美团 LongCat-2.0:不是又一个万亿参数模型,而是一次国产算力上的 Agent 工程实验

最近,美团 LongCat-2.0 发布。
如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。
但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:
国产算力能不能支撑前沿级大模型训练?
万亿参数模型能不能以可用成本跑起来?
一个模型能不能从“会回答问题”,走向“能持续执行任务”?
LongCat-2.0 的价值,基本就落在这三件事上。
一、先别急着看“1.6T”,关键是它不是每次都跑满
LongCat-2.0 是一个 MoE 模型,也就是混合专家模型。
这类模型的逻辑可以用一句人话解释:模型内部不是一个巨大的单体网络,而是由很多“专家”组成。每次处理一个 token 时,不会把所有参数都叫醒,而是根据当前内容选择一部分专家参与计算。
所以,1.6T 是总参数规模,不代表每次推理都要激活 1.6T。
LongCat-2.0 平均每个 token 激活约 48B 参数,并且是动态激活。也就是说,不同 token 需要的计算量不一样,模型会按难度分配计算资源。
写一个普通变量名,和推导一个复杂递归算法,显然不是同一类工作。如果模型对所有 token 都用同样的算力,就会浪费大量计算。LongCat-2.0 引入的“零计算专家”机制,本质上就是让简单 token 少消耗,复杂 token 多调度。
这也是 MoE 模型过去一年越来越重要的原因:不是单纯把参数堆大,而是让大模型在推理阶段更像一个按需调度的系统。
二、100 万 token 上下文,真正服务的是 Agent,而不是炫技
LongCat-2.0 原生支持 100 万 token 上下文。

这个数字很容易被写成噱头,但它真正有用的地方,不是“可以一次塞一本书”,而是对 Agent 工作流非常关键。
一个代码 Agent 要修复真实项目里的 Bug,通常不是只看一个函数就够了。它需要读 README、配置文件、测试用例、依赖声明、错误日志,还要理解多个文件之间的调用关系。
上下文太短时,模型会频繁丢信息,只能靠切片、检索、重新拼上下文来补救。这样做不是不能用,但会带来两个问题:一是信息可能漏掉,二是模型容易在多轮任务里前后不一致。
100 万 token 上下文的意义,是让模型在很多任务里可以一次看到更完整的工程现场。
但这里也要说清楚:它不是 RAG 的终结者,也不是说所有代码库都能直接一把塞进去。真正的大型工程仍然会超过 100 万 token,依赖目录、构建产物、历史日志也不可能全部无脑塞给模型。
更准确的说法是:LongCat-2.0 把 Agent 可直接观察的工作区扩大了很多,让模型更少依赖碎片化检索,更容易做跨文件理解和长程规划。

三、LSA 稀疏注意力:让 1M 上下文不至于算爆
长上下文不是把窗口数字写大就完事。
传统注意力机制在长文本下的计算压力非常大。上下文越长,计算和显存负担越容易失控。如果没有底层结构优化,100 万 token 只会变成一个好看的宣传数字。
LongCat-2.0 使用了 LongCat Sparse Attention,也就是 LSA 稀疏注意力机制。
可以这样理解:模型不再对所有位置都做同等强度的关注,而是尝试在长文本中筛出更关键的信息路径,让长上下文计算更可控。
这类设计的核心不是“看得更长”这么简单,而是“看得长的同时还能跑得动”。
对 Agent 来说,这一点很重要。因为 Agent 不只是一次性回答问题,它会反复读文件、调用工具、看报错、修改代码、再测试。上下文越长,单轮成本越高。如果长上下文计算效率不解决,Agent 工作流就很难真正跑起来。
四、MOPD:不是三个模型拼起来,而是把三类能力压进一个模型
LongCat-2.0 另一个重点是 MOPD。
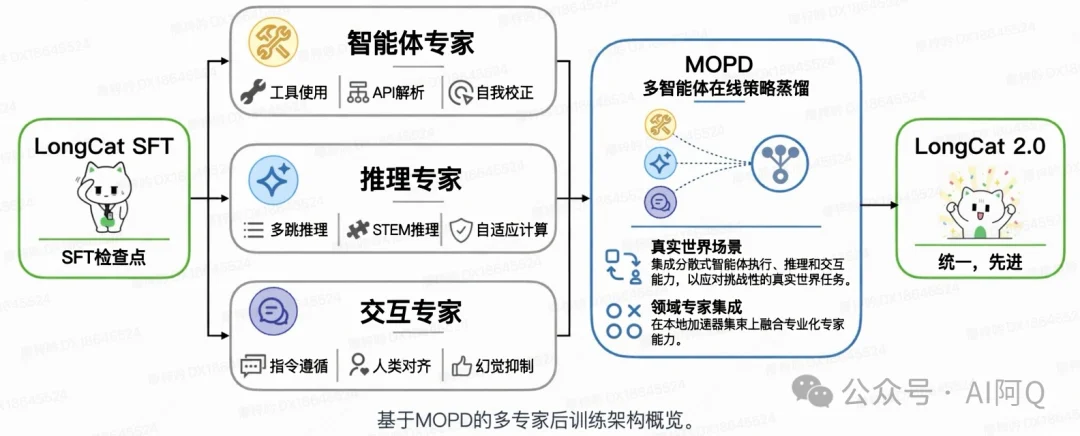
从官方示意图看,它不是简单地把几个模型合并,也不是推理时让三个 Agent 同时开会,而是在后训练阶段围绕三类能力分别强化,再融合到一个统一模型里。
第一类是智能体专家,主要面向工具使用、API 解析、自我纠错。
这部分对应真实 Agent 场景。比如模型执行命令失败后,不能只是说“抱歉出错了”,而要能读懂报错信息,判断是路径问题、依赖问题,还是代码逻辑问题,然后继续尝试。
第二类是推理专家,主要面向多跳推理、STEM 推理和自适应计算。
这对应的是复杂代码、算法、数学和工程分析。真实项目里的问题往往不是单点问题,而是多个模块互相牵连。模型需要能把线索串起来,而不是看到一个局部就下结论。
第三类是交互专家,主要面向指令遵循、人类对齐和幻觉抑制。
这部分看起来没那么“硬核”,但非常关键。因为 Agent 一旦进入真实工作流,乱改文件、忽略约束、编造执行结果,都会直接造成灾难。能不能稳定按要求输出,能不能承认不知道,能不能少胡编,是工程可用性的底线。
MOPD 的价值就在这里:它不是只追求某一种能力,而是试图把工具执行、复杂推理、稳定交互放进同一个模型能力框架里。
五、跑分能看,但不要只看跑分
从官方披露的结果看,LongCat-2.0 在代码和 Agent 评测上确实比较亮眼。
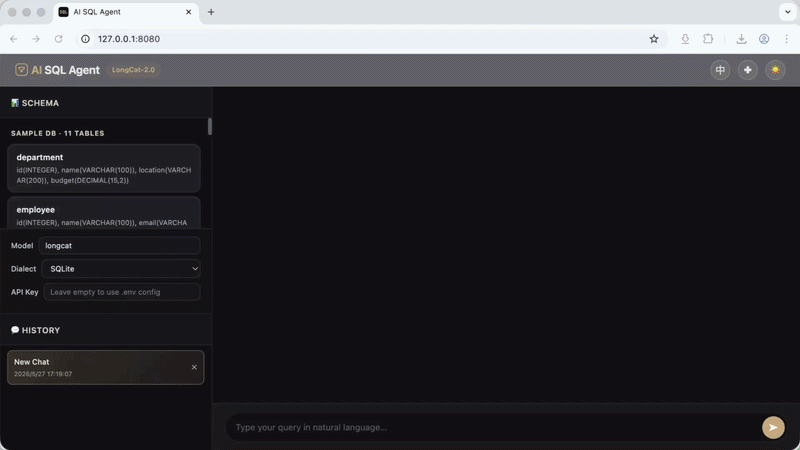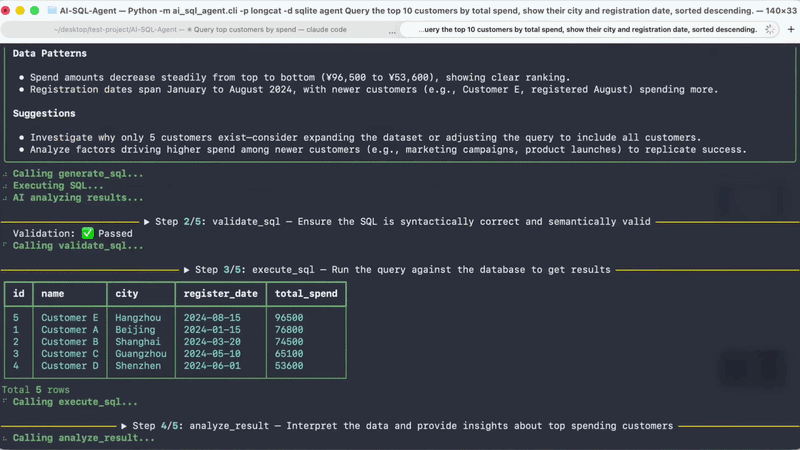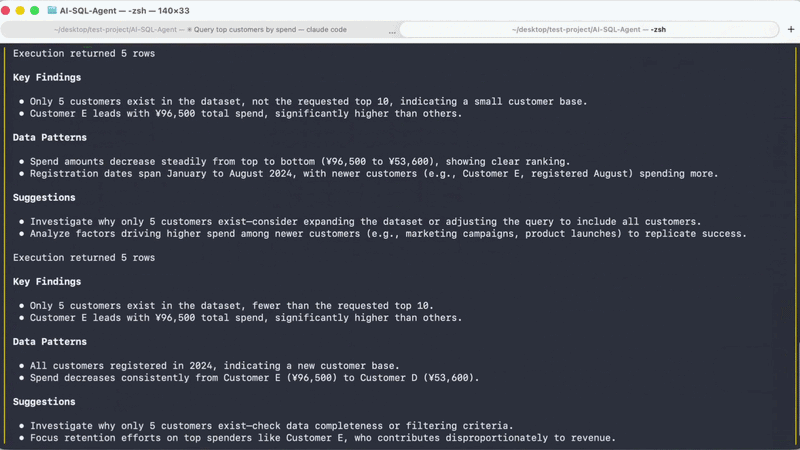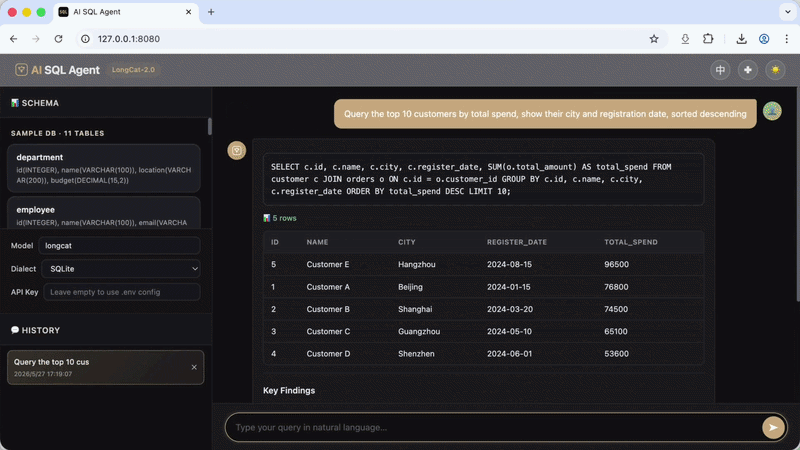
SWE-bench Pro 得分 59.5。这个基准更接近真实软件工程任务,不是让模型写一道算法题,而是让它在真实仓库里定位问题、修改代码、通过测试。
Terminal-Bench 2.1 得分 70.8。这个评测更看重模型在终端环境下执行任务的能力,包括命令调用、错误处理和多步骤操作。
此外,它在SWE-bench Multilingual、FORTE、RWSearch、BrowseComp 等任务上也给出了比较强的结果。
但这里不能写成“LongCat-2.0 全面超过所有闭源模型”。更稳妥的说法是:在官方披露的若干 Agent 和代码评测中,LongCat-2.0 已经进入一线模型对比区间,并且在部分指标上表现突出。
这已经足够重要。
因为对开发者来说,真正关心的不是模型在单题问答里多会吹,而是它能不能在一个真实项目里持续工作半小时、一小时,能不能不迷路,能不能读懂报错,能不能少犯低级错误。
LongCat-2.0 这次把主战场放在 Agentic Coding 上,方向是对的。
六、OpenRouter 上的热度,说明开发者愿意试,但不等于已经定胜负
LongCat-2.0 预览版此前以 Owl Alpha 的形式在 OpenRouter 等平台出现过。
官方称,它在 OpenRouter 的调用量进入全球前三,并且在 Hermes、Claude Code、OpenClaw 等不同 Agent 工具场景中拿到较高调用排名。
这说明一件事:开发者确实愿意试它。
但调用量不是质量投票。一个模型突然上线、价格有吸引力、长上下文能力突出,都会带来大量试用流量。真正的口碑,还要看后续几类反馈:
能不能稳定完成复杂仓库修改;
长上下文下是否真的少丢信息;
工具调用失败后能不能自我恢复;
输出速度和价格是否适合长期使用;
开源权重发布后,社区能不能跑出可复现结果。
所以,对 LongCat-2.0 最合理的态度不是立刻封神,也不是看见国产模型就先质疑,而是把它当成一个值得实测的 Agent 基座模型。
七、价格策略里,最值得注意的是缓存免费
LongCat-2.0 发布期提供了两个 token 包。
一个是 5000 万 token 新手包,价格 1.9 美元,每个账号限购一次,有效期 30 天。
另一个是 10 亿 token 深度使用包,价格 59.9 美元,发布图里显示原价为 299 美元,同样是 30 天有效。
但比价格本身更重要的是一句话:Cache hits free。
缓存命中免费,对长上下文 Agent 工作流非常关键。
比如你让模型反复分析同一个代码库,很多上下文内容其实是重复的。如果每一轮都按完整输入重新收费,长上下文会非常贵。但如果稳定命中缓存,前面那大段代码库上下文的重复成本就会下降很多。
这对 AI 编程工具很重要。
因为真实开发不是“一问一答”,而是多轮修改、多轮测试、多轮回看。缓存策略能否做好,直接决定长上下文模型能不能长期用,而不是只适合做演示。
八、开源值得期待,但现在不要写成“已经可以本地部署”
LongCat-2.0 已经有 GitHub 和 Hugging Face 页面,仓库采用 MIT License。
不过,当前官方页面仍然写着模型权重即将发布。
所以文章里不能写“开发者已经可以下载权重本地部署”,更不能写“现在就能在自己服务器上跑”。准确说法应该是:LongCat-2.0 已开放相关仓库和模型页面,权重处于即将发布状态,后续是否能被社区顺利部署和复现,还要看官方放出的权重、推理配置、显存要求和部署文档。
这点非常重要。
很多模型“宣布开源”和“社区可用”之间,中间还有很长一段路。尤其是 1.6T 这种规模的 MoE 模型,即使权重开放,也不代表普通开发者可以轻松本地运行。真正能用起来,还要依赖推理框架、量化方案、专家并行、KV Cache 管理、长上下文优化和硬件资源。
开源不是终点,而是社区验证的开始。
九、LongCat-2.0 真正的信号:模型、系统、算力必须一起做
这次 LongCat-2.0 最值得讨论的,其实不是“美团也做大模型了”。

更关键的是,它说明大模型竞争已经进入新阶段。
以前大家主要比模型参数、训练数据、榜单成绩。
现在越来越清楚:只会训练模型不够。前沿模型要真正可用,必须同时解决算力、架构、推理系统、工具调用、长上下文、成本控制这些问题。
LongCat-2.0 把几个方向放在了一起:
用 MoE 降低万亿参数推理成本;
用零计算专家做 token 级动态计算;
用 LSA 支撑百万 token 长上下文;
用 MOPD 强化 Agent、推理和交互能力;
用缓存策略降低长上下文多轮调用成本;
用国产算力完成大规模训练和部署验证。
这不是单点突破,而是模型工程系统化的结果。
也正因为如此,LongCat-2.0 不应该只被看成一个“国产大模型新闻”,它更像是一次前沿模型工程能力的展示:当 GPU 供应、推理成本、Agent 工作流都变成现实约束时,模型公司不能只拼规模,还要拼系统设计。
结语:LongCat-2.0 值得实测,但别急着神化
LongCat-2.0 是一个值得认真看的模型。
它的技术路线很清楚:用 MoE 和动态激活解决万亿参数成本,用稀疏注意力解决长上下文压力,用专家化后训练解决 Agent 能力融合,再用缓存和平台策略降低开发者使用门槛。
但它也还需要真实社区验证。
官方跑分是一部分,开发者在真实仓库、真实终端、真实业务数据里的反馈,才是下一阶段更重要的答案。
如果你关注 AI 编程、长上下文 Agent、国产算力训练,LongCat-2.0 值得放进观察名单。
它不一定马上改写格局。
但它释放了一个很明确的信号:
大模型的竞争,已经不是“谁参数更大”这么简单了。
下一轮竞争,拼的是谁能把模型、算力、推理系统和真实工作流一起打通。
文章来自于微信公众号 “AI阿Q”,作者 “AI阿Q”
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI


