本文第一作者曹巍为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)信息科学博士生,师从刘垚垚教授,研究方向为 3D/4D 重建与可控视频生成,现于 Stability AI 研究实习。本硕毕业于慕尼黑工业大学,已在 SIGGRAPH、CVPR、TPAMI、CoRL 等顶级会议与期刊发表多篇论文。本文由 UIUC、宾大与 Netflix Eyeline Labs 合作完成,并获 CVPR 2026 Workshop on Generative Models for Computer Vision 最佳论文奖。
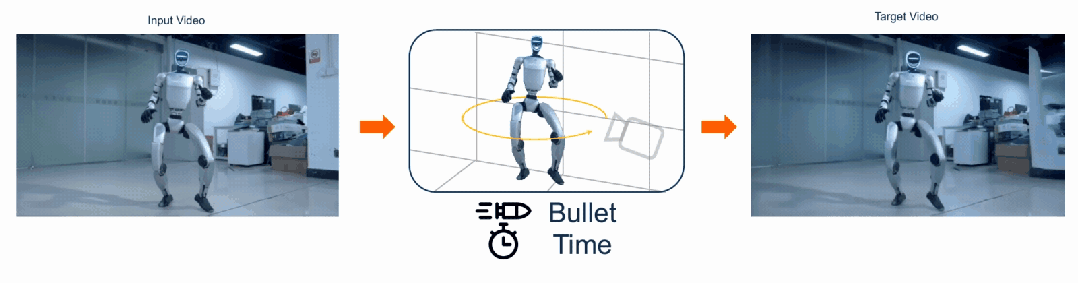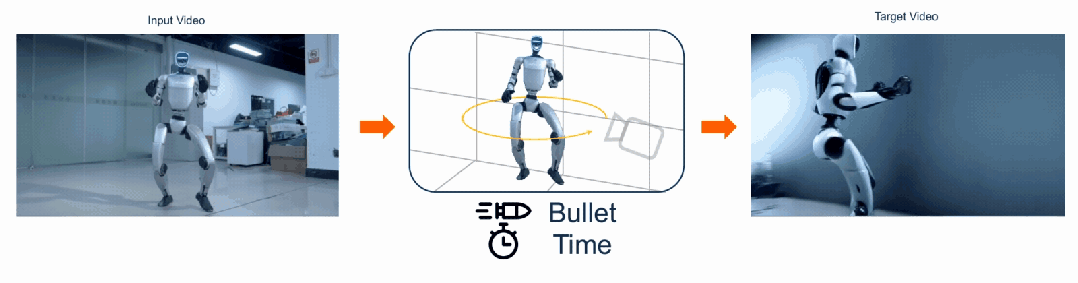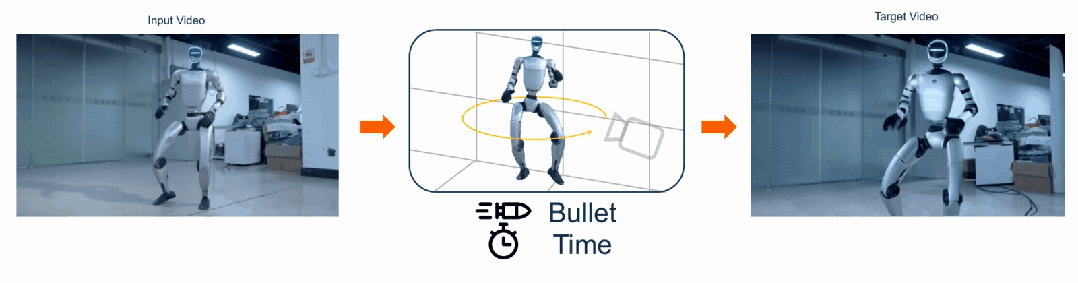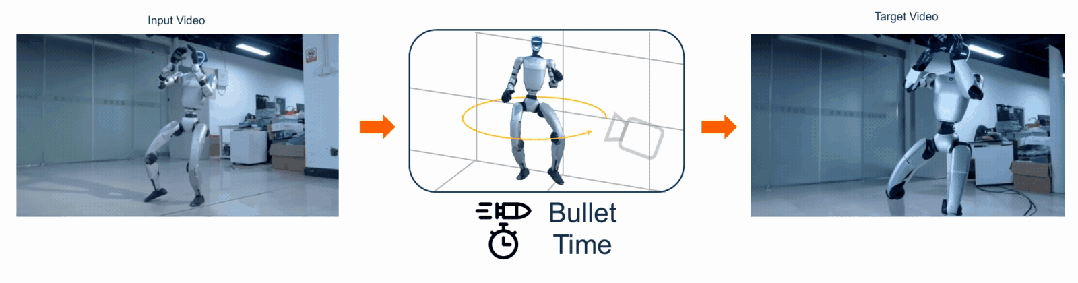
给定一段普通单目视频,FreeOrbit4D 可沿任意指定相机轨迹「重拍」整个动态场景,包括影视级的「子弹时间」环绕镜头。
《黑客帝国》那个经典的「子弹时间」镜头,当年要上百台相机围成一圈才拍得出来。二十多年后的今天,影视工业做自由视角回放,依然离不开昂贵的多相机阵列。
那么,能不能只用一段普通的单目视频 —— 手机随手拍的那种 —— 就让相机「飞」到场景的侧面、背面,甚至绕着主角转一整圈?
来自 UIUC、宾夕法尼亚大学和 Eyeline Labs 的研究团队给出的答案是:可以,而且不需要训练任何模型。他们提出的 FreeOrbit4D,通过「前景补全的 4D 重建」为视频生成提供几何支架,在 120°、甚至 180° 的大角度视角变化下,依然能生成几何稳定、时序连贯的重运镜视频。
该工作已被 ACM SIGGRAPH 2026 接收,并刚刚摘得 CVPR 2026 Workshop on Generative Models for Computer Vision 最佳论文奖。

- 论文:FreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Foreground-Complete 4D Reconstruction
- arXiv:https://arxiv.org/abs/2601.18993
- 代码:https://github.com/VVeiCao/FreeOrbit4D
- 主页:https://freeorbit4d.vision.ischool.illinois.edu/ (含可交互 4D 在线 demo)
三个看点
- 完全免训练。 整套框架不训练、不微调任何模型,由现成预训练模型与经典几何算法组合而成,自然也不需要昂贵稀缺的 4D 配对数据,单张 NVIDIA A40 即可跑通全流程。
- 大角度运镜不崩坏。 在 120°/180° 大角度轨迹上,VBench 六项指标拿下五项第一;用户研究中运镜准确度 4.5 分(5 分制),大幅领先次优方法的 3.5 分。
- 显式 4D 表示「白送」一串应用。 编辑一帧即可全片传播、直接缩放或合成 4D 几何、为下一代 4D 模型生成训练数据,都顺手可做。
为什么「重新运镜」这么难?
这个任务叫相机重定向:给定单目源视频和一条用户指定的相机轨迹,生成同一动态场景在新轨迹下的视频。它的本质困难在于 —— 严重病态。一段单目视频只是动态 3D 世界的一条「窄缝」,只记录了某个视角、某个时刻可见的表面。要从任意视角回放整个场景,模型必须从这极有限的观测中,恢复出几何一致、运动连贯的完整 4D 世界。
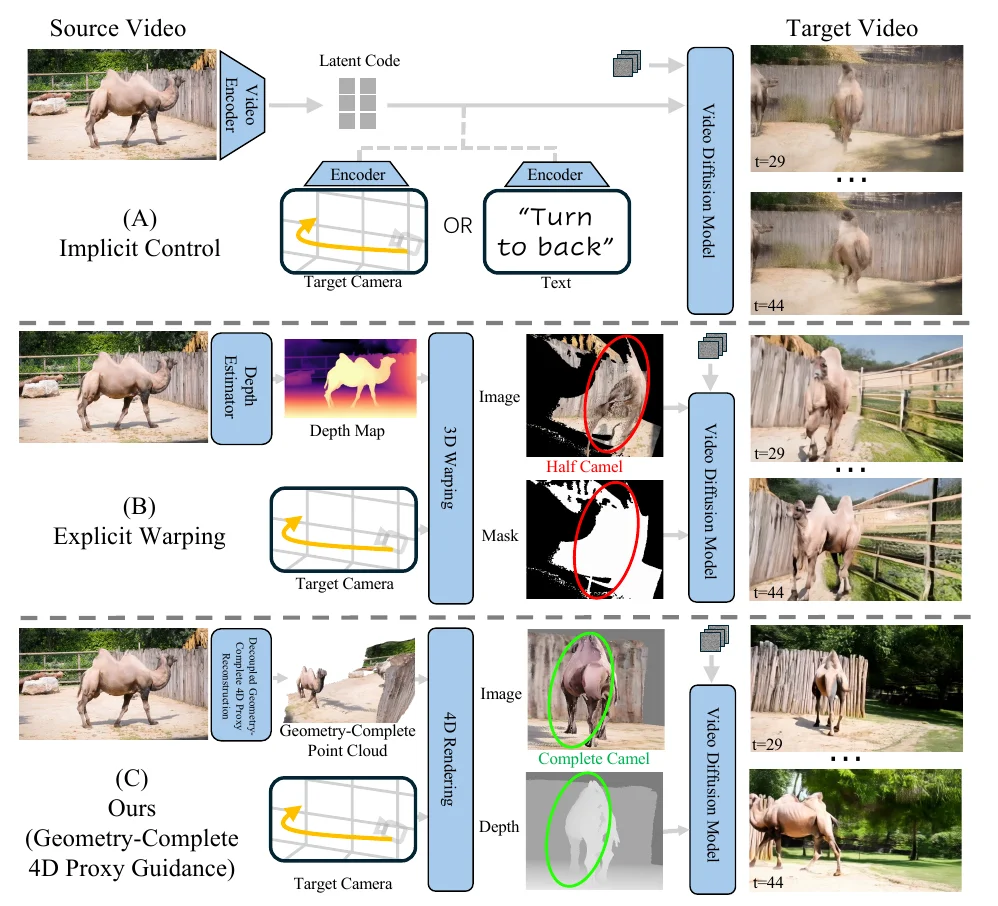
现有方法大致两条路线。隐式控制(如 ReCamMaster)把相机轨迹编码成可学习的嵌入或文本提示,控制力却很「软」:文本描述不了复杂轨迹,学到的条件经常不听指挥,而且训练要靠昂贵的配对数据。显式变形(如 TrajectoryCrafter、GEN3C、EX-4D)先估深度、再把可见像素「搬」到新视角,相机控制精确了,但单目视频里只有可见表面 —— 相机一转到侧后方,被遮挡区域就成了大片空洞,只能靠生成模型凭空脑补,结果往往是几何扭曲和语义漂移。一句话:隐式「指哪不打哪」,显式「转过去就穿帮」。
方法:把「看不见的那一半」补出来
FreeOrbit4D 的核心思想很直接:与其让生成模型凭空脑补,不如显式地把完整 4D 几何重建出来,再用它作结构支架引导生成。这就像电影特效 —— 先把演员完整扫成 3D 替身(哪怕只拍到正面),放回舞台准确位置,再让虚拟摄影机沿任意轨迹重拍。
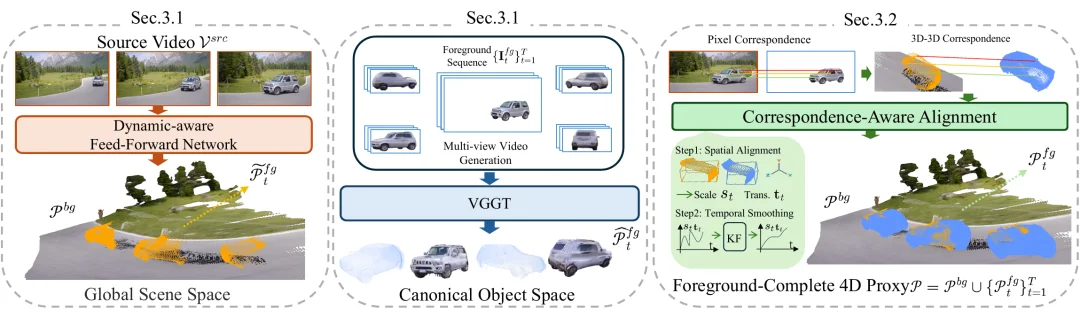
实现的关键,是一个重要观察:「重建动态场景」和「补全物体几何」是两个本质不同的任务 —— 前者要时序一致的场景级推理,后者要对物体形状的多视角理解,强行用一个模型同时做、两件都做不好。于是流程被解耦为三步:
①解耦 4D 重建。在全局场景空间,用动态感知前馈网络把视频提升成统一点云,再用 SAM2 掩码拆出静态背景与「只有可见面」的部分前景;同时在规范物体空间,把抠出的前景序列喂给物体中心的多视角视频扩散模型,合成 4 路相隔 90° 的环绕视频,由 VGGT 从 5 个视角重建出几何完整的前景点云 —— 被遮挡的「另一半」就这样补了出来。
②对应感知对齐。两套前景点云源自同一帧源图,同一像素对应同一表面点,由此直接得到稠密 3D–3D 对应,无需特征匹配。对齐时只用全局点云确定物体「放哪、多大」,完整几何形状原样保留,再用双向卡尔曼滤波平滑运动轨迹,消除单目深度的逐帧抖动。最终得到统一的前景完整 4D 代理。
③几何条件生成。沿目标轨迹渲染 4D 代理,得到每帧深度图;深度图连同源视频首帧(外观参考)一起输入深度条件的视频扩散模型,即可生成既严格跟随相机轨迹、又忠实源视频外观的目标视频。全流程不训练任何新模型,模块化设计还意味着任一上游模型升级,整个系统都能「免费」受益。

方法实拍:源视频(左)→ 沿目标轨迹渲染的深度支架(中)→ 深度条件生成的重运镜视频(右)。
实验:大角度轨迹下全面领先
团队在 DAVIS 真实视频、网络视频以及合成视频上评测,目标轨迹含 120°、180° 极端偏转 —— 正是现有方法最易「翻车」的区间。

街舞序列对比(快速肢体运动 + 复杂人群背景)。基线普遍出现肢体模糊、重影、几何畸变与语义漂移;FreeOrbit4D(绿框)全程保持锐利细节与稳定几何。
自动指标:VBench 六项中五项第一。
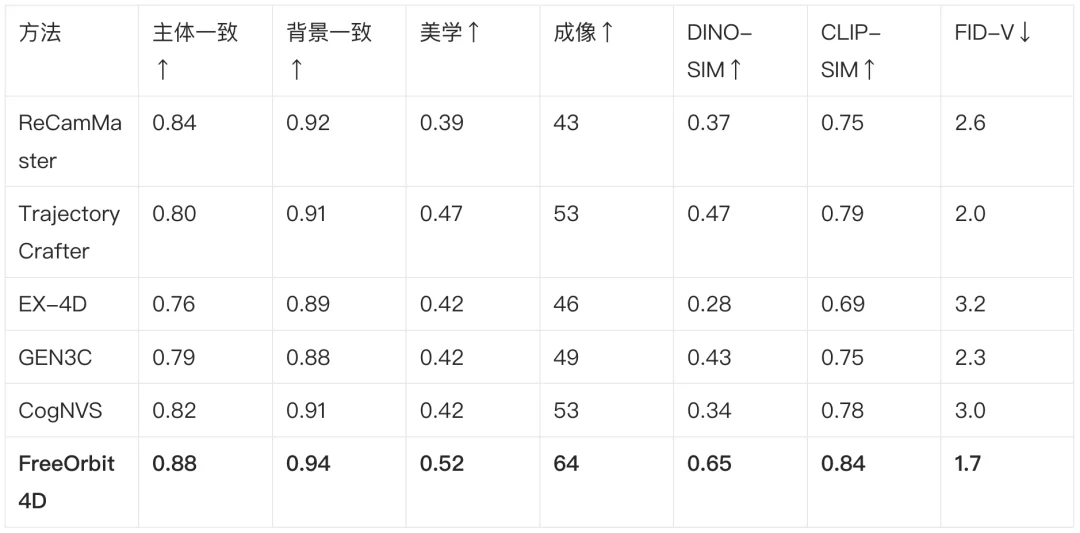
其中语义一致性差距尤为明显:DINO-SIM 达 0.65,比次优(0.47)高出近 40%—— 相机转到大角度后,画面里的「他」依然是源视频里的「他」。

用户研究:运镜准确度 4.5 vs 3.5。一个有意思的发现是,自动指标其实「看不出」相机有没有听话 —— 某些基线偏离了轨迹、丢了几何,分数却还不错。于是团队请 20 位参与者在 10 个序列上打分(1–5):FreeOrbit4D 在总体偏好(4.6)、运镜准确度(4.5)、时序稳定性(4.5)三项全面领先,运镜准确度比次优方法整整高出 1 分。消融实验进一步证实:去掉多视角生成或卡尔曼滤波,指标都会明显下降。
不止运镜:显式 4D 的「副产品」
由于中间产物是一份显式、可编辑的 4D 点云,一系列应用变得顺理成章。
外观编辑传播 —— 改一帧参考图(斑马纹、动漫风),4D 代理就能把编辑一致地传到所有新视角:

4D 几何操控 —— 直接缩放点云、或跨场景把另一段视频重建的物体合成进来(下图把另一段视频里重建的骆驼合成进当前场景):

4D 数据生成 —— 还可把海量单目视频转成带完整几何、多视角一致的 4D 数据,为破解高质量 4D 数据稀缺这一瓶颈提供新思路。
局限与展望
论文也坦诚讨论了局限:流程假设单一主导前景与大致静态背景,多物体重度互遮挡仍有挑战;作为模块化系统,上游分割或多视角合成的误差会向下传导(但也意味可随时替换更强组件);多阶段流程质量优先,单张 A40 处理 45 帧约需 50 分钟,实时化是未来方向。
从上百台相机的阵列,到一段手机视频就能任意重新运镜,FreeOrbit4D 展示了一条与「堆数据、训大模型」不同的路线:把经典 3D 视觉的几何推理,作为生成模型的结构支架 —— 重建管「对不对」,生成管「像不像」,各司其职,反而在最病态的大角度场景下取得了最稳定的结果。目前代码已开源,主页提供可交互 demo,欢迎上手体验。
文章来自于"机器之心",作者 "曹巍"。
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner


