什么 Mimo Code 有大量 issue 但合并率极低?
事实层面,Mimo Code 是一次基于 anomalyco/opencode 的 fork 不假,但挖开源码,仍然能够看到不少具有工程深度的真创新。可发布后的运营节奏,又确实让人很难判断,它到底是一款“实验 demo”还是“正式产品”。
这种定位上的模糊,或许是一个让我们静下来思考 Harness 以及开源这件事本身的契机,关于小米为什么要做 Harness,以及今天 Harness 的方向、流派、分歧与共识。
01
小米为什么要做 Harness?
这个问题本质上在聊,当一个 AI 公司选择去深耕 Harness 时,它到底在选择什么?
目前整个行业有这么几个方向:
- 做模型:攻坚底层模型能力(GPT、Claude、DeepSeek、MiMo)
- 做 harness / agent 架构:把模型接入真实工作流的运行框架(Claude Code、Codex、OpenCode、OpenClaw)
- 做应用:面向终端用户的 AI 产品(ChatGPT、Claude.ai、小爱同学、豆包)
其次还有做基础设施 / Infra(vLLM、LangChain)、训练数据和评测以及做芯片/算力的选择。
但对于综合实力较强的消费电子和互联网基因的公司,最相关的还是前三块,成熟的 AI 公司也都在努力地凑齐这三块拼图。对 OpenAI 来说,也就是 GPT 系列模型、扮演 Harness 的 Codex 和作为应用层的 ChatGPT。Anthropic 也是如此,Claude 系列模型、Claude Code 加 Cowork、APP 端等应用三者的组合拳。
原因很简单,如果没有自己的 Harness,模型就只能寄生在别人的 Harness 里,也许自己到头来只会是一个运营商。所以如果稍有余力,去探索 Harness 本身利人利己,不管怎么看都是一个相当明智的决定。
但重新做一套 Harness 架构可能需要数月的时间,直接在开源项目上做显然是更聪明的办法。
而 Mimo Code 遇到的最尖锐的质疑也来自这里,一个 OpenCode 的分支。
这种批评有没有道理?一半一半。
不成立之处在于,历史上几乎所有重要的开源项目,都是 fork 或站在前人肩膀上的。开源的本意就是促进行业繁荣与进步,这一整套机制的设计,都是为了让后来者不用从零开始写代码,嘲讽 fork 行为就是在嘲讽开源本身。
但另一方面,技术从来是很难孤立出来被单独看待的。Mimo Code 不是一个创业小团队或个人开发者做出来的项目,却吃尽了一个大集团的宣发红利。如果不是小米平台的公开渠道,它不可能在 5 天内做到 8800 stars(截至 2026-06-15)。流量、声量、媒体报道的讨论,全是平台带来的。
所以用大公司的渠道公开时,事情就不只是小团队的事了。公众面对的是小米,不是小米里的某几个人。这时候对方掏出一个基于 OpenCode 的 fork,难免会让以个人开发者为最大群体的开源社区感到一些愤愤不平。
到这里,需要先聊聊罚站了半天的男二,OpenCode。
OpenCode 是由 Anomaly Innovations 团队(前身为 SST 团队)开发的开源 AI 编码 Agent,采用 MIT 协议开源,截至 2026 年累计获得约 17.5 万 GitHub Stars。它定位为一个终端原生的 AI 编码助手,以单个 Go 二进制形式运行,能够直接读取和修改代码、执行测试、调用 LSP 获取语义信息,并完成 Git 相关操作。
OpenCode 最大的特点在于完全开源且模型无关,用户既可以接入 Claude、GPT、Gemini、DeepSeek 等主流大模型,也可以使用本地 Ollama 等模型,而不会被特定厂商绑定。
值得一提的是,OpenCode 的创始团队曾经历过一次分裂。创始人 Kujtim Hoxha 与后期核心贡献者 Dax Raad、Adam Elmore 在项目归属和商业化方向上产生分歧。随后项目发生分叉,Dax 和 Adam 在 SST/Anomaly 名下继续开发新的 OpenCode,而原项目则由终端 UI 框架公司 Charm 团队接管并最终更名为 Crush。期间社区还曾出现关于 Git 历史重写、贡献记录处理等争议讨论。
目前社区中实际上存在两个“OpenCode”项目,分别是已经归档的 opencode-ai/opencode,以及当前仍在活跃维护的 anomalyco/opencode。
那么它和大家熟知的 Openclaw、Hermes Agent 有什么区别呢?

简单来说:
- Claude Code:Anthropic 官方旗舰,闭源、和自家模型紧密耦合
- OpenAI Codex CLI:OpenAI 官方 CLI,半开源(壳子 Apache-2.0、模型闭源)
- OpenCode:上面两家的开源替代品,开发者需要的是一个不被一家锁死的工具
而回到我们的主角,Mimo Code 则有着 OpenCode 的骨架和 Hermes 的灵魂。他们选择了 OpenCode 终端编码 Agent 的形态,并加上了 Hermes 风格的进化机制,比如 dream/distill 提炼记忆和技能,本质上是在两个开源思路上做集成与落地。
我相信 Mimo 团队一定有过很深刻的思考和改进,因为源码看完后确实能发现很多创新。
02
计算、记忆与进化,MiMo Code 的惊喜
这种创新基本上围绕三条主线展开。
首先是计算。Max Code 的设计确保 Mimo Code 能够把事情做对。这套机制在每一轮决策时并行生成 N 个候选方案(默认 5),由同一个模型作为 judge 选最优执行。用 4-5 倍 token 消耗的代价,换来 SWE-Bench Pro 上提升 10-20% 的回报。这是个实验性的功能,需用户手动开启(experimental.maxMode: true)。本质上的判断是用算力换可靠性。
此外,长程复杂任务交付质量,有相当一部分取决于 Agent 对于何时应当结束进程的判断。Mimo Code 支持用户用自然语言设置停止条件(如"所有测试通过且代码已提交")。主 Agent 每次想终止时由独立 judge 模型审查任务“是不是真做完了”。
Claude Code 也有类似的设计。不过它把这项任务交给主 Agent 自主判断,Mimo Code 则显式分离做事的 Agent和验收的 Agent。
第二个主线是自我进化,这也是 Mimo Code 创新点最多的地方。
基于 Harness 的自我进化能力,无外是对任务历史进行复盘和整合,输出可复用的 skill 或 SOP 等产物,Mimo Code 也是根据这一思路上尝试落地。
其自我进化能力主要来自两个方面:
- Dream:每 7 天自动跑,整理记忆(合并去重、路径验证、压缩)
- Distill:每 30 天自动跑,识别重复工作模式,固化成可复用的 skill / CLI 命令 / 自定义 Agent / SOP
这对于我们的测评有点尴尬。Dream 是 7 天周期、Distill 是 30 天周期,都不是一周以内的短期测评可以跨越的,因此只能看机制设计,没发看实际效果。当然这也不算 MiMo Code 故意挖坑,长周期自进化的设计天然就有这种可验证性问题。但效果延后这件事也意味着,如果团队半年内停止维护,这部分功能就成了从未真正运行过的代码。
除了源码,Mimo Code 还有一个技术亮点值得关注。
README 没提到的是,Mimo Code 中的 checkpoint-writer 是 fork agent。它在 spawn 时从父 agent 冻结了完整的 LLM request prefix(系统 prompt + 工具定义 + 已有消息),存为 ForkContext。同时它会共享父的 KV cache,也就是说 checkpoint 写入时不需要重新计算已有上下文,这导致其 token 开销远比想象的低,这是真正的工程创新。
简单来说,传统做法里,派一个子 Agent 写 checkpoint 时,子 Agent 是独立的,要把已有的 100 轮对话从头再读一遍才能写总结。但其实主 Agent 早就读过这 100 轮,读完之后还留下了一份昂贵的中间计算结果,叫 KV cache。MiMo Code 的做法是,checkpoint-writer 这个子 Agent 在派出来的那一刻,直接继承主 agent 的 KV cache、系统 prompt、工具定义、所有消息(这个完整快照在源码里叫 ForkContext)。它不需要重读历史,醒来就站在主 Agent 此刻的“理解”上写总结。
这件事的意义不仅在于省了多少 token,而在于它让 checkpoint 从一个昂贵、少打的事件变成廉价、可以频繁打的常态。也正因为它便宜,MiMo Code 才能在 20%、45%、70% 这三个早期点位主动打 checkpoint,而不是等到 90% 上下文快爆时再仓促压缩,那时候模型已经在长上下文中段 lost in the middle 了。
普通的 subagent 架构,做不到这一点。
最后一点则是记忆。Mimo Code 的记忆系统被划分为四个层级:
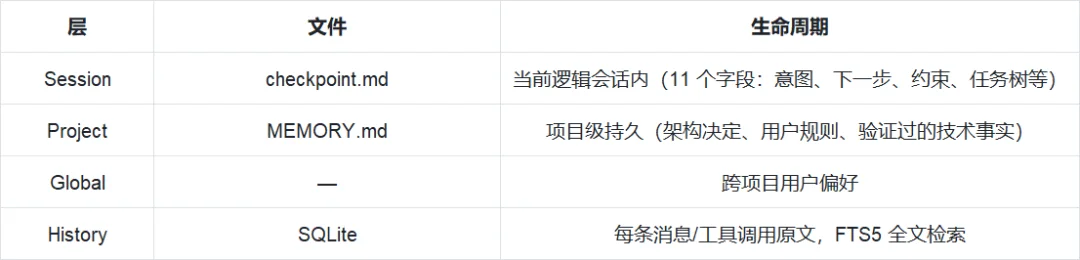
值得一提的是 cycle 机制。当上下文窗口快满时,Mimo Code 会派 writer subagent 把状态写入磁盘,窗口接近上限时执行 rebuild,切断当前窗口、用持久化文件做种子重建。一个“checkpoint 打点 + rebuild 收尾”的轮次序列叫一个 cycle,cycle 数没有上限。
checkpoint 触发位置设计也很有讲究,分别被设置在了配置预算的 20%、45%、70% 处。之所以不等到窗口快满才触发,时因为考虑到了高利用率下模型能力衰减的问题。这一套机制,共同保障了 Agent 在超长上下文任务中的连贯性。
不过关于无限上下文,一个必须澄清的事实是,技术上任何 Harness 框架都无法突破底层 LLM 的物理 context window。Claude 200K、DeepSeek 128K、Kimi 200K,这一点由模型架构决定。MiMo Code 接哪个模型,物理上下文就是哪个模型的上限。
框架不生产上下文,只搬运上下文,这是工程师层面的常识,也是宣传话语最容易模糊的地方。
工程上,MiMo Code 确实做到了有效的创新,比如此前我们介绍过的 checkpoint-writer,在 spawn 时冻结父 Agent 的完整 LLM request prefix、共享父的 KV cache,让“写 checkpoint”这件事的 token 开销远低于常规子 Agent。
当物理窗口快满时,Agent 把当前状态压进 11 个结构化字段(意图、约束、任务树等),新窗口用这些字段做 rebuild 继续工作。这套机制实现的是逻辑会话无限延伸,一个目标可以跨越任意多次物理窗口,对用户视角接近无感。体验上,这还是有损压缩,只是可能不影响使用。
主线意图、关键决定、当前任务树这些被 checkpoint 直接覆盖的内容跨窗口大概率保得住,具体的实现细节、试错过的方案、对话语气这些不在 11 个字段里的信息,按 checkpoint 写得好不好浮动,简单线性任务接近真无限,复杂分支任务必然有信息流失。
任何压缩都是有损的,没有例外。这不是 MiMo Code 一家的问题,是所有 Harness 共有的工程边界。
说到底,“上下文”到底是一个可以自定义的词汇,还是行业的宣传用语,业内到底有多少自定义空间?老实说,这个词汇确实有精确的定义,但是越往上走越模糊。
在 Transformer 论文层的定义是最精确的。sequence length(Transformer 原论文里的物理量 n)和 context window(GPT-3 论文里的超参数 n_ctx = 2048)都有严格数学定义,即一次 forward pass 里 self-attention 能看到的 token 总数。这是物理量,能用数字写在论文里。

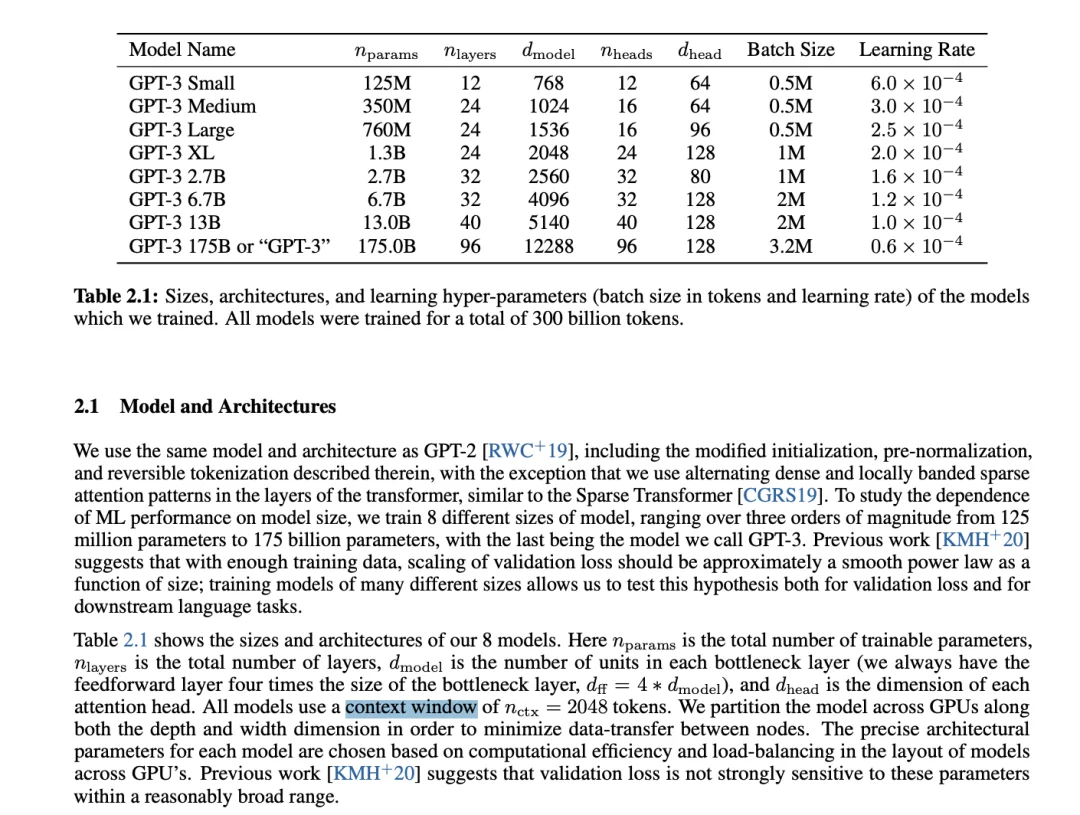
在 LLM 工程层,定义仍然清晰。很多模型的 API 文档里写的“context limit: 200K tokens”也是精确的,对应模型架构决定的硬上限。
但到了 Agent 框架层,上下文的定义就开始模糊。一旦涉及 multi-turn、external memory、retrieval、checkpoint,“context”这个词就不再是单一物理量。它可能指“模型本次能看到的”,也可能指“Agent 整个会话累积感知的”,也可能指“用户体验上感觉记得住的”。
直到在营销层,甚至出现故意模糊上下文含义地做法。“infinite context”、“unlimited memory”、“total recall”这些词都是利用了上面那种模糊性,把工程层的“逻辑延续”和 transformer 层的“context length”故意混淆。
所以「上下文」这个词在底层是被严格定义过的,但当它从 transformer 论文到营销文案时,每走一层,就会更模糊一些。
行业里其实有更精确的替代术语,persistent memory、session continuity、context compaction、retrieval-augmented context。每一个都是可被工程师审查的,问题只是不够性感,满足不了今天模型厂商的传播需求了。
03
Harness 的方向在哪里
都聊到这里了,我们跳出 MiMo Code 单点,俯瞰一下主流 Harness 的流派和分歧。
说到底,所有人做 Harness 都在解决一件事,Agent 在长任务里会失效。基于这个问题,大家分成了五大流派:
卷上下文长度。Claude 1M、Gemini 2M、DeepSeek V4 1M 的选择是把窗口做大。这是既然记不住就扩容的逻辑,但代价是计算成本指数级上涨,模型在长输入中段会“lost in the middle”,给 100 万 token,只看清头和尾。
卷压缩。智能摘要、上下文管理是 Claude Code 的主要打法,有限窗口内做“压缩与管理”,自动 compact 把旧消息变摘要。既然不能扩容,就把“垃圾”都扫走,此时摘要质量会决定一切,一旦摘错就丢关键信息。
卷计算,用更多算力换可靠性。MiMo Code 的 Max Mode 就在走这条路,Best-of-N 采样、judge 模型、多 Agent 投票都是这套“单次答错,就跑多次取最好”的逻辑。代价也显而易见,token 消耗会呈几倍的增长。
卷自进化。让 Agent 从历史里学经验,把重复模式固化成可复用资产。这条路上 Hermes 是代表,MiMo Code 的 Dream/Distill 走的也是这个路径。如此 Agent 不必在每次接到一个任务的时候都从头再来,但抽象化能力完全依赖 judge 模型时,提炼出现错误也会污染未来的表现。
卷工程基础设施。权限、安全、恢复、工具路由……这也是 Claude Code 重点关注的地方。此前社区对 Anthropic 2026 年 3 月意外泄漏的 Claude Code 源码(约 51.2 万行 TypeScript / 1906 个文件)的逆向分析显示,真正属于“AI 决策逻辑”的代码只占 1.6%,剩下 98.4% 都是确定性基础设施,包括权限管理、上下文管理、工具路由、恢复逻辑、7 层安全机制。Agent 循环本身只是简单 while。
对于 Harness 来说,这是一个格外有意义的洞察,即模型可以替换,但围绕模型的工程系统不能。当然,从前面的代码比例也能看出来,这是一个爆炸级的工程复杂度,难以复刻。
所有 Harness 的存在都基于一个共同的判断,仅模型自己变强是不够的。如果模型性能每年攀升一倍,根本没人需要这么复杂的 Harness。所有 Harness 的存在都是在赌,“未来很长一段时间,模型还不够好,所以围绕模型的工程会决定上限”。这是 Anthropic 和 OpenAI 在做的事,也是小米想做的事。
这样押注合不合理另说,但它解释了为什么 Harness 这条赛道突然挤进来这么多公司。
如果说大模型是脑子,那 Harness 架构就是性格。当智力水平无法左右,我们仍然可以在成长过程中打磨性格。良好的性格,经常能弥补脑子不够用带来的缺陷,这怎么不是一种肉体超频呢?也许大模型和 Agent 架构也是这个关系。
OpenCode 之所以火爆,与其说是“好的架构能榨干模型”,不如说是它在 Claude Code 闭源、Cursor 收费的窗口期精准踩中了“完全开源 + model-agnostic + 终端原生 + 部署简单”这个市场空白。开发者要的不是更卷工程的 Harness,是一个不被一家锁死的工具。OpenCode 本身没有特别“卷压缩”或“卷计算”的设计,它的优势是“通用/灵活/开源”,不是工程上的精妙。
那问题就来了,Mimo Code 做的这些创新,为什么 OpenCode 自己不做呢?
在持久记忆的优化方面,社区其实已经呼吁了半年,但 OpenCode 团队基本都拒绝了。这构成了 MiMo Code 介入的真实空白。也许 Mimo Code 真的是苦天下久矣。
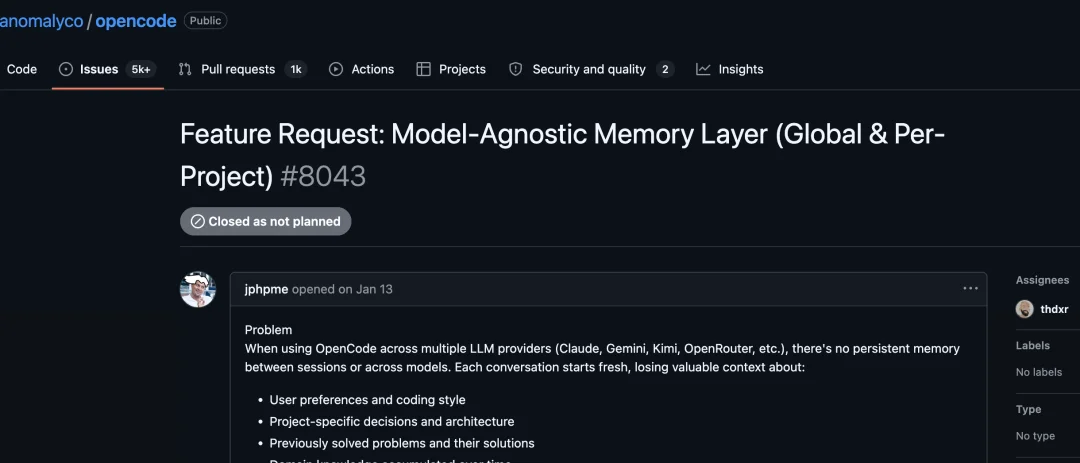
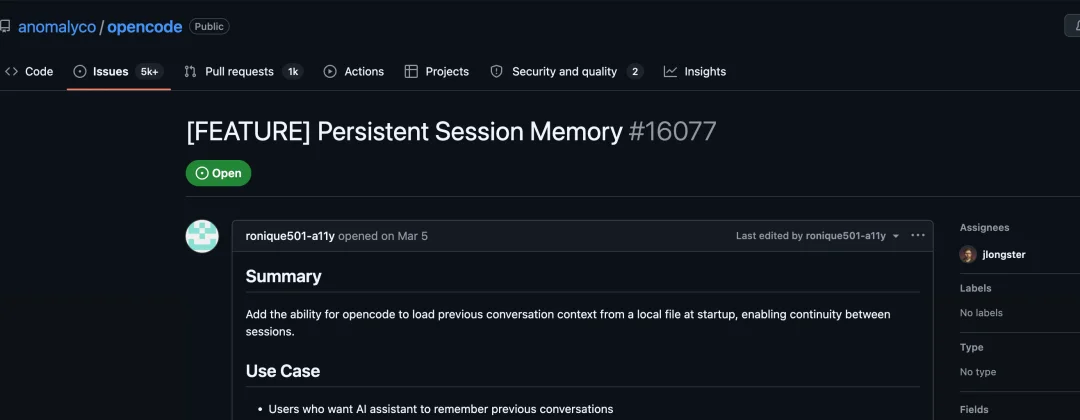
但要补充的一个的事实是,OpenCode 整体仓库其实非常活跃,每天有 release、有完整的 fix 体系、多人 maintainer 在 review PR。只是在持久记忆/跨 session 状态这几个特定方向上,团队明确决定不做(issue #8043 持久记忆层被官方 closed as not planned,#16077 跨 session 记忆 open 着但官方零参与)。社区被迫自己动手开发了一些第三方插件:
kuitos/opencode-claude-memory:给 OpenCode 加 Claude Code 兼容的记忆系统ApplauseLab/opencode-plugin-simple-memory:持久记忆插件- 各种 MCP server 形式的"外挂记忆"(Vestige 等)
所以可以这么说,MiMo Code 是基于社区呼吁了半年、OpenCode 官方明确不计划做、用户只能靠第三方插件凑合的真实需求。
04
fork it till you make it
前面我们提到,为什么大家会对 fork 这件再正常不过的开源行为这么抵触?这和 OpenCode 主动放弃的优化方向联系在一起看待,会更有意思。
本质上,社区反感的从来不是 fork,而是用 fork 的工作量换原创的关注度。Mimo Code 的工程深度毋庸置疑,但引起争议的,是劳动和回报的不对称感。
OpenCode 明确表示不会在持久记忆层等方向上投入精力,但需要强调的是,OpenCode 项目依旧非常活跃,每天上千个 issue 仍在被持续处理。
虽然说 Mimo Code 获得的 issue 和 PR,相比 OpenCode 是海量的,但如果从客观的合并率来看,OpenCode 第一周里有 64% 的 PR 被 merge,多数是 fix 和 feat,MiMo Code 第一周里只有 0.7% 的 PR 被 merge,全是文档和二维码。流量差 19 倍可以解释 issue 数量,但解释不了合并率 91 倍的差距。
把视野再拉长。OpenCode 至今仍在每天发 release(4 个月发了 100+ 个版本,截至 6-17 是 v1.17.7),6-17 当天还在 push commit,过去 7 天合并 62 个 PR。反观 MiMo Code,6 天里只发了 v0.1.0 和 v0.1.1 两个 release,且 v0.1.1 的 release notes 正文只有一行字 “MiMoCode v0.1.1”。
横向对比 OpenClaw、Hermes 这种小团队 maintainer 的项目,社区运维都比 MiMo Code 体面:
- OpenClaw 有 priority 标签体系、有 changelog、定期 release notes
- Hermes 有 contributor 引导、明确的 issue triage 流程
MiMo Code 的运维节奏,比这些独立小团队还差一截。
所以不得不问的一个问题是,Mimo Code 到底在开一场发布会,还是在做一个踏实的开源贡献?
开源社区的长期契约是,我打算把这个东西做好、做长,欢迎你加入和我一起共创。持久记忆这种需求,即使社区呼喊半年,OpenCode 仍然明确表示 not planned。MiMo Code 接住了 OpenCode 没接的需求,但看起来接住后,它自己也没接住自己。
一个完整的回旋镖出现了。出于看不下去原作者不维护的姿态,Mimo Code 接管了一段路,但自己接管之后,又变成了下一个原作者。而 MiMo Code 是基于 fork 的,如果一个 fork 项目连后续维护都做不好,那它的存在意义就只剩在某个时间点公开了一些有趣的工程想法。这是 demo,不是产品。
我相信内部肯定在努力迭代,但维护不等于开源维护。享受公开的收益和关注,但回避公开的成本,比如迭代只放在内部做,做好再发出来,那也不难理解开源社区的个人开发者略有不爽的原因,github 仓库不应该是谁家的广告牌。
截止目前最新的项目情况,合并的 PR 几乎全部来自内部团队,社区贡献基本没被接纳。
也就是说,6 月17 号之后那波“功能性 PR 大量合并”的活跃,本质是内部团队把自己的开发工作通过 PR 流程合进主干,不是在吸纳外部贡献。从作者名(带 -xiaomi/-Mimo/MiMoHardFather)也能直接看出来。
更准确的定性是:这是一个“闭环的内部开发恰好放在公开仓库里”,更接近 build in public,而不是 open collaboration。 开源社区那条“欢迎你加入和我一起共创”的契约,仍然没兑现。内部团队把社区当 bug 上报渠道和测试用户,而不是协作者。
内部 PR 合了 28 条、社区 PR 只合了 1 条(还是发布当天的文档 URL 修正);社区送来的 Windows、暗色模式、Termux、竞态修复等十几个 PR 挂着没合,团队却用自己的内部 PR 重新实现了其中一部分(如重复检测)。
其实从哪个角度看,这件事都有更稳重的做法。比如先内部迭代、小范围 alpha 邀请制、厚积薄发再公开,或者更简单,把 checkpoint-writer 这个真正有工程深度的设计先写成一篇 ArXiv paper 发出去,让整个圈子讨论 idea,团队暂时不承担产品维护责任。Anthropic 和 DeepMind 经常这么做,在社区赢得的尊重程度反而比发产品更高。
否则现在这个仓促上线的姿态会让人很难判断,团队究竟在做什么。是想推动行业重视长任务记忆这件事,是想给团队挣个行业影响力,还是只是又一次抢窗口期、抢首发的 KPI 动作?
三种解释都站得住一半,但三种加起来又都站不住。
但话说回来,当你站在岸上批评游泳者的姿势时,你看不见水里的真实阻力。MiMo Code 团队看 OpenCode 时,他们看到的是原作者不做长期记忆,但他们没看到的是 OpenCode 团队也面对过同样的激励、同样的公共品困境、同样的资源约束。
他们以为自己会做得更好,是因为他们站在岸上。但当他们跳下水之后,现实扑面而来了。现实是发布有 ROI 而维护没有,社区只想用不想做贡献的搭便车困境仍然存在,团队五个人,模型每两个月更新一代的资源压力无时不在。大家是一样的人,只是处境不同。
在工程深度之外,Mimo Code 给所有产品团队提的一个醒是,想明白你我到底在水里还是在岸上。
文章来自于"AI科技评论",作者 "rain"。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


