长期以来,原生多模态模型一直存在一个天生短板。
传统的原生多模态模型如Janus,BAGEL,一般使用两个视觉Encoder来分别处理理解和生成,看似分工明确,实则埋下了致命BUG。
理解模型的encoder(常用SigLIP 2)学到的是语义特征,生成模型的encoder(常用VAE)学到的是重建特征,两个encoder给出的feature并不在同一个空间里,模型需要额外学习它们之间的映射。
不仅白白浪费算力,模型的效果上限也被死死锁死。
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。

具体而言,HYDRA做的事情是:
训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。
HYDRA-X的Tokenizer进一步把这个思想拓展到了视频的理解和生成。
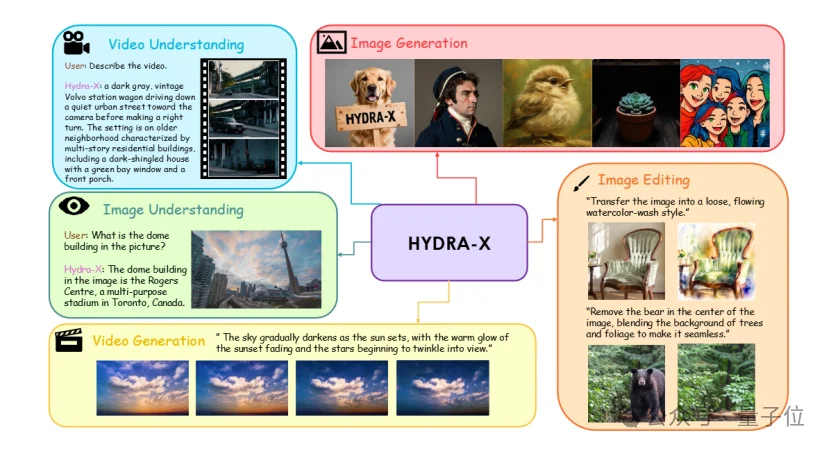
HYDRA-X原生多模态模型现已支持:图像视频理解,图像视频生成,指令引导图像编辑。

传统原生多模态模型Tokenizer设计范式:解耦Encoder是主流,统一Encoder是趋势
传统原生多模态模型Tokenizer设计范式一般可以分为下面几种。
- 下图(a)是把理解Encoder和生成Encoder做解耦,比如BAGEL。这样做的问题在于理解和生成的视觉特征不是一致的。
- 下图(b)的做法是把理解Encoder和生成Encoder进行串联,比如Show-o2。这样做的问题在于信息的过渡太快,用于理解的表征和用于生成的表征没法直接对齐。
- 下图(c)的做法是直接使用共享的表征编码器,比如UniTok。这样做的问题在于这个编码器很难学,因为生成所需要的高频信号与理解所需的语义是有矛盾的。
本文的HYDRA Tokenizer希望为UMM设计一种Unified Tokenizer,它既能够很好地完成重建任务,也具有丰富的语义来赋能生成任务。如下图(d)所示是HYDRA Tokenizer的设计思路。
