当大模型从“回答问题”走向“自己搜索、验证、综合证据”,Deep Search Agent正在成为下一阶段智能体能力的重要方向。
这类Agent不再满足于一次检索、一次回答。它需要在开放网络中多轮搜索,交叉验证,排除错误,并在足够证据支撑下给出最终答案。
但真正训练这种能力,首先要解决一个基础问题:什么样的搜索数据,才是真的难、真的有用?
来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。
与单纯经验式构造复杂问题不同,FORT首先从理论上建模Deep Search任务中的shortcut collapse,再将这些风险转化为数据合成中的显式控制项。
基于FORT生成的搜索轨迹,研究团队训练得到FORT-Searcher。该模型使用Qwen3-30B-A3B-Thinking-2507作为基座,仅通过监督微调(SFT)训练,就在多个挑战性Deep Search基准上取得了同规模开源Agent中最优的整体表现。

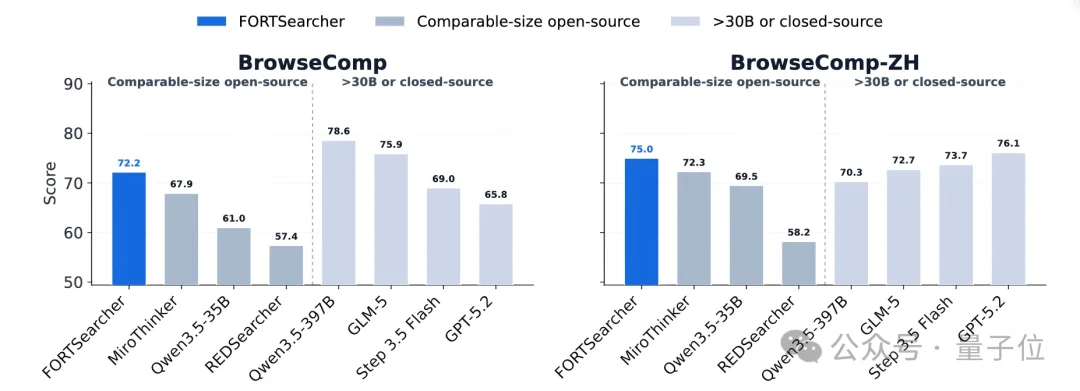
△FORT-Searcher在BrowseComp和BrowseComp-ZH上的主要结果。
为什么高难搜索题会“塌缩”?
FORT的核心理论出发点是:Deep Search任务的难度不是一个静态属性。
一个问题设计得多复杂,只说明它的apparent difficulty很高;但当这个问题真正交给一个搜索Agent,在具体检索接口和具体模型能力下执行时,难度可能会发生变化。真正重要的是realized difficulty:模型在真实搜索中是否必须经历充分的证据获取过程,才能识别答案。
论文将Deep Search问题形式化为多约束检索任务。完整约束集合可以唯一确定答案,但模型在实际求解时不一定需要验证所有约束。只要某个较小的约束子集已经足以识别答案,并且这个子集可以通过很短的搜索路径被验证,任务难度就会塌缩。
论文将这条低成本答案识别路径称为cheapest identifying route。
- 这揭示了一个关键问题:真正决定搜索难度的,不是设计者预设的完整推理链,而是所有可能识别答案的路径中,是否存在一条足够便宜的路径。
基于这一视角,论文将难度塌缩分成两类。
- 第一类是route-level collapse。它来自问题和检索环境本身。例如,一个线索就足够锁定答案,多个线索被同一个网页共同覆盖,或者题面暴露了后续搜索本应逐步发现的中间常量。
- 第二类是solver-level collapse。它来自具体模型自身。例如答案实体足够知名,模型可能在检索证据充分出现前,就凭参数知识提前提出答案。
FORT将这些现象总结为四类shortcut risks:
- Evidence Co-coverage:多个线索被同一个证据源覆盖,使多步验证退化成少量检索;
- Single-clue Selectivity:某个或极少数线索过于独特,已经足够定位答案;
- Exposed Constants:题面暴露人名、作品名、年份、数字等可直接搜索的常量,使后续query提前可执行;
- Prior-knowledge Binding:模型在证据充分出现前,凭参数知识提前提出答案。
FORT的理论贡献在于,它不是孤立地观察这些现象,而是把它们放入统一的shortcut-aware difficulty framework中,解释它们如何降低真实搜索成本,并指导后续数据合成。
FORT:把理论风险变成数据构造控制项
FORT的目标不是简单把问题做长,而是系统性减少cheap identifying route,让模型更难通过单个线索、单个网页、题面常量或参数知识提前获得答案。
整个合成流程包括四个阶段:Graph Initialization、Graph Construction、Question Formulation和Adversarial Refinement。
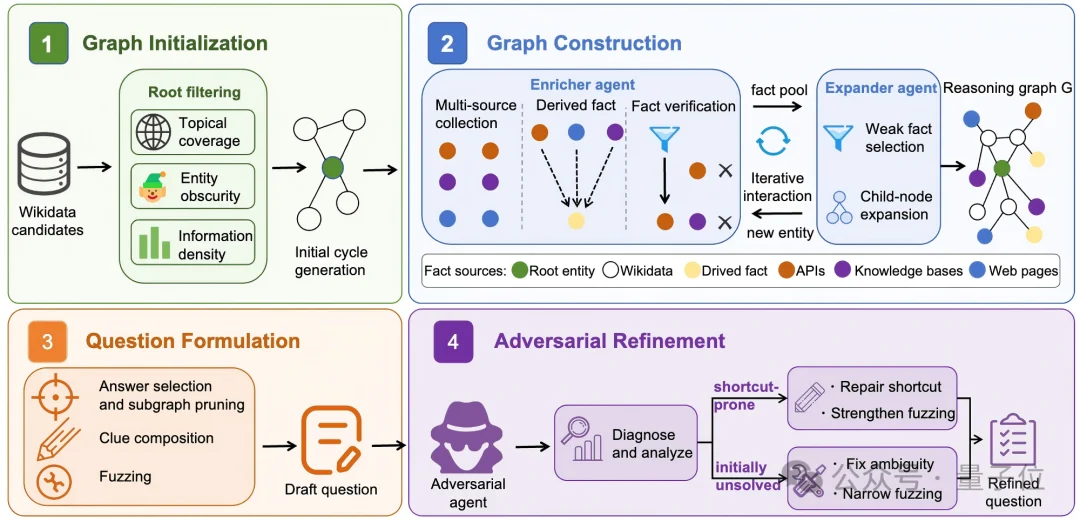
△FORT整体数据合成pipeline。
从长尾实体出发,降低先验捷径
FORT首先从Wikidata中选择root entity,并初始化seed graph。
为了降低prior-knowledge binding,FORT优先选择长尾实体,尤其是没有英文Wikipedia页面、模型不太可能直接记住的实体。同时,FORT会进行轻量级预搜索,过滤掉外部证据不足的实体,保证问题仍然可解。
除了实体选择,FORT还尽可能使用cycle-based initialization,而不是简单线性链条。线性链条在问题生成时容易暴露中间实体,导致后续query从一开始就能执行;cycle seed则可以让关系表达更间接,减少exposed constants风险。
构造异构证据图,而不是单纯把图做大
从seed graph出发,FORT会扩展evidence graph。这里的重点不是图有多大,而是facts、sources和dependencies是否能支持真正search-heavy的问题。
具体来说,FORT会从多种外部来源收集事实,降低evidence co-coverage风险;构造derived facts,避免clue直接对应网页原文;并选择那些“单独看平凡,但组合起来能够定位答案”的facts。
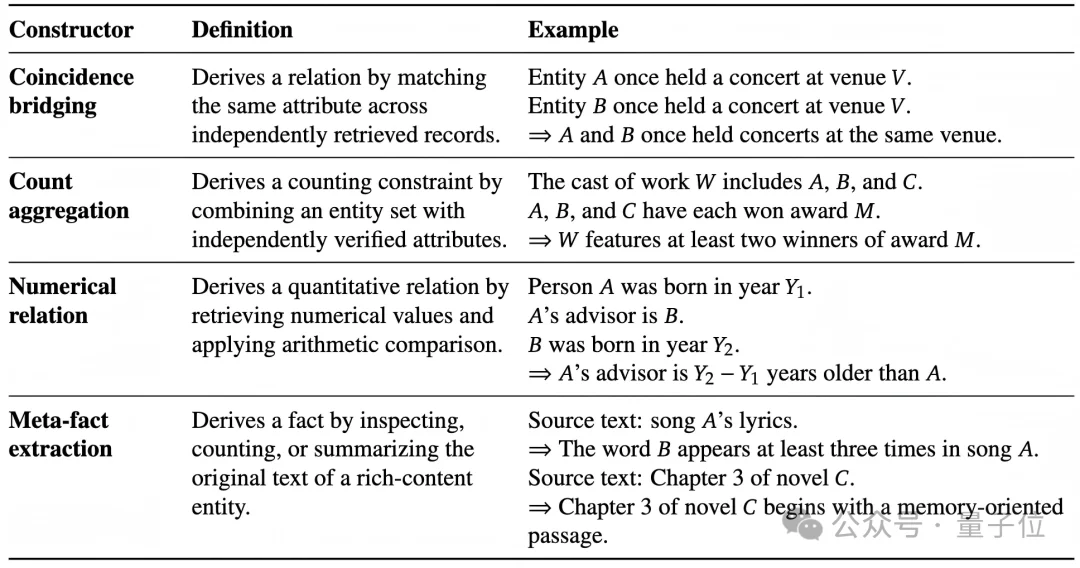
Derived facts是FORT的关键设计之一。它们不是简单摘取网页中的一句话,而是通过跨记录匹配、计数聚合、数值关系或元信息抽取等方式构造新的约束。
例如,问题可以不直接说“某人出生于某年”,而是描述“某人的导师比他年长多少岁”;也可以不直接给出作品标题,而是通过歌词、章节结构或出现次数形成间接约束。
这种设计让每个clue都有贡献,但又避免任何单个clue过强。
隐藏中间实体,模糊精确常量
在Question Formulation阶段,FORT会将answer-bearing subgraph渲染成自然语言问题。
为了减少exposed constants,FORT会隐藏中间实体名称,用关系描述替代直接命名。例如,不直接给出某个人物、作品或机构名称,而是通过其属性、关系或事件间接描述。
对于必须出现的数值、日期或名称,FORT会进行exact-value fuzzing。比如,将精确年份、数字或日期改写成范围、类别、数字特征或间接约束。这样可以避免模型直接复制题面中的精确字符串去搜索,同时保证问题仍然真实、可验证。
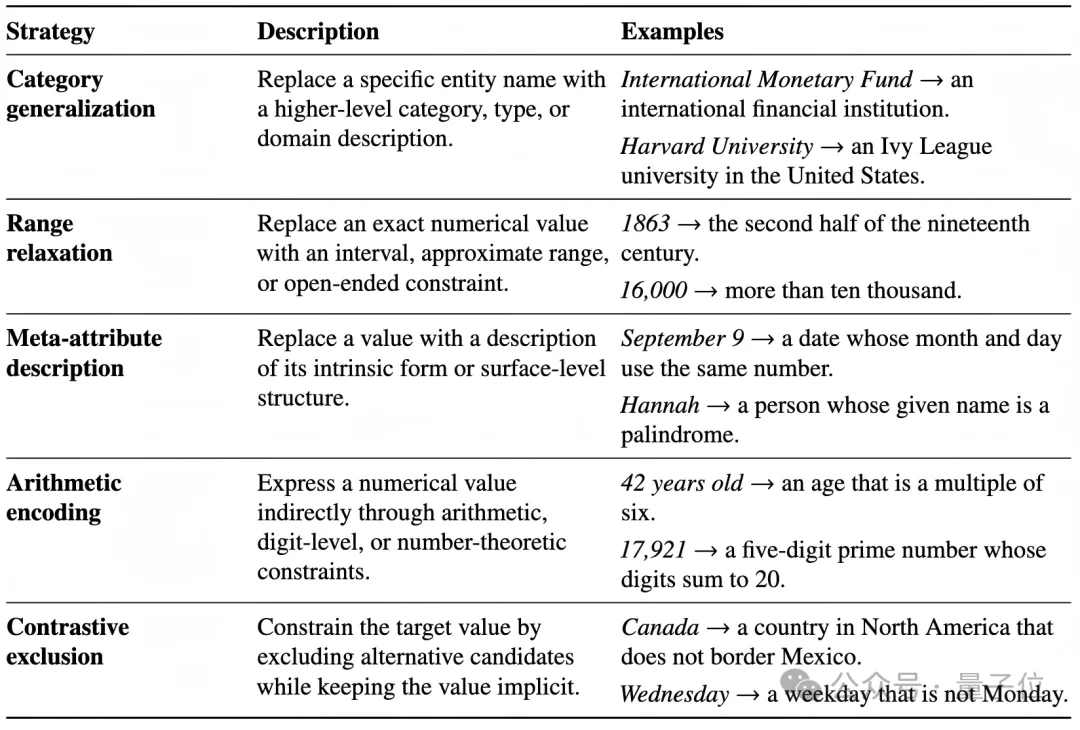
很多看似多跳的搜索题并不真正难,因为题面已经给出了下一跳的搜索关键词。FORT的问题生成阶段试图避免这种情况:不是让问题变得模糊不可解,而是让关键中间信息必须通过搜索逐步发现。
用强搜索模型攻击草稿题,修复残余捷径
构造阶段的控制并不能保证问题在真实搜索接口下一定没有shortcut。因为shortcut往往只有在具体搜索引擎、具体模型和具体轨迹中才会暴露。
因此,FORT引入Adversarial Refinement:让强search agent实际求解draft question,并观察轨迹中的solving cost、answer hit time和prior-shortcut行为。
如果模型过早命中答案,FORT会修复最早出现的shortcut-prone clue;如果问题因为过度fuzzing或歧义导致不可解,FORT会收窄clue、恢复必要约束或移除歧义事实。
这一步让FORT从construction-time control闭环到trajectory-level diagnosis。也就是说,FORT不只是理论上避免捷径,而是用真实搜索轨迹来检查和修复残余捷径。
30B级FORT-Searcher达到同规模开源SOTA
基于FORT生成的shortcut-resistant search trajectories,研究团队训练得到FORT-Searcher。
FORT-Searcher使用Qwen3-30B-A3B-Thinking-2507作为基座模型。该模型总参数规模为30B,推理时约激活3B参数,并支持256K上下文窗口。该基模未提前对搜索能力进行优化,因此能更好反映FORT数据带来的提升。
评测覆盖五个挑战性Deep Search基准:BrowseComp、BrowseComp-ZH、xbench-DeepSearch-2505、xbench-DeepSearch-2510和Seal-0。
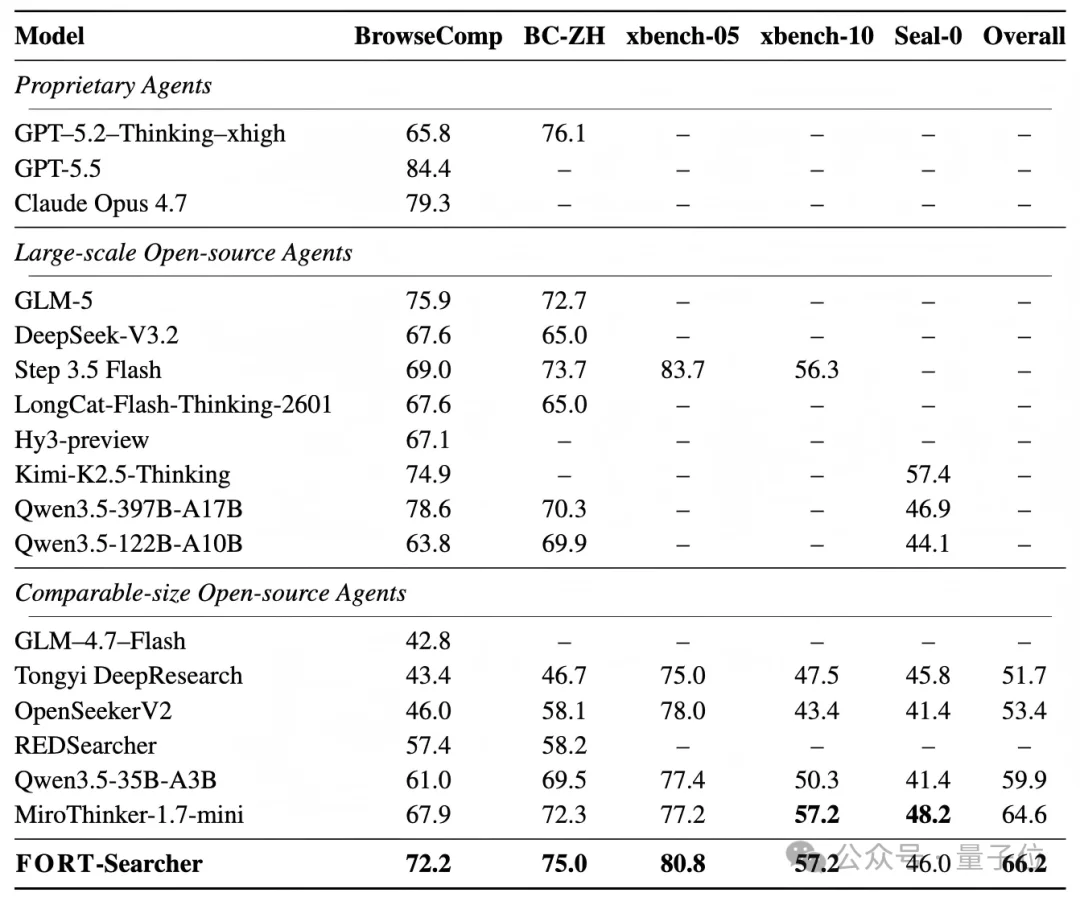
△FORT-Searcher与其他Deep Search Agent的主结果对比。
实验结果显示,FORT-Searcher在comparable-size open-source agents中取得最高Overall分数66.2,超过MiroThinker-1.7-mini的64.6和Qwen3.5-35B-A3B的59.9。
在BrowseComp上,FORT-Searcher达到72.2,高于MiroThinker-1.7-mini的67.9;在BrowseComp-ZH上达到75.0,高于MiroThinker-1.7-mini的72.3;在xbench-DeepSearch-2505上达到80.8,也超过同规模开源基线。
更重要的是,FORT-Searcher只使用SFT训练,推理时约激活3B参数,却在BrowseComp上超过多个更大规模开源Agent;在BrowseComp-ZH上,也取得了表中所有开源Agent的最高结果。
- 这说明FORT的贡献不只是合成了一批复杂问题,而是生成了真正有效的搜索监督数据。
不是简单让轨迹变长,而是提高答案发现成本
FORT的进一步分析聚焦于一个问题:训练数据的难度到底体现在哪里?
长轨迹本身并不等于高质量搜索监督。后续搜索可能有助于验证和补充证据,但Deep Search训练还需要关注答案出现之前的证据发现过程:模型是否必须跨越多个约束、多个证据来源和必要的中间依赖,才能逐步识别答案。
因此,论文引入了一组trajectory signatures:

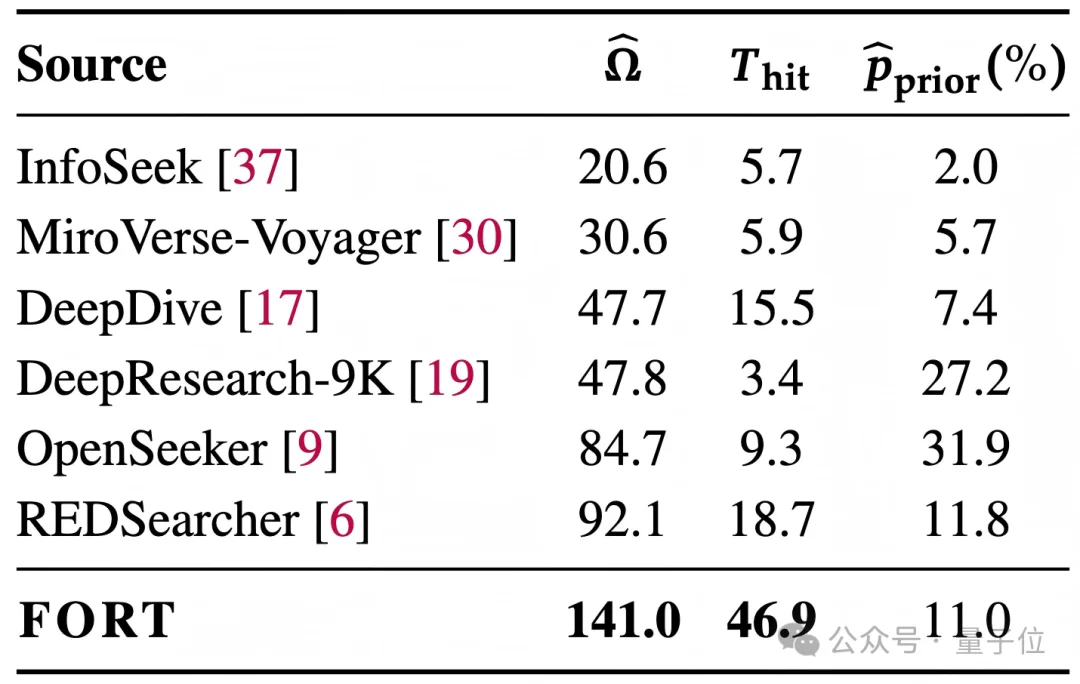
△FORT与已有开源deep-search数据的trajectory signatures对比
相比已有开源deep-search数据,FORT带来了更高的solving cost和更晚的answer hit time。具体来看,相比最强开源数据基线REDSearcher,FORT将平均solving cost从92.1提升到141.0,将answer hit time从18.7推迟到46.9,同时prior-shortcut rate保持在相近水平。
这说明FORT并不是简单诱导模型多搜几步,而是在构造阶段减少cheap identifying route,使答案发现过程本身更难被绕过。
进一步的training-data difficulty analysis也验证了这一点。
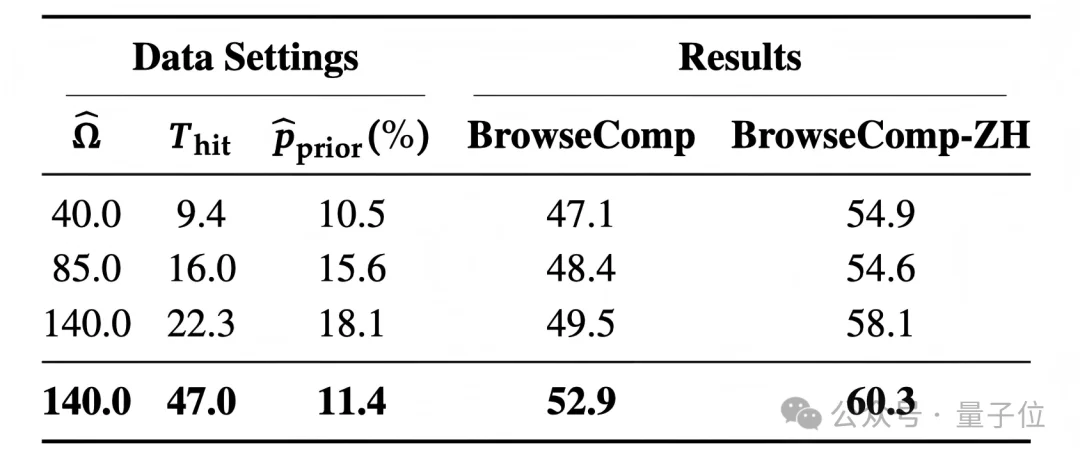
△Training-data difficulty analysis:轨迹长度之外的答案发现成本。
结果显示,单纯提高平均轨迹长度只能带来有限提升;而在相近轨迹长度下,答案发现过程更长、prior-shortcut更少的训练数据,最终带来了更好的训练效果。
这也是FORT的核心经验:高质量搜索监督的关键,不只是轨迹有多长,而是答案发现过程是否足够必要、足够难以被捷径绕过。
从“复杂问题”到“不可绕过的搜索过程”
FORT-Searcher的意义不只是提出了一个更强的30B Deep Search Agent。更重要的是,它系统回答了一个基础问题:高难Deep Search数据为什么难造?
过去,Deep Search数据构造往往关注问题有几跳、图结构有多复杂、轨迹有多长。但FORT指出,这些都只是apparent difficulty。真正关键的是realized difficulty:答案是否必须通过真实搜索中的充分证据获取才能出现。
为此,FORT从理论上建模了shortcut collapse,并将四类shortcut risks转化为数据构造中的具体控制机制,包括长尾实体选择、异构证据图构造、derived facts、name withholding、exact-value fuzzing和adversarial refinement。
最终,基于FORT数据训练得到的FORT-Searcher,在多个挑战性Deep Search benchmark上取得同规模开源Agent中最优整体表现。进一步分析也表明,FORT的提升来自更高的答案发现成本、更少的真实搜索捷径,以及更有效的搜索监督。
FORT-Searcher的核心价值不只是30B级Deep Search Agent新SOTA,而是提出了一套从理论建模到数据合成再到模型训练的闭环方法:让搜索数据不只是看起来复杂,而是真的能训练模型进行长程证据发现。
关于至知创新研究院
至知创新研究院(IQuest Research)以“做更有价值的AI”为核心理念,致力于破解尖端研究与真实场景应用之间的转化鸿沟。作为创新型研究组织,至知集探索者、实战派、连接器三重角色于一身:聚焦下一代AI基础架构,推动自主可控的全栈自研;深耕智慧医疗、生物技术、能源电力、数学智能等高壁垒研究与应用场景,打造端到端智能解决方案;依托全球资源网络,打通从理论到实践的转化链路。研究院汇聚顶尖人才,持续培养复合型AI人才。至知创新研究院将持续以智能计算重写科学规则,以系统方案重塑产业路径,开启AI更具价值的未来。
论文题目:FORT-Searcher:Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
arXiv:https://arxiv.org/abs/2606.12087
GitHub:https://github.com/RUCAIBox/FORT-Searcher
文章来自于微信公众号 “量子位”,作者 “量子位”
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner


