对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
但如果换做小众的、样例不足的年轻语言呢?
大模型到底是真的掌握了通用编程能力,还是更擅长那些在训练数据里出现过无数次的语言?
一篇新论文把这个问题拉到了台前。
论文题为《No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages》,已在arXiv发布,并标注被IEEE Transactions on Software Engineering接收。研究对象不是Python、Java这类高资源语言,而是两门较新的语言:MoonBit和Gleam。
论文作者来自瑞士USI Software Institute/SEART研究组和西班牙塞维利亚大学SCORE Lab/I3US Institute。SEART长期研究软件分析、开发者推荐系统和AI4SE,这让这项工作更接近一次来自软件工程研究界的外部评估。
论文把它们称为no-resource programming languages,可以理解为“无资源编程语言”。
这里的“无资源”,不是说语言本身能力不足,而是指它们太新,公开代码、教程、问答和项目样例还不够多,大模型在预训练阶段很可能没有充分见过它们。
注:本篇论文统计数据时节点为24年,MoonBit截止26年6月语料相对丰富
换句话说,这篇论文问了一个现实问题:
如果一门语言还没有被互联网语料充分覆盖,大模型还能写好它吗?
答案是:一开始很难。
但更重要的是,论文也展示了另一件事:新语言并不是只能等待大模型自然学会。只要有足够清晰的语言设计、文档、代码和工具链,它可以被系统性地教给大模型。
编程语言被放进了新语言考场
论文构建了三个代码生成benchmark:HumanEval、MBPP和McEval-Hard。
测试方式很直接:给模型自然语言描述和函数签名,让模型补全函数实现,再用测试用例判断是否正确。
评价指标主要是pass@1。
也就是模型只有一次生成机会。一次写出的代码能通过测试,就算成功;否则失败。
论文对比了三类语言:
- 高资源语言:Python、Java。
- 低资源语言:R、Lua、Haskell、Julia、Racket。
- 无资源语言:MoonBit、Gleam。
参与评测的模型包括GPT-4o、o3-mini、Qwen 2.5 Coder、Qwen 3等。论文说明,HumanEval和MBPP被翻译到MoonBit和Gleam,McEval-Hard则基于McEval中的hard tasks构建,最终形成跨语言比较用的函数级代码生成任务。
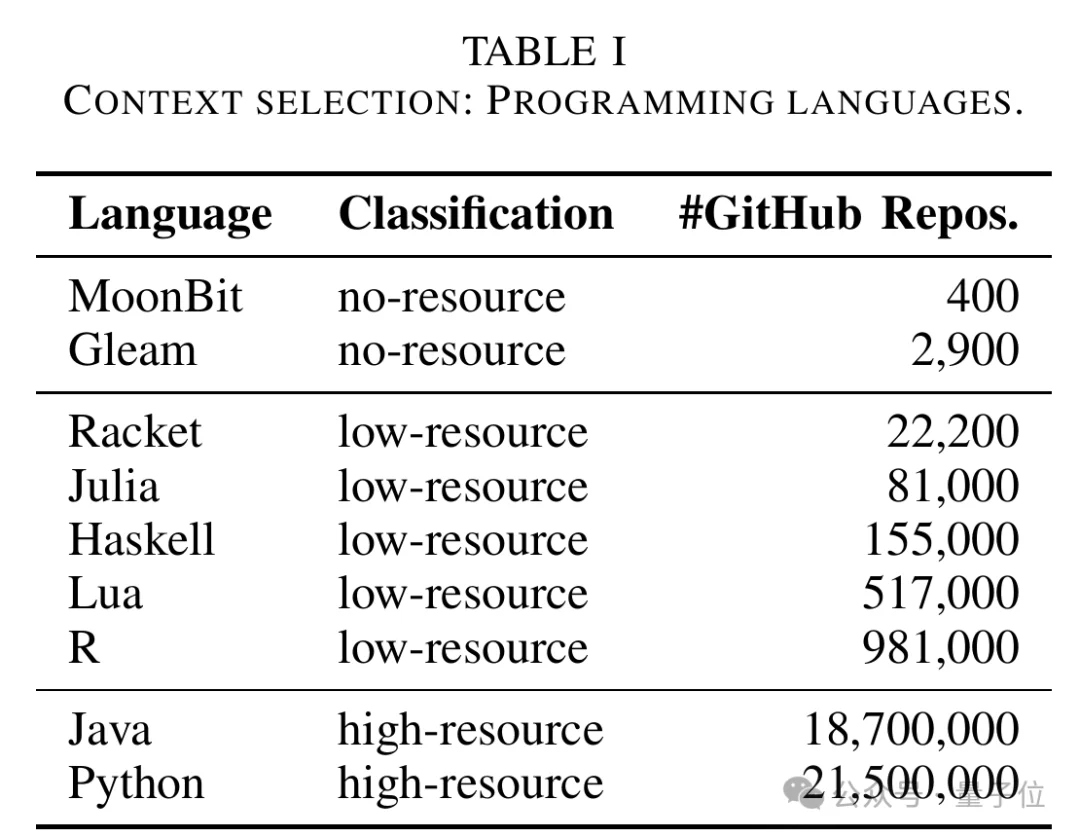
△论文中对不同语言GitHub仓库规模和资源类型的划分
零样本几乎失灵
结果并不意外,但很有代表性。
在Python、Java这类高资源语言上,大模型表现依然很强;在低资源语言上,表现有所下降但仍可用;但到了MoonBit和Gleam这样的新语言,零样本代码生成能力明显下滑。
尤其是在更难的McEval-Hard上,高资源语言的pass@1大约在59%到89%之间,低资源语言大约在27%到84%之间,而无资源语言只有0%到1%。论文还指出,无资源语言在多个模型和benchmark上的表现通常处于0%到20%之间,平均约9%。
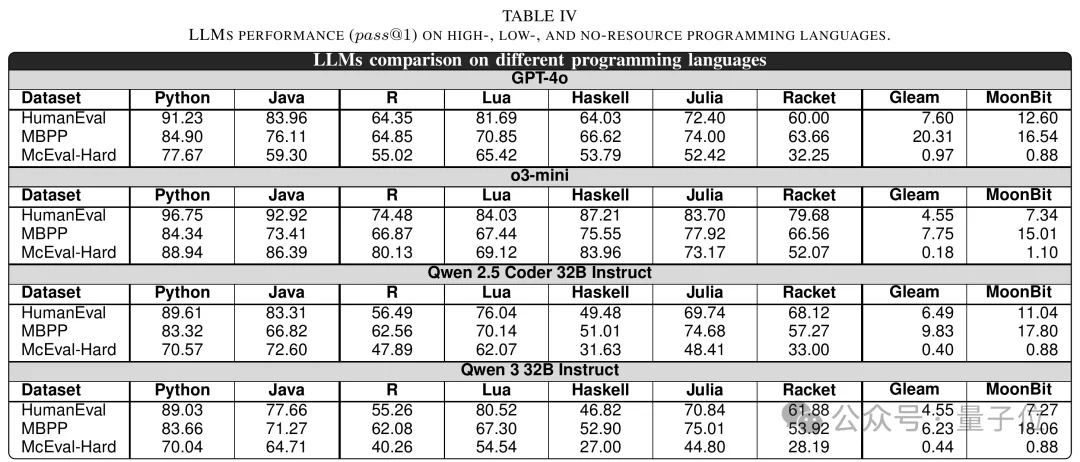
△零样本设置下,不同模型在不同语言上的pass@1对比
更关键的是,失败原因不只是“算法没想明白”。
论文分析发现,在Gleam和MoonBit上,大量失败来自语法错误。也就是说,模型经常连合法代码都生成不出来。
这并不说明MoonBit不行。
更准确地说,是模型还没有真正学过MoonBit。
大模型写Python很稳,很大程度上是因为它见过太多Python。MoonBit作为一门年轻语言,公开语料规模远小于成熟语言,因此天然更适合用来观察一个问题:
AI时代的新编程语言,如何被模型学习和理解?
临时给示例有用,但不够
论文先测试了两种常见方法:few-shot和RAG。
few-shot是在prompt中放入几个MoonBit代码示例,让模型模仿。
RAG是从MoonBit文档中检索相关内容,放进prompt中,让模型参考。
这两种方法都有提升。论文观察到,few-shot通常比RAG略好:在MoonBit的12组比较中,few-shot有8组优于RAG。作者推测,面对陌生语言时,模型从代码示例中抓语法,往往比从文档片段中理解规则更直接。
但这类方法的上限也很明显。
临时把几段代码或文档塞进prompt,只能补一些语法知识,很难让模型真正掌握语言本身。
继续预训练:让模型真正学会
真正有效的是继续预训练。
简单说,就是不再让模型临时查资料,而是直接用MoonBit代码和官方文档继续训练模型。
论文中,MoonBit的继续预训练数据包括约1310万code tokens和60万documentation tokens,总计约1370万tokens;相比之下,可用于fine-tuning的MoonBit数据只有约50万tokens。
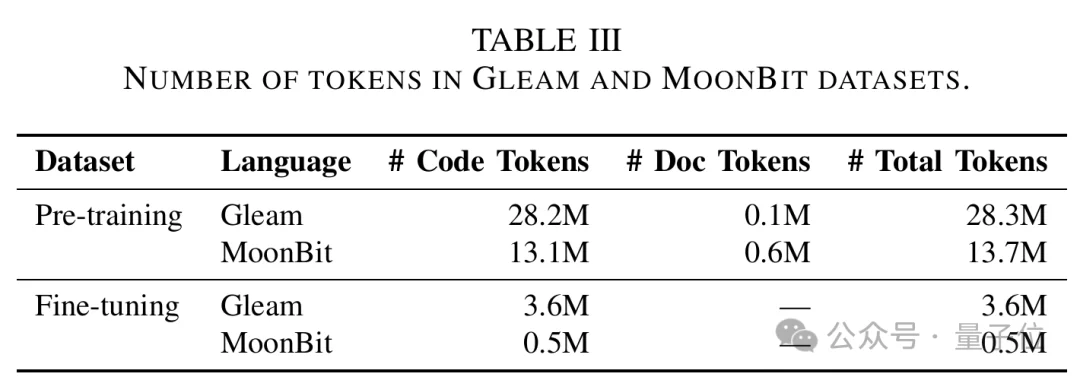
△论文中用于MoonBit/Gleam的预训练与微调数据规模
结果明显提升。
以Qwen 2.5 Coder 32B Base为例,继续预训练之后,模型在MoonBit上的pass@1达到:
- HumanEval:41.62%
- MBPP:44.76%
- McEval-Hard:25.86%
也就是说,从几乎不会写,到能在相当一部分任务上写出可通过测试的代码,MoonBit可以被模型系统性学会。
指令迁移:既懂编程语言,也听懂开发者
不过,继续预训练还没有解决全部问题。
它能让模型学会语言知识,但不一定让模型更擅长遵循用户指令。而真实的AI编程助手,不只是续写代码,还要能理解开发者需求,比如解释类型错误、重构代码、补测试、根据反馈修改实现。
所以论文进一步使用了instruction transferring。
它的思路是:先用MoonBit代码和文档让base model学会MoonBit;再把instruct model的“指令跟随能力”迁移到已经学过MoonBit的模型上。
这样得到的模型,既懂MoonBit,又更像一个能对话、能听懂需求的编程助手。
这一方法给出了论文中最强的MoonBit结果:在Qwen 2.5 Coder 32B上,instruction transferring后,MoonBit的pass@1达到:
- HumanEval:50.71%
- MBPP:53.04%
- McEval-Hard:32.60%
尤其是最难的McEval-Hard,MoonBit从零样本接近0,提升到了32.60%。
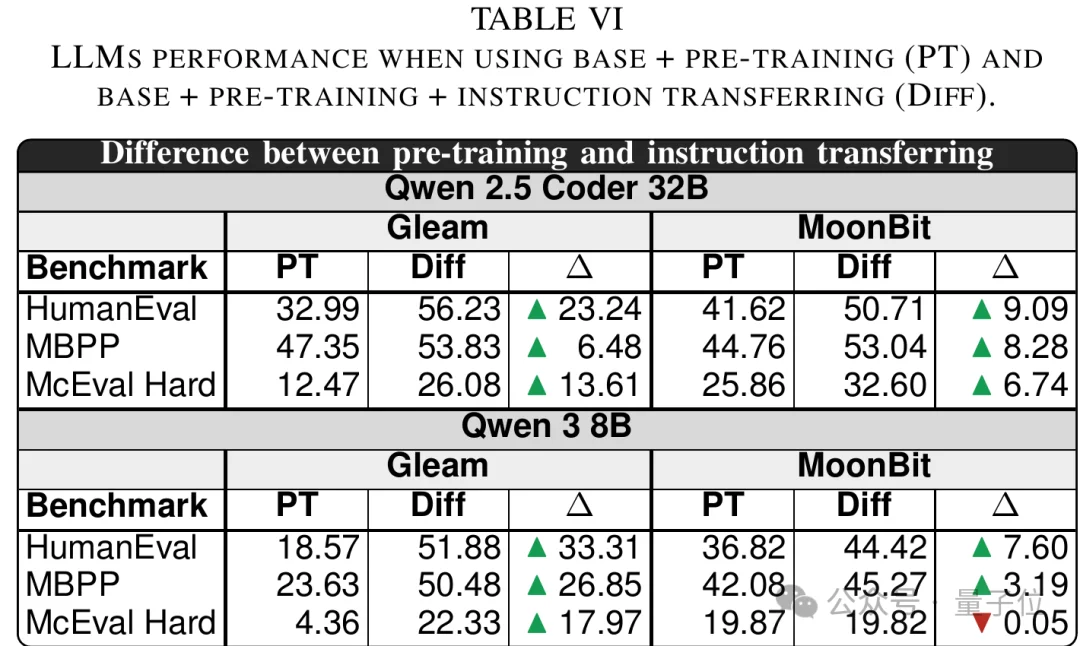
△进一步预训练与instruction transferring的效果对比
这组数字背后有一个关键信号:新语言的AI支持,不一定只能等待更大的通用模型自然覆盖。通过高质量代码、官方文档、benchmark和合适的训练方法,可以主动构建。
观察价值:让模型更容易学会新语言
这也是MoonBit值得观察的地方。
MoonBit官方将其定位为面向云和边缘计算的AI-native编程语言工具链,支持wasm、wasm-gc、js和native后端,并支持在一个模块中构建混合后端项目。官方文档还将更小的WASM输出、更快运行时性能、先进编译性能,以及简单实用、面向数据的语言设计列为主要优势。
对AI编程来说,这一点很重要。
因为AI写代码不是一次性生成文本,而是一个循环。语言设计越清晰,工具链反馈越完整,这个循环就越容易自动化。
MoonBit的AI-native设计也体现在语言结构上。其官方博客曾讨论过flattened design:明确区分toplevel和local definitions,toplevel definitions强制类型签名,并采用structural interface implementation,减少额外嵌套代码块。博客还提到,这种减少嵌套的设计不只提升可读性,也更KV-cache friendly,有利于RAG、decoder correction、backtrack等场景下的模型推理效率。
对开发者来说,这意味着更清晰的代码组织;对模型来说,则意味着更适合线性生成。模型不用在复杂嵌套结构里频繁来回跳转,上下文组织更稳定,生成错误也更容易被工具链及时发现。
过去评价一门编程语言,通常看性能、语法、类型系统、标准库、工具链和生态等。到了AI编程时代,还要多一个维度:模型是否容易学会这门语言。
这篇论文的价值也正在于此。它不只是指出“大模型不会天然写新语言”,更重要的是给出了一条可执行路径:先构建benchmark,知道模型哪里不会;再利用真实代码和官方文档继续训练,让模型掌握语言;最后通过instruction transferring,把指令跟随能力迁移回来。
MoonBit在这条路径中的表现说明,AI-native编程语言不只是一个概念,而是可以体现在模型学习效率、代码生成质量和工具链闭环中的工程优势。
大模型写Python很强,是因为它见过太多Python。大模型一开始不熟悉MoonBit,是因为MoonBit足够新。但当模型真正接触MoonBit的代码、文档和语言设计之后,它可以快速提升。
这也许正是AI时代新语言生态的核心问题:
不是等待模型某一天自然支持你,而是从语言、文档、工具链和数据开始,让模型更容易理解你。
MoonBit提供了一个值得观察的样本。
论文标题:《No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages》
链接:https://arxiv.org/abs/2606.16827
MoonBit相关数据来源:swe-agi (https://arxiv.org/abs/2606.16827)
文章来自于"量子位",作者 "宗恩"。
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

