Prompt还没退场,Loop已经开始接管AI叙事。
这两周,硅谷开发者圈最热的词之一,是Loop Engineering。
它讲的是一件很“Agent时代”的事:别再手动一轮轮prompt模型了,去设计一个循环系统,让AI自己执行、检查、修正、继续跑,直到任务完成。
传统模式以prompt为核心,现在开始转向以工作流为核心,这也是它突然爆红的原因。
而就在大家热议“怎么让AI自己跑起来”时,另一条更硬的线也在快速升温:Looped World Models(循环世界模型),简称LoopWM。

如果说Loop Engineering解决的是“AI怎么持续干活”,那LoopWM更像是在回答一个上限更高的问题:
AI在持续干活时,能不能做到持续理解、修正、推演它所面对的世界。
这也是为什么,它虽然名字里也有“Loop”,但其展现出的技术含金量和想象空间,明显不是一个量级。
它登上了Hugging Face Papers当日Top1,现已进入了AI社区更广泛的公共讨论。
Loop Engineering为什么突然火了
Loop Engineering为什么会火,其实很好理解。
因为单次对话适合问答,不适合复杂任务。
真要让AI去写代码、调试、调工具、看结果、修bug、再验证,它必须进入一个“行动—观察—推理—继续行动”的闭环。
换句话说,AI不再只是“答你一句”,而是开始“围绕目标持续推进”。
这正是今天Agent热的底层逻辑之一。
Google Chrome工程负责人Addy Osmani,引用过一个挺直白的判断:
你不该再亲自prompt agent,而该去设计那个prompt agent的loop。
在这套叙事里,人从“亲自操作模型的人”,变成“设计自动化系统的人”。
这也是Loop Engineering特别像硅谷热词的地方:它不是一个技巧,是一次身份迁移。
人从提示者,变成了系统设计者。
但问题也随之出现。会循环,不等于会理解。
一个Agent可以不断调接口、读日志、改参数、反复试错,但如果它对环境状态、动态变化、因果关系没有更稳定的建模能力,它仍然更像一个“更勤奋的自动执行器”,而不是真正具备世界理解能力的系统。
也正因此,LoopWM才显得格外关键和重要,它是在重写“AI如何反复推演世界”。
这件事,被一家中国叫脸谱心智的初创公司做了
接下来,让我们深扒一下是谁做了这件事:
论文作者FaceMind Research Asia(脸谱心智),是这篇文章的通讯机构。

据了解,公司已完成数千万元Pre-A轮融资,投资方为星连资本,老股东360超额跟投,陆奇的奇绩创坛也参股了。
公司由95后博士陆弘远及韦怡然创立,团队早期从端侧全模态模型切入,随后将重心转向更底层的世界模型研究。
相比只会生成内容的大模型,世界模型更强调对环境、界面与任务过程的持续理解和预测,这也被视为AI走向GUI Agent、具身智能与机器人场景的重要基础。
围绕这一方向,脸谱心智正通过循环迭代、参数高效的模型架构,提升模型在长时序预测、屏幕理解和具身任务中的稳定性,并已在仿真具身环境、GUI Agent环境和真机机械臂环境中展开验证。
一家年轻公司,正在试着把“理解世界”这件事,做成下一代AI基础设施的一部分。
对此,星连资本合伙人李文珏表示,脸谱心智团队最突出的特点,是兼具扎实的研究能力和复杂工程落地能力。
团队核心成员长期深耕人工智能底层技术,既能对前沿方向形成独立判断,也能快速将研究成果放入真实场景中验证。“我们看好的是一支人才密度高、技术判断前瞻、执行能力很强的团队。”
在李文珏看来,陆弘远身上兼具年轻研究者的探索欲和创业者的行动力,能够带领团队持续挑战高难度问题,并将技术判断转化为明确的研发方向。
 △脸谱心智Founder陆弘远
△脸谱心智Founder陆弘远
这种创始人特质和团队凝聚力,是星连资本决定投资的重要原因。
脸谱心智的投资方360集团投前负责人向其奇表示:“陆博士是我见过最顶尖的年轻AI研究者之一。”
在他看来,陆弘远关注的并非局部优化,而是模型底层原理和架构创新。
当行业还在讨论世界模型概念时,脸谱心智已经从零训练世界模型,并在多种benchmarking上得到了行业SOTA级别成果。
此后,陆弘远提出的Adam’s Law受到海外头部模型厂商Anthropic的关注和验证,团队最新提出的Loop循环架构则进一步探索世界模型长时序训练问题。

“迭代速度惊人。每次沟通前,我都会先去看他们最新发布的论文和技术报告。”向其奇感慨,从他们身上真正体会到了什么叫做“一次投资,终生学习”。
关于为什么是一家中国的初创公司能做出这样一项工作,陆弘远回答:
中国现在是一个高密度AI人才的国家,这是我们能做出一篇划时代的世界模型工作的主要原因之一。
FaceMind未来也会被更多的国际视野所捕捉,就像他们的工作前几周刚刚在X上被Anthropic/Facebook的投资人Accel点赞了。
论文到底做了什么?
说得直白一点,LoopWM干的事是:
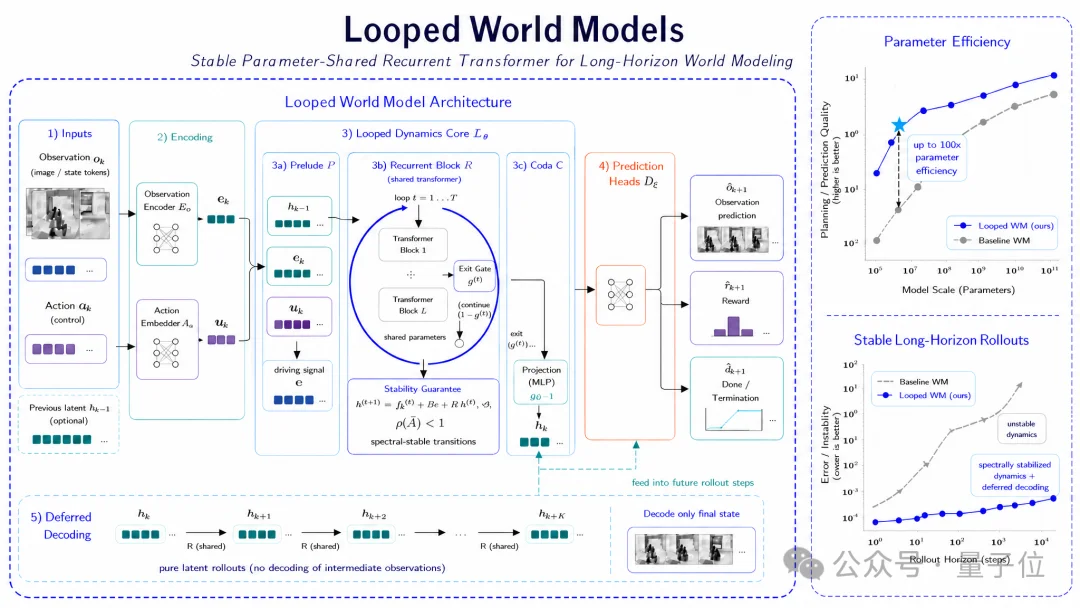
不再让模型一次前向传播就把世界状态“猜完”,而是让它通过共享参数的Transformer模块,对潜在环境状态做反复迭代细化。
这背后有个很实际的矛盾。
要做高质量、长时程的环境模拟,计算必须足够深;但模型一旦做深,参数量和推理成本就会一起飙升。
而且rollout越长,误差越容易层层累积,最后把整个模拟拖垮。
论文里的原话是:
faithful long-horizon simulation demands deep computation, but deeper models are expensive to deploy and prone to compounding errors。(高保真的长时程模拟需要深度计算,但模型越深,部署代价越高,误差累积的风险也随之上升。)
LoopWM的思路是,把“深度”从一次性堆叠,改成循环式复用。
它不用每加深一点能力就新增一大堆参数,而是通过共享参数的transformer block,对同一个latent state(潜空间表示)反复做refinement(细化)。
简单场景少跑几轮,复杂场景多跑几轮,计算深度开始跟随任务复杂度动态变化。
论文把这件事概括成一条新的scaling axis(扩展维度):iterative latent depth(迭代潜空间深度),独立于模型规模和训练数据之外。
世界模型变强,以后未必只能靠“更大”,也可以靠“更会反复想”。
数字是最有说服力的部分。论文给出的结论包括:
- 参数效率最高可实现100×提升;
- 对于简单状态转移,单步推理FLOPs可减少约25×;
- 在长时程rollout中,整体计算节省最高可达两个数量级。
这些都不是“说法上的优化”,而是直接指向部署成本、推理效率和长程稳定性的核心指标。
根据论文报告,在ScienceWorld基准测试上,LoopWM能在world modelling垂类任务上,比肩参数量高出两个数量级的更大模型。
这意味着它不是“用更大的模型赢了”,而是用更聪明的计算方式赢了部分关键任务。
这不只是Agent升级,是AI认知层在换挡
AI社区里有一种正在变清晰的焦虑:
光会说话不够,光会调工具也不够,真正难的是在长链路、动态环境、复杂反馈里,维持稳定的推演能力。
Loop Engineering对此给出的答案是闭环,让AI能自己推进。
LoopWM走得更远一步:给AI一套机制,让它在推进过程中对世界状态进行反复、稳定、按需的计算。
X上关于LoopWM的讨论,也从侧面说明了这件事的分量
社区的注意力没有停在“100×参数效率”这个口号上,而是落在几个更本质的技术词汇:
shared transformer block(共享Transformer模块)、adaptive compute(自适应计算)、spectral stability(谱稳定性)、deferred decoding(延迟解码)、iterative latent depth(迭代潜空间深度)……
这些词背后指向同一个判断:世界模型可能终于找到了一条比“继续堆参数”更优雅的进化路径。
过去一年,Agent最大的变化,是让AI从“回答工具”变成“执行工具”。
LoopWM指向的变化,则更进一步,是从“执行系统”往“世界建模系统”迈一步。
前者解决效率问题:怎么少点人工、多点自动化。
后者解决的是上限问题:
当AI真正进入机器人、仿真训练、空间交互这类复杂环境,它靠什么维持对世界的连续理解。
李飞飞谈到空间智能时说,今天的大语言模型擅长处理语言,却缺乏对物理世界真正扎根的理解;而世界模型,正是通向这种空间与物理理解的重要基础设施。
LoopWM的意义就在这条线上:它把Loop这个原本属于Agent工作流的概念,第一次明确推进到了world model本体里,换的是一套增长逻辑,不是修修补补。
硅谷先聊热的是Loop Engineering——贴近开发者体验,也更符合“让AI自己跑起来”的叙事。
但把时间拉长,真正值得反复看的,可能反而是Looped World Models这类工作。
因为它试图回答的是,AI在自动运行中,能不能真正理解世界。这一点决定了系统明天能不能长大。
Prompt Engineering定义了AI如何回应人,Loop Engineering定义了AI如何持续做事,而Looped World Models定义的,可能是AI如何在做事时真正理解世界。
论文链接:https://arxiv.org/abs/2606.18208
文章来自于"量子位",作者 "允中"。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