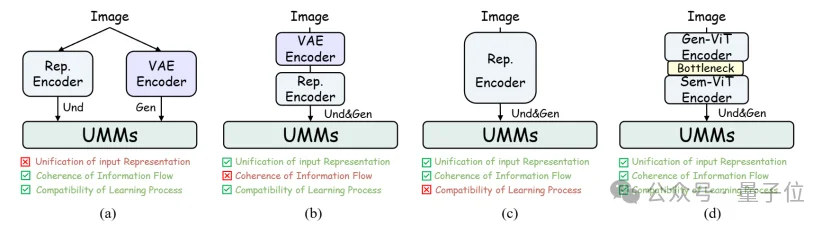
△常见原生多模态框架的Tokenizer方案
HYDRA Tokenizer基于ViT架构。它通过Gen-ViT和一个Decoder完成VAE的任务,即提取latent特征以及后续的重建。latent特征会再通过Sem-ViT得到带有语义的高维特征。在Gen-ViT和Sem-ViT之间,有一个Generation-Semantic Bottleneck(GSB)模块来投影到低维latent,再投影回高维特征。
HYDRA Tokenizer训练目标
如下图所示是HYDRA Tokenizer的训练方法。
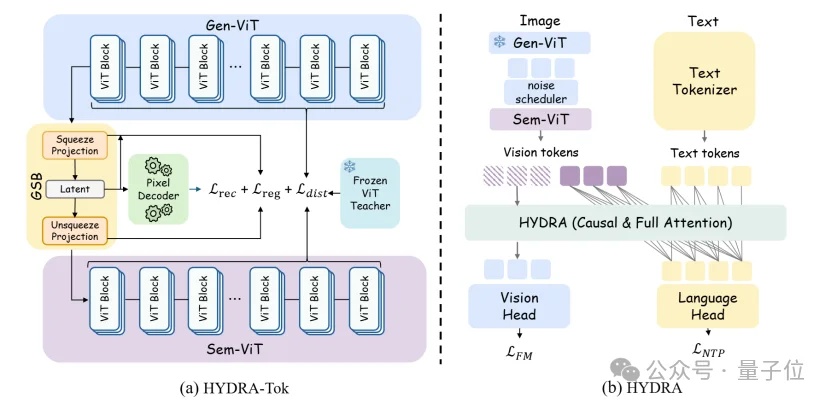
- 重建损失:Decoder包含Flow Matching去噪。因此回归损失包含Flow Matching Loss。此外,还有LPIPS Loss和GAN Loss。
- 蒸馏损失:蒸馏损失是Gen-ViT以及Sem-ViT的特征与Vision Encoder对齐,作者这里用的冻结参数的Vision Encoder是InternViT。
- 回归损失:回归损失包括latent space的KL损失,以及GSB模块里面降维之前的特征与升维之后特征的对齐。
总的训练目标为重建损失,蒸馏损失,回归损失的加权和。
用统一的Tokenizer训练原生多模态模型
HYDRA UMM遵循了大多数UMM的训练方法,使用Next-token Prediction建模文本,使用Flow Matching训练生成。
注意HYDRA UMM的加噪的视觉token使用的是GSB升维之后的视觉特征。
Gen-ViT和Sem-ViT的配置
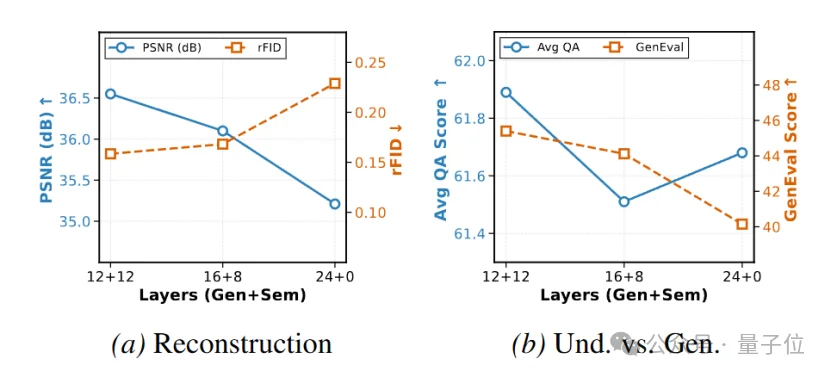
作者首先对latent的channel数进行了消融。结果如下图所示。C=64是sweet spot。
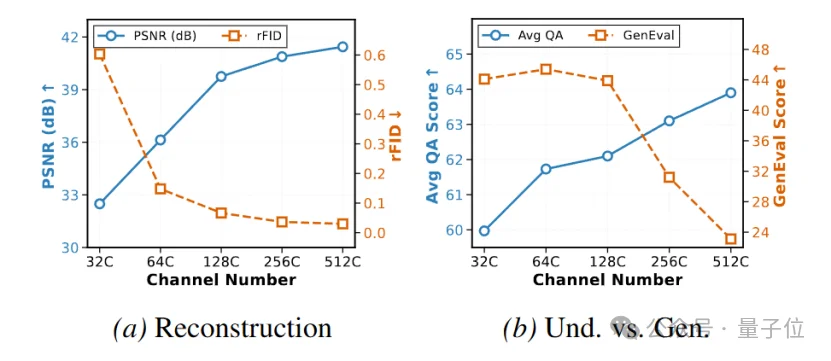
然后,作者对层数的分配也做了消融。结果显示12+12在PSNR,Avg QA,以及GenEval上都最佳,也是一个sweet spot。
HYDRA Tokenizer的重建效果
作者还评测了HYDRA Tokenizer的重建性能,结果如下图所示。
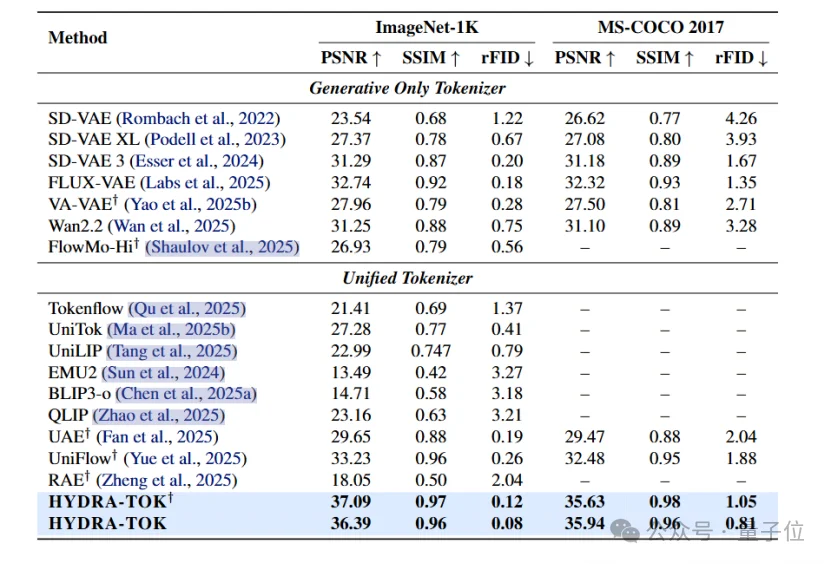
从历史上看,ViT-based Tokenizer的重建能力是被认为不如常规CNN-based Tokenizer的。但是下图的结果展示了ViT-based Tokenizer的重建也可以做得很好。
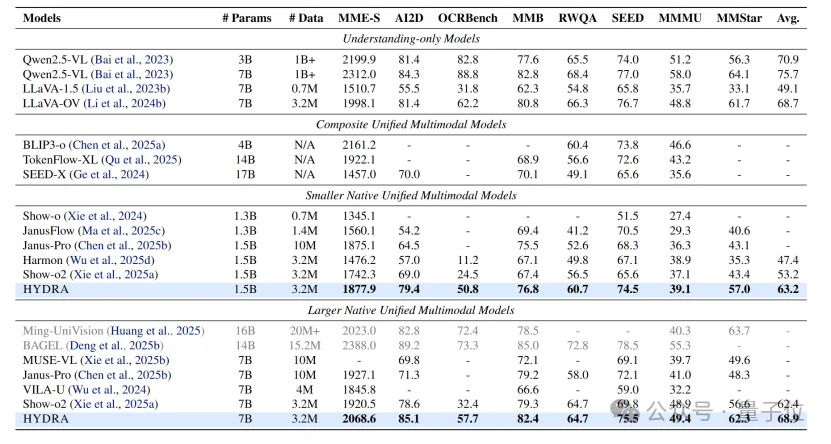
- 多模态理解评测
如下图所示是多模态理解任务的结果。在1.5B这个量级,HYDRA的平均分是63.1,大幅超过了基线Show-o2的53.2。缩放到7B以后,HYDRA继续领跑,在MMStar和SEED这种复杂推理任务上超过Show-o2。
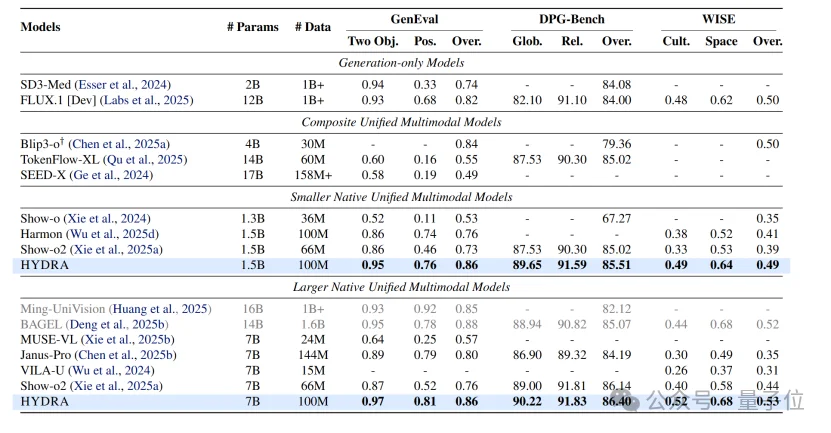
- 多模态生成评测
如下图所示是生成的结果。在1.5B规模,HYDRA的GenEval和DPG-Bench大幅超越了Show-o2。在7B规模,HYDRA超过了Ming-UniVision和FLUX.1[Dev]。
HYDRA思想适配视频任务
HYDRA-X沿用了HYDRA的技术路线,即使用单个基于ViT的Unified Tokenizer来作为理解和生成的Encoder。不同的是,HYDRA-X Tokenizer在图像理解和生成的基础上,进一步支持了视频的理解和生成。
HYDRA-X聚焦的是把这种Unified Tokenizer从Image适配到Video,需要面临的两个问题:
- 问题1:把时空重建能力注入到ViT里面。
- 问题2:把图像和视频的语义嵌入到共享的latent里面。
HYDRA-X的Tokenizer(Gen-ViT和Sem-ViT)采用SigLIP 2初始化。
问题1:给ViT注入时空重建能力
之前的ViT-based Tokenizer有两个设计共同点:
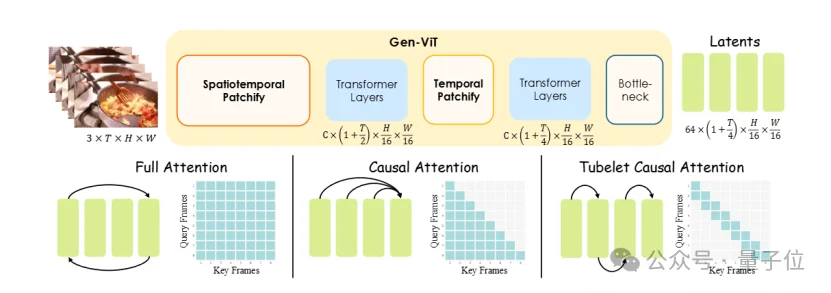
- 对所有帧使用full spatialtemporal attention。(随clip长度带来平方复杂度)
- temporal维度使用1步patchify压缩。(压缩过程比较激进,损失细粒度时序信息)
针对这些设计和问题1,HYDRA-X给出了两个在tokenizer上的改进:
其一,不需要用很多attention,2-frame turbelet attention的重建效果最好。
其二,逐步patchify胜于一步patchify,把时间维度patchify过程从单步4倍压缩改为两步2倍压缩提升重建效果。这说明时间维度受益于逐步压缩。
下图是不同的时空重建设计方案。
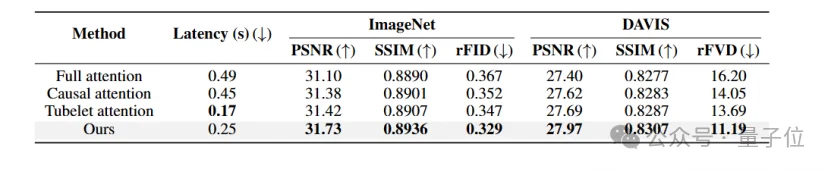
下图是不同设置下的重建结果对比。
问题2:时空语义蒸馏
HYDRA给Gen-ViT和Sem-ViT都用了语义蒸馏,对齐预训练的Image Teacher(InternViT)。
HYDRA-X用类似的办法,把Sem-ViT的输出与Image Teacher(SigLIP2)和Video Teacher(InternVideo-Next)对齐。
对于Image来讲对齐比较容易;但是对于Video而言,压缩之后只剩下1+T/4帧,没法与Teacher Video Encoder直接对齐。
HYDRA-X的方案是引入一个轻量级的Decompressor,如下图所示。Decompressor是一个很小的ViT,将temporal维度拉回到未压缩的维度。这样一来,就可以用Image Teacher和Video Teacher分别对齐了。

Decompressor只用在Tokenizer预训练阶段;后续丢弃。换句话说,LLM喂入的仍是压缩后的Sem-ViT的输出。
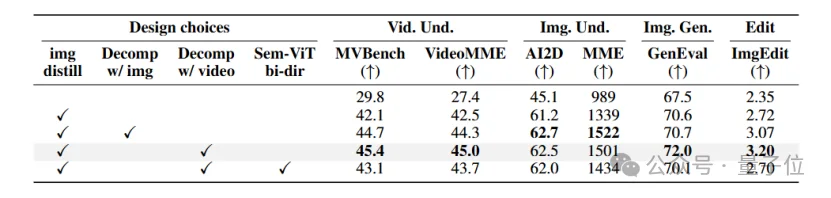
如下图所示,作者进行了一些消融实验。结论是:
- 语义蒸馏是很有必要的。
- Decompressor使得HYDRA-X Tokenizer可以与Video Teacher进行对齐,Video Understanding性能最佳。
- 给Sem-ViT换bidirectional attention会损失所有测试的性能。
通过Decompressor同时进行与Image Teacher和Video Teacher的对齐,使得latent有更显式的时空语义结构,进而同时改善理解和生成。
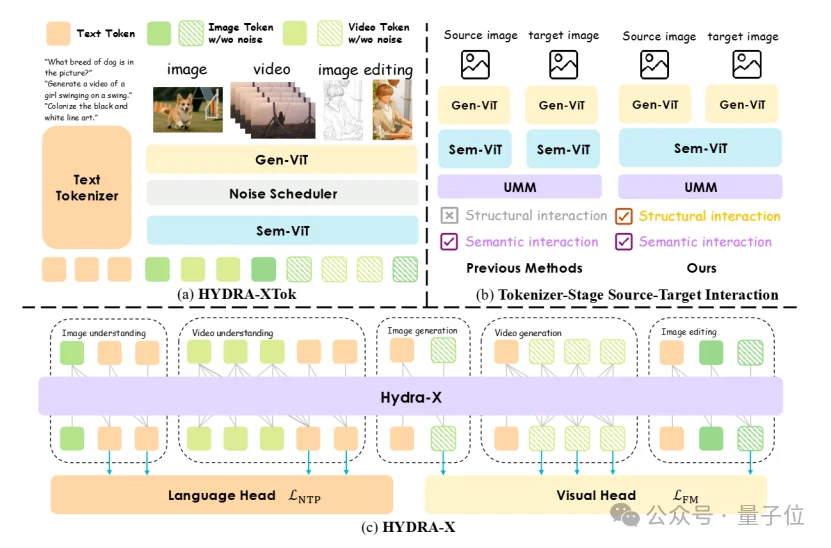
HYDRA-X使用一个共享的Tokenizer做5个任务:图像理解,图像生成,视频理解,视频生成,图像编辑。与HYDRA UMM一样,HYDRA-X UMM也使用Next-token Prediction建模文本,使用Flow Matching建模视觉信息,即图像和视频。
图像编辑:在Tokenization阶段做交互
值得一提的是,对于图像编辑任务,HYDRA-X并不是把source image和target image分别独立过一下Tokenizer。作者认为这种做法会使得二者在Tokenization过程中缺乏交互。
HYDRA-X的做法是:使得source image和target image在Tokenization阶段就进行交互。具体做法是:Gen-ViT还是独立地编码各自的image。
到了Sem-ViT之后,开始交互,使用tubulet causal mask,如下图所示。
如下图所示是上述做法的消融实验结果。这里主要想对比的是在图像编辑中,editing pair是分别进行编码,还是在Sem-ViT中,以leng-2 clip的形式,通过tubelet causal attention,整合在一起。在Tokenization过程中进行交互的做法对于ImgEdit和Recon-PSNR都有帮助。

Latent-level的交互对于图像编辑而言很重要。在Sem-ViT中,借助tubelet causal attention来对source image和target image做交互,无需添加额外的参数,且可以提升编辑性能。
HYDRA-X的bottleneck dimension是64。
HYDRA-X的Image Teacher使用SigLIP-SO400M-patch16-naflex,Video Teacher使用InternVideo-Next-L。
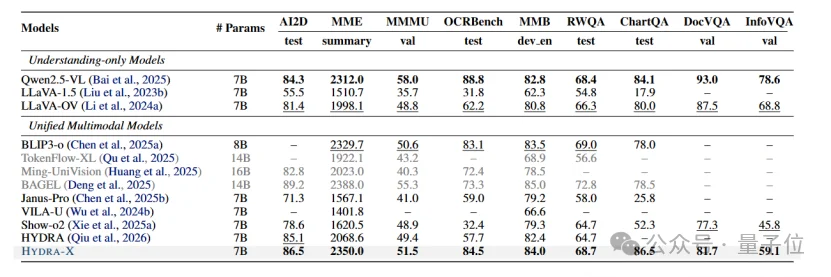
△图像理解评测
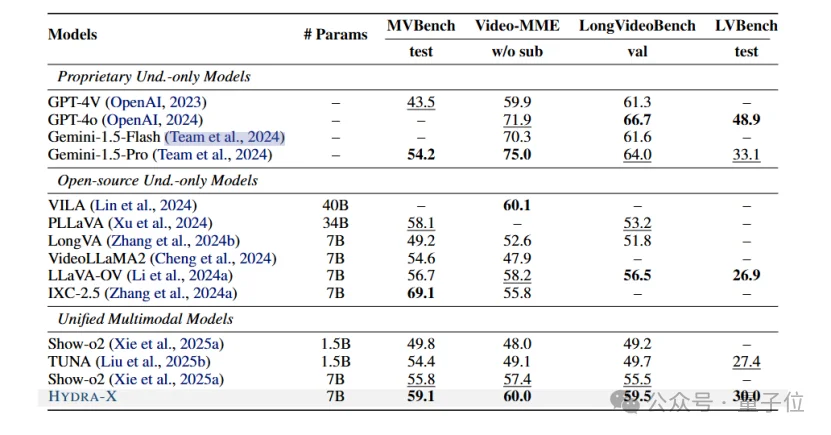
△视频理解评测
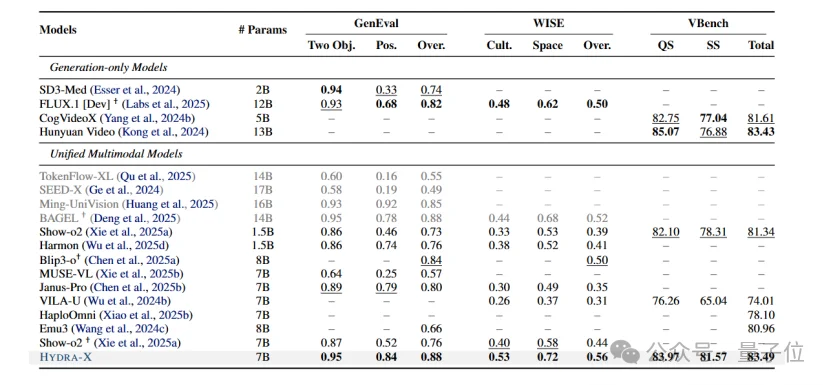
△多模态生成评测
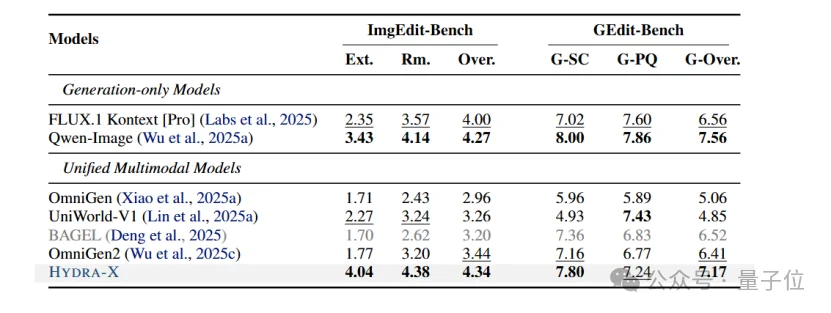
△图像编辑评测
论文链接:
HYDRA: Unifying Multi-modal Generation and Understanding via Representation-Harmonized Tokenization
https://arxiv.org/pdf/2603.15228
HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
https://arxiv.org/pdf/2606.13289
文章来自于微信公众号 “量子位”,作者 “量子位”


