
「Claude斩杀线来了」
豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个:
工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。
以至于你豆姐被戏称为糖包,甚至成了一个形容词。Gemini拉了,你们叫它北美大豆包。Grok更拉,你们居然说这是北美二豆包。
真是岂有此理!岂不闻君忧臣劳君辱臣死之理乎!豆姐卫士何在?
所以我们有理由相信,Seed模型团队有充足动力憋个大的,不求像Seedance那样放大卫星,至少要将文本模型赶上国内一线水平。
这次Seed 2.1 Pro发布,特别强调了编程和长任务执行的能力,宣传口号是终于能胜任Agent工作的模型,还号称补上了Coding的拼图。
事实果真如此吗?
为了客观体现Seed 2.1 Pro的编程水平,我用它重跑了一遍葬AI基准测试。让我用最直白、不绕弯的方式,不卖关子,一次性给你模型能力榜单⬇️
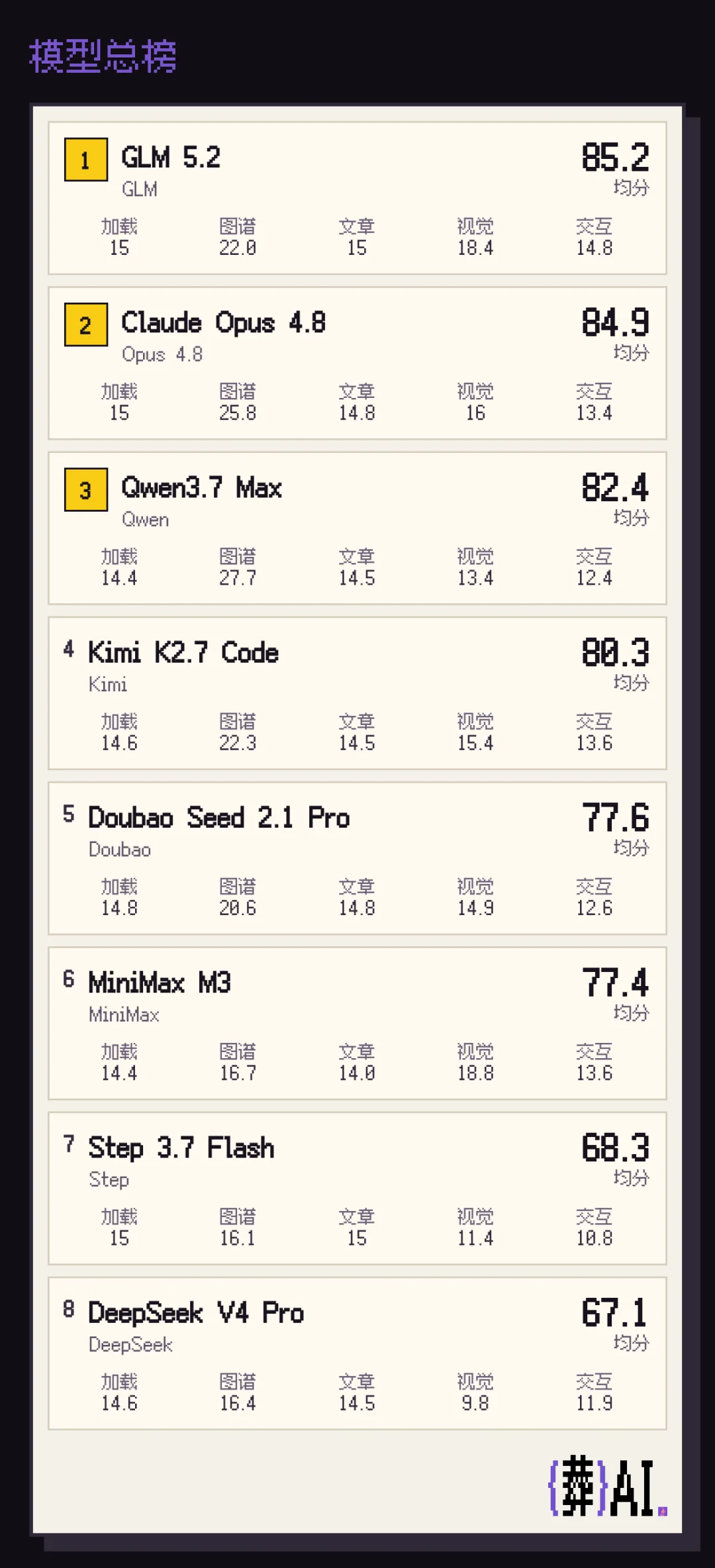
结果令人震惊。Seed 2.1 Pro的得分和MiniMax M3差不多,略低于Kimi K2.7 Code ,相比国模第一GLM 5.2更是有明显差距。
这次增加测试了Seed 2.1 Pro和Step 3.7 Flash两个新模型。
测试方法依然是,每个模型跑10轮,每轮独立的Opencode会话,输入同一个执行方案,来重构美丽的葬AI网站(funeralai.cc)。由Codex来调度和打分,用加权平均分排序。
葬AI网站上有测试模型的全部产物,8x10一共80个,大伙可以自己直观感受每个模型的差距。
Seed 2.1 Pro的问题主要出在,很难一次性生成好的结果,工程能力不太稳定。
这导致了Seed的模型调用数比较高,跑完测试任务的调用数为449次,远高于GLM 5.2(321)、Qwen 3.7 Max(218),和Step 3.7 Flash(443)一个水平,仅次于全场调用数最高的MiniMax M3(653)。
体现在生成结果上,Seed 2.1 Pro的产出物很不稳定。
Seed的高分很高,产出了3个高分,但低分更低,波动显著,拉低了总得分。比如下图就是一个高分产物,知识图谱清晰可交互。
https://funeralai.cc/test/r4/doubao-seed-2-1-pro-260628
主要扣分点是,Seed生成不明白知识图谱,这种相对复杂的前端任务,Seed在10次里失败了6次。比如下图就是一个典型的低分产物,知识图谱是空的。
https://funeralai.cc/test/r10/doubao-seed-2-1-pro-260628
另一个大问题是,Seed 2.1 Pro的生成速度太慢了。
跑完测试任务耗时128.9分钟,仅次于MiniMax M3(153.9分钟),远高于于全场最快的DeepSeek V4 Pro(46.7分钟),和比较快的Qwen 3.7 Max(53.3分钟)、Step 3.7 Flash(57.4分钟)、GLM 5.2(69.7分钟)。
生成速度慢的原因,可能是Seed的长程任务执行能力不太行。
这其实是符合豆包自己发布的榜单的。
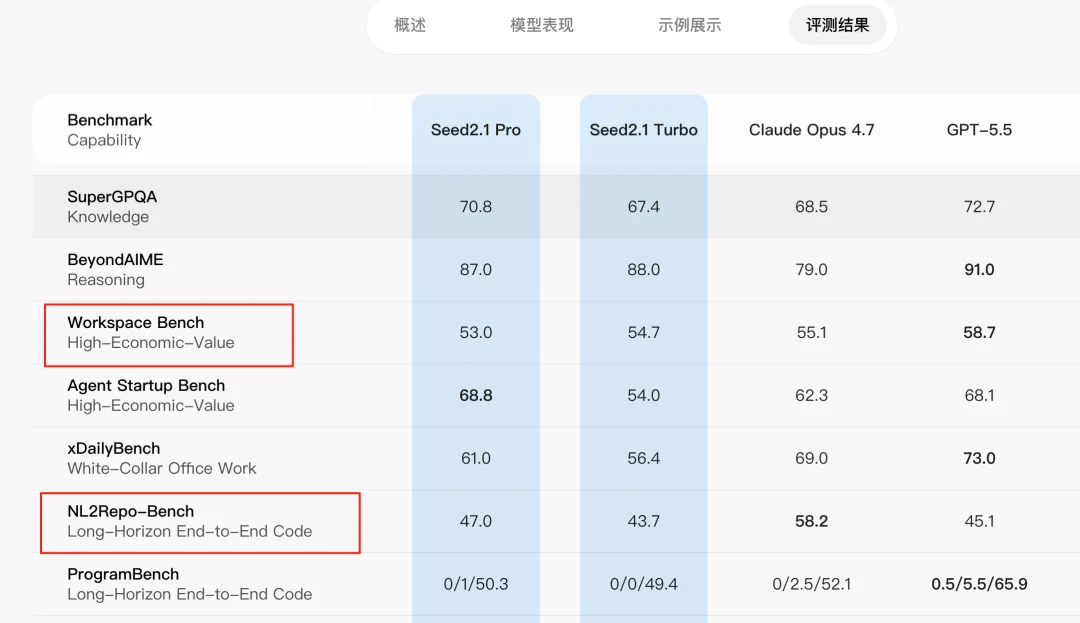
经过凯一的提醒,我发现原来字节自己跑的测试也反映了这个问题。这两个 Bench 对长程任务 plan 能力的评估比较有代表性,豆包也没藏着掖着,确实不够SOTA。
坦诚清晰,符合字节价值观👍
凯一对Seed 2.1 Pro评分的解释是,「Seed 通用能力其实好一点,不是 Coding 专精,如果测深度调研,数据爬取,在浏览器里点点点,可能 Seed 就比 GLM 好,GLM 是 Coding 专精。」
不过,现在模型厂全都在卷编程,Seed这次更新也主打任务执行和编程能力。还是让我们回到这次编程测试上。
一共10轮测试任务,Seed 2.1 Pro干出来了8个无效进程,有效产物命中率等于55.6%。依旧远高于GLM 5.2的3个无效,Kimi的2个无效和Step一个无效,其他模型没有失败进程。
调用次数高、任务失败较多,导致了Seed 2.1 Pro的成本也较高,跑完测试任务一共花了41.3元,依旧仅次于Opus 4.8(202.5 元)和Kimi K2.7 Code(164.6 元),远高于DS、Qwen、Minimax都在20元左右的成本,和GLM 5.2成本一致。
所以,在没有任何折扣,直接从火山引擎官网调用的情况下,Seed 2.1 Pro做编程任务的性价比显著不高。
为了直观感受这些模型的完成任务速度、花费和调用数,我也做了一个葬AI基准测试性价比榜。
让大伙除了认识到最强模型之外,也能给予高性价比模型一点关心❤️
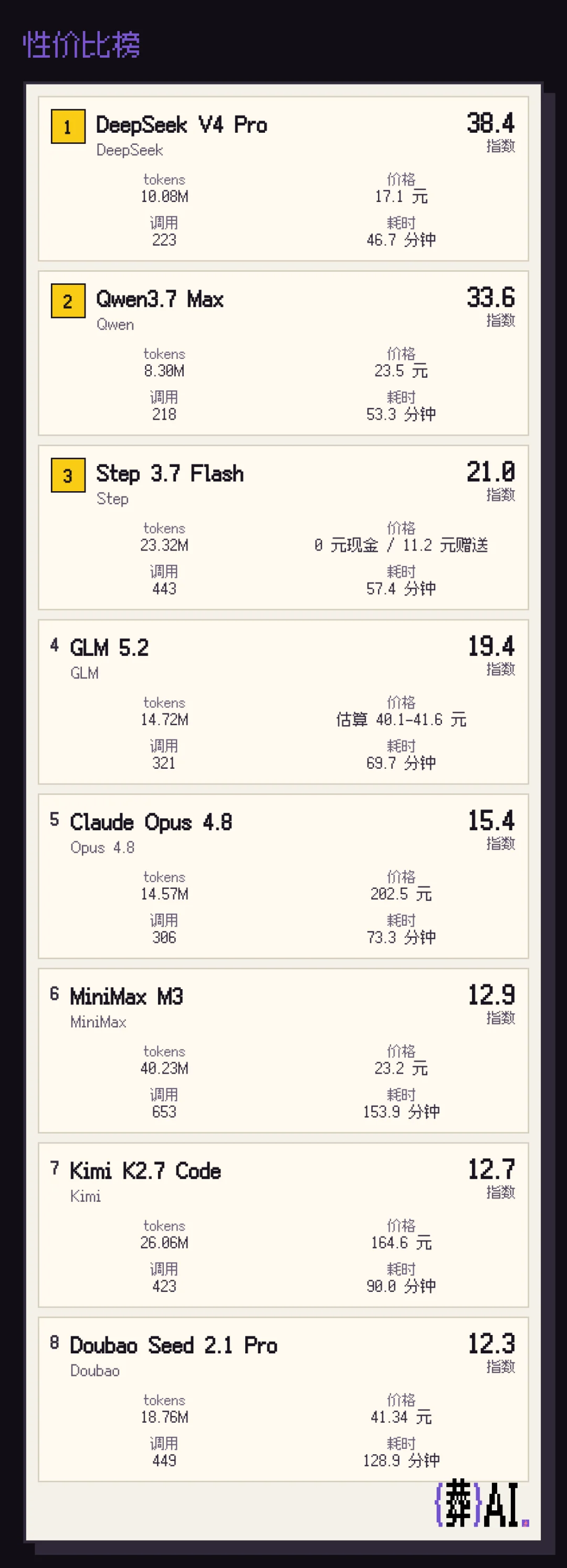
其中可以看出,阶跃的Step 3.7 Flash模型特别让我惊喜。它的能力得分比DeepSeek V4 Pro高,成本花费居然比DS还便宜,跑完测试任务只花了11.2元,连注册账号送的15块钱都没用完。
所以在加权了调用数、耗时这些维度后,Step 3.7 Flash是所有模型中的性价比第三名。
性价比榜还非常直观地展示出了一条危险线,就是不仅存在DeepSeek斩杀线,也有Claude斩杀线。
性价比低于梁圣很正常,但性价比低于Claude就非常危险。而MiniMax M3、Kimi K2.7 Code 、Seed 2.1 Pro这三个模型的性价比指数都低于Opus 4.8了。
要努力啊,Kimi、MiniMax和Seed的家人们,一定要努力逃逸平庸的重力💪
我是相信Seed的,因为从未听说过Seed蒸馏,国产之光靠你了。

最后声明一下,葬AI基准测试依然没有接受任何人的赞助。
这是相对客观的编程能力的评测。两个榜单和所有测试产物都可以在葬AI网站阅读详细版:
funeralai.cc/test
关于Seed模型,明天还有一篇骡子马写的主观评测,看看Seed 2.1 Pro多模态、通用能力啥的到底行不行。力争主客观结合,帮助家人把每个模型整明白🫰
(本文封面由ChatGPT生成,纯人工写作)
文章来自于"葬AI",作者 "葬愛咸鱼"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md


