当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:一个 7B 的小模型,只需要在正常计算之外「多循环这一次」(总共 2 次),就能在号称最难的真实代码修复基准 SWE-bench Verified 上从 43.0 分飙到 64.4 分;而继续往上加循环,不仅不涨,反而一路跳水。
论文标题起得很干脆——《Only Loop Once》,只循环一次。背后是来自北京航空航天大学、IQuest Research、澜舟科技和中国人民大学的联合团队。

- 论文标题:LoopCoder-v2:Only Loop Once for Efficient Test-Time Computation Scaling
- 论文地址:https://arxiv.org/pdf/2606.18023
- 研究团队:北京航空航天大学 · IQuest Research · 澜舟科技 · 中国人民大学
- 模型主页(HuggingFace):
huggingface.co/Multilingual-Multimodal-NLP/LoopCoder-V2
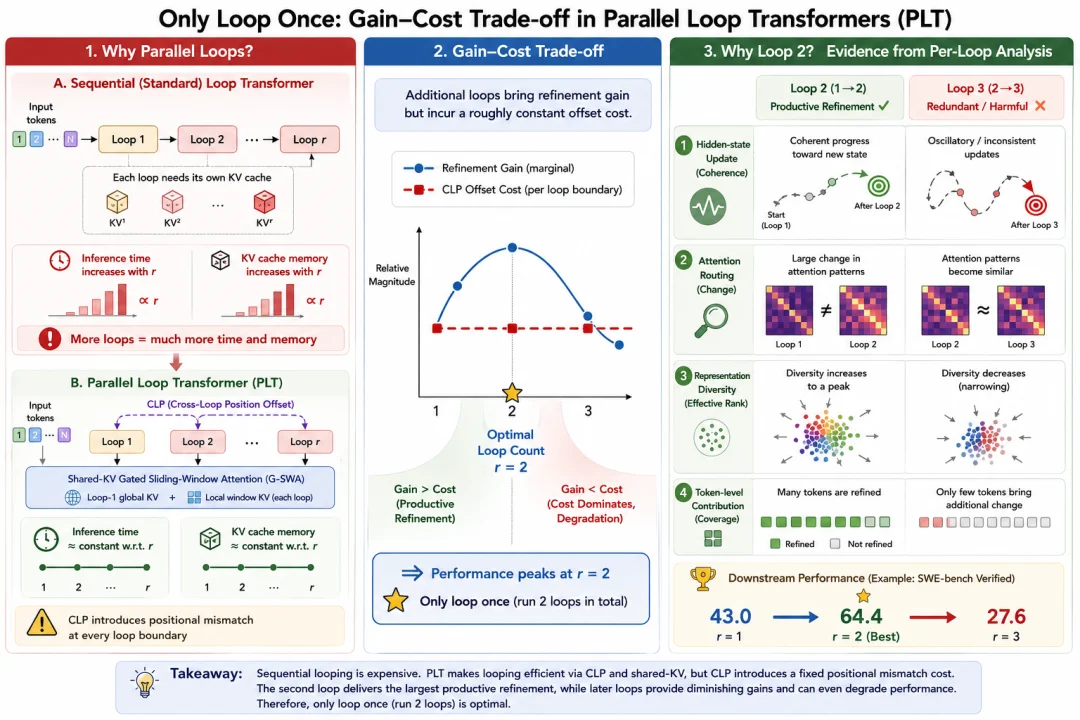
▲ 核心结论一图流:多循环带来「精修收益」,也带来几乎恒定的「位置错配成本」;收益在第 2 次循环达到峰值后迅速衰减,于是「只循环一次(共 2 次)」成为最优解。
一、「循环」,当下最热的卷法
自从 o1、Claude 这一代推理模型把「想得越久越强」写进行业共识,「测试时计算」(test-time compute)就成了过去一年最热的方向:与其把模型练得更大,不如让它在推理时多花点算力,把答案反复打磨。要理解这项研究,先得知道大家具体在卷什么。
过去想让模型更强,常规操作是把网络堆得更深、参数更多。而「循环式」大模型(Looped / Recurrent-depth LLM)换了个思路:不堆新层,而是让同一套参数,在「脑子里」把内部表征反复打磨好几遍。打个比方,这就像同一个人把一道题在心里默默重算几遍,而不是请来更多人、或者把草稿纸写满——它是一种省参数的「测试时计算」(test-time compute)。
听起来很美,但有个硬伤:顺序循环太贵。每多循环一次,就要多走一遍计算,延迟和 KV-cache 显存都跟着循环次数线性上涨。想多循环,算力扛不住。
并行循环 Transformer(Parallel Loop Transformer,PLT)就是为了解决这个问题。它用两招把成本摁了下去:一是 CLP(跨循环位置偏移),打断循环之间的串行依赖,让多次循环可以并行计算;二是 G-SWA(共享 KV 的门控滑窗注意力),让显存几乎不随循环次数增长。成本被压平之后,「循环几次」第一次变成了一个可以自由拧的旋钮。
二、旋钮拧大 ≠ 更强:
第 2 遍封顶,第 3 遍跳水
问题来了:这个旋钮,到底拧到几合适?
团队干脆从零训了一整个家族:7B 稠密模型,18T token、文本与代码 1:1、覆盖 100 多种编程语言,前后烧掉约 100 万 GPU 小时。唯一的变量,就是循环次数。结果非常反直觉:
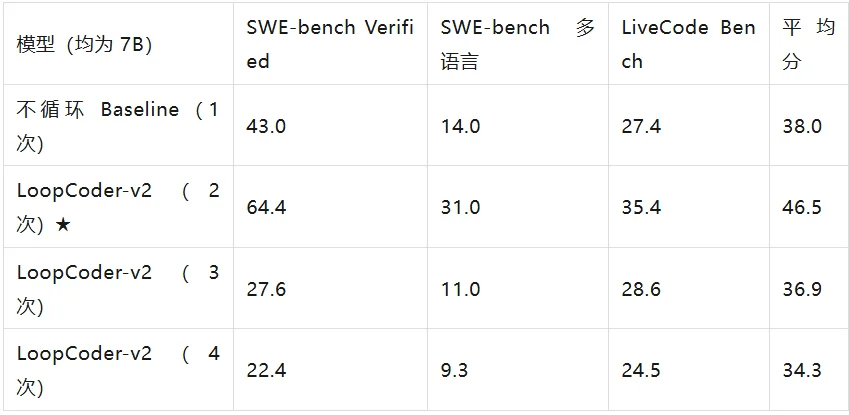
多循环一次(共 2 次)几乎全面碾压「不循环」的 baseline——SWE-bench Verified 从 43.0 → 64.4,多语言版从 14.0 → 31.0,LiveCodeBench 从 27.4 → 35.4,十项基准平均分从 38.0 → 46.5。但循环到 3 次、4 次,性能直接跳水:SWE-bench 掉到 27.6、22.4,平均分甚至不如不循环。
更能说明问题的是横向对比:这个 7B、只多循环一次的模型,在 SWE-bench Verified 上的 64.4 分,超过了 2350 亿参数的 Qwen3-235B(45.2 分),逼近 Kimi-K2(69.2)、Qwen3-Coder-480B(67.0)这些大它几十倍的开源旗舰。在偏「动手干活」的 agentic 任务上提升尤其明显:终端操作基准 Terminal-Bench 两个版本分别从 26.3 → 34.2、11.2 → 21.0(后者接近翻倍),工具调用 BFCL 从 32.2 → 40.1,提升都相当可观。换句话说,这次性能跃升不是靠更大的模型堆出来的,而是靠「多想了一遍」。
三、为什么「多循环一次」就够了?一笔收益账
真正有意思的,是团队没有止步于「2 次最好」这个调参结论,而是把模型内部拆开,算了一笔「收益——成本」账。
先看收益侧。研究者用三把「探针」——隐状态的演化、注意力的路由、输出分布的变化——同时观察每一次循环到底干了什么,只有三者一致时才下结论。结论是:第 2 次循环几乎包办了所有「有用的精修」——隐状态朝同一方向稳步收敛、注意力重新分配、输出分布明显改善,表征多样性(effective rank)也在这一步达到峰值。再往后,更新越来越小、甚至开始来回震荡(方向反转),注意力路由基本「冻结」,后面的循环近乎空转。
再看成本侧。CLP 为了让循环能并行,做了一个取巧:从第 2 次循环起,每个 token 拿到的是「邻居」上一轮的状态,而不是它自己的。这就引入了一个固定的「位置错配税」——团队把它量化成一个能直接从模型内部状态算出来的指标 Ω,并发现它在每一次循环几乎恒定不变。
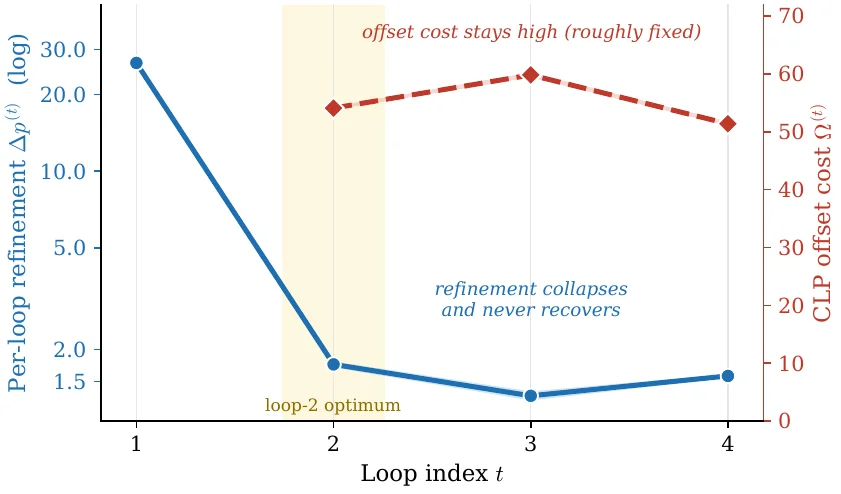
▲ 蓝线是每次循环的「精修收益」,第 2 次之后急剧塌缩;红线是 CLP 的「位置错配成本」,几乎恒定不降。一涨一平之间,第 2 次循环成为最优平衡点。
两条曲线一对照,故事就清楚了:精修收益(蓝线)在第 2 次循环后崩塌、再也没能恢复;而错配成本(红线)一直高位横盘。收益递减、成本恒定,于是超过 2 次,错配的代价就盖过了精修的收益,性能自然掉头向下。这也意味着,「循环到几次最好」不必靠昂贵的暴力扫 benchmark 一个个试,而是可以用这些内部诊断指标提前看出来。
四、对行业意味着什么
这项工作的价值,不只是又训了个能打的代码模型。
它首先给「测试时计算 = 越多越好」的流行直觉踩了一脚刹车:至少在 PLT 这类并行循环架构里,存在一个明确而且偏低的「甜点」,盲目加循环是负收益。其次,它提供了一套不靠暴力实验、而靠可解释性指标来选择循环次数的诊断方法。最后,对端侧和小模型尤其友好——7B 只要多循环一次,就能在硬核的真实软件工程任务上实现越级,这笔效率账相当划算。
团队也指出了几个值得继续挖的方向:让位置偏移变得自适应、根据任务动态分配循环次数,以及搞清楚这种「内部循环」和模型显式写出来的思维链(CoT)之间到底是怎么配合的。
说到底,在这个比拼「谁算得更多」的时代,这篇论文给出的提醒朴素却扎实:有时候,多想一遍就够了,想太多反而坏事。
文章来自于"机器之心",作者 "机器之心"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

