上个月也就是昨天,我写了一篇LongCat 2.0的实测,用四个任务测了一下它的编程能力,当时我的评价是「有些地方惊艳,有些地方还差点意思」。

那篇发完之后,我一直在想一个问题。
那次测的都是相对常规的任务,写个Web页面、修个Python脚本、整理一份报告。这些任务能看出模型的基本功,但看不出一件事,
它能不能从头到尾、独立完成一个完整的产品?
而且这次我想换个玩法,不是我来写需求文档让它执行,是让它自己先规划、自己再执行。
就像一个真正的开发者那样,先想清楚要做什么,再动手做。
所以我决定搞个大的。
我给LongCat布置了一道作业,做一个俄罗斯方块
为什么选俄罗斯方块?
两个原因。第一,所有人都知道俄罗斯方块是什么,不需要我解释规则。第二,俄罗斯方块看起来简单,但实际上涉及的东西一点都不少,旋转系统、碰撞检测、计分逻辑、速度曲线、多模式切换,再加上移动端触屏操作和UI界面。如果AI能搞定这个,那它能搞定大多数中小型H5项目。
而且最关键的一点,俄罗斯方块不需要美工。
纯Canvas画出来的方块,颜色区分七种形状,再加几条网格线,视觉上就已经够看了。这意味着从头到尾不需要打开任何设计软件,全部交给代码解决。正好验证一个假设,LongCat到底能不能包办从零到成品的全过程。
但这次我换了一个思路。
上次是我当教练,给它布置任务,然后看着它执行。这次我想试试另一件事,让它自己当项目经理。

我把Codex的计划模式打开,告诉LongCat,「帮我规划一个俄罗斯方块H5游戏,要有五种玩法,不需要美工,纯代码完成」。
然后LongCat就开始自己写文档了。
先出了一份PRD,产品需求文档。定义了五种玩法模式。马拉松模式,经典规则,消行升级加速。40行冲刺,比谁用时最短。180秒限时挑战,倒计时内抢高分。隐形模式,方块落地后逐渐消失,逼你靠记忆操作。20G极速模式,方块瞬间落底,考验预判和手速。
接着出了一份TRD,技术需求文档。定了技术方案,TypeScript加原生Canvas 2D,不依赖任何游戏框架,Vite构建,SRS标准旋转系统,7-bag随机生成器。移动端和桌面端都要支持。
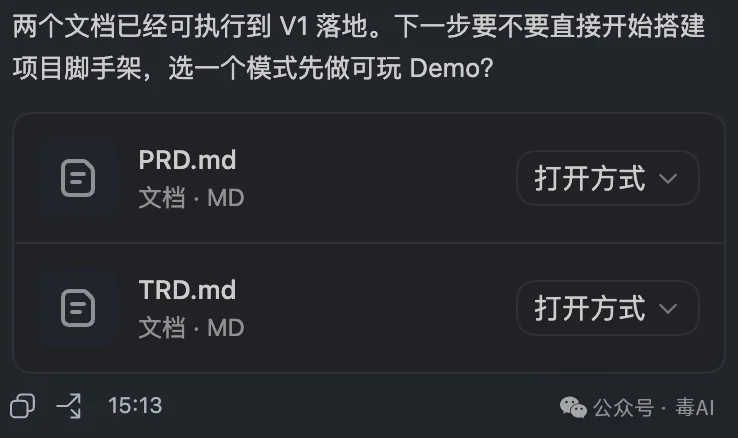
两份文档自己给自己写好了,加起来快两万字。
然后我告诉它,「按你自己写的文档,做出来。」
然后我就去干别的了。
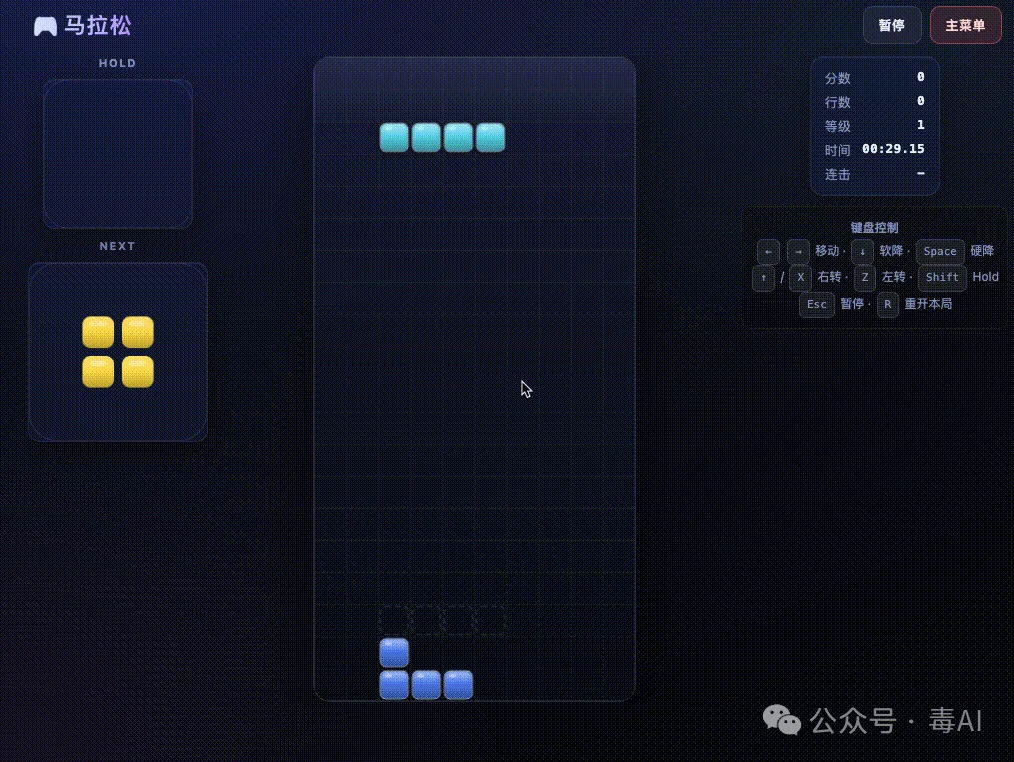
第一版出来了,能跑,但真的丑
大概50分钟后回来,LongCat还在跑。Codex有个功能,你设定了目标它会一直自己运行,中间不用你管。我回来的时候,第一版已经生成了。
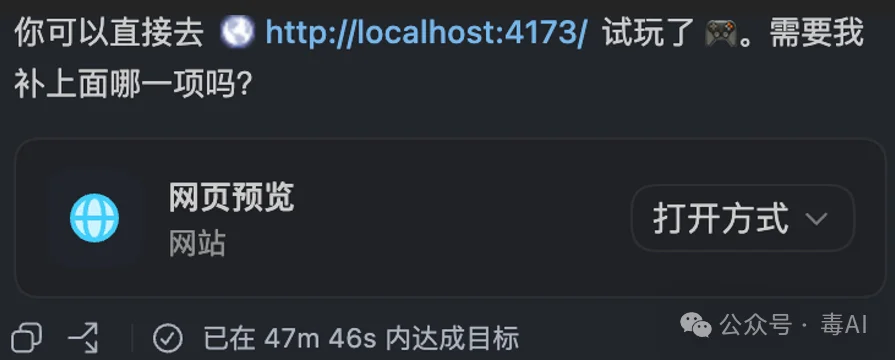
能跑。
五个模式全都能玩,马拉松可以正常消行计分升级,40行冲刺能计时,限时模式倒计时正常。计分规则也基本对,旋转系统用的是标准的SRS,7-bag生成器也没问题。
但怎么说呢,就像一个程序员花了50分钟写出来的MVP,功能是对的,但你真的不想多看第二眼。

用键盘操控不了,只能用屏幕上的虚拟按键点。方块的配色一言难尽,就是系统默认的那种纯色,没有阴影没有边框,整个画面看起来很平。菜单界面就是几行文字排在那里,你甚至分不清哪个是按钮哪个是标题。
该有的功能都有,但不该没有的东西一件也没给。
坦率的讲,我当时的心情是又满意又不满意。满意的是,LongCat自己写的需求文档自己真的能理解,而且一次性生成了五个可玩的模式。这意味着它不止会写代码,它已经能闭环了,规划、设计、编码,全部自己来。不满意的是,你明明可以把它做好看一点啊,为什么要搞这么丑。
第二轮之后,开始像那么回事了
我把第一版的问题列了出来,键盘操控不生效、方块配色需要改进、菜单界面需要重新设计、需要加ghost piece落点预览。
然后把这些问题又丢给了它。
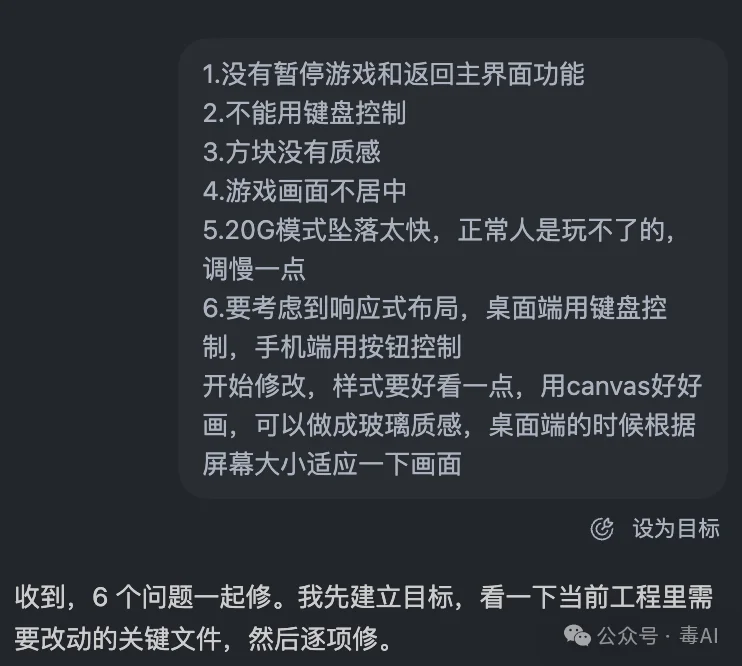
第二版出来的时候,我明显感觉不一样了。
键盘能用了,说实话这个让我有点意外,因为键盘操控涉及事件监听、键位映射、DAS和ARR这些概念,处理不好很容易出现按键延迟或者卡顿。但第二版的处理相当干净,左右移动、旋转、硬降、Hold,手感都在线。
方块的配色也调整了,I方块是青色,O方块是黄色,T方块是紫色,每种形状有自己的颜色,视觉上一眼就能区分。还加了网格线和方块边框,整个游戏区看起来终于不再是一坨了。
不过小bug还是有,比如隐形模式,我试了三次,方块落地之后完全没变化,该在的还在,不该消失的也没消失。说好的「隐形」呢?
我把这个问题指出来,它修了两轮才搞定。
说真的,玩隐形模式的感觉比我想象中要刺激得多。

你得时刻记住场地里已经堆了哪些方块,同时又要注意当前下落的方块位置。玩到后面,脑子里全是「左边第三列有个缺口,右边堆了两层,中间那个L块应该能塞进去」,然后一旋转发现,卧槽,这里刚才是不是有个方块来着?
这种压迫感,跟正常玩俄罗斯方块完全不一样。
五个模式,各自的故事
马拉松模式是第一个完工的模式,也是最顺的。一轮就搞定了,规则实现得干净利落,每消10行升一级,速度逐渐加快,从悠闲到紧张的过程很自然。计分系统也做得到位,消一行100分乘等级系数,消四行800分乘等级,T-Spin也有额外加分。
40行冲刺和180秒限时挑战也都是一轮过。这两个模式其实就是在马拉松的基础上改规则,冲刺模式加个消行计数器,到40就结算,记录完成时间。限时模式加个倒计时器,180秒倒数,最后10秒变成红色警告。逻辑上不复杂,LongCat处理得很快。
真正让我觉得有点意思的,是20G极速模式。
20G的意思是方块的下落速度极快,基本上就是瞬间落底。普通俄罗斯方块里,你有时间慢慢思考方块的摆放位置,但在20G模式下,方块一出现就要立刻决定旋转和位置,慢了就锁定在一个奇怪的地方。
第一版出来的时候,我试了一把,打开就结束了。
不是因为我反应慢,是因为速度确实快到了正常人根本来不及操作的程度。方块从生成到锁定的时间短到几乎没有,你刚看清是什么形状,它已经粘在地上了。
这个体验明显不对,20G考验的是预判和走位,不是考验人类极限反应速度。我把这个问题反馈给它,让它把锁定延迟加长了一点,同时保证ghost piece和next预览一定开启,这两个辅助在20G模式下不是锦上添花,是必需品。

修了两轮之后,20G的手感对了。快,但不至于绝望。每一块落地的瞬间你需要马上看下一个预览,手已经在做下一步的预判了。那种连续操作的节奏感,玩进去了真的很爽,可惜我技术不到位,容易玩破防。
打磨了三轮UI,终于能看了
五种模式的玩法都搞定了之后,剩下的就是门面功夫了。
菜单、HUD、结算页面,这些都是用户第一眼看到的东西。第一版的菜单就是纯文字堆砌,五种模式的名字排成一行,字体没有任何设计,像一个大学生用HTML默认样式写的课程作业。
我让LongCat重新设计了主菜单,给它描述了我想要的感觉,简洁、干净、有点游戏感但不是花里胡哨的那种。

第一轮改完之后,菜单有了基本的层次感,标题和按钮分开了,模式选择变成了卡片式的,每种模式有自己的一小段描述。但配色还是不太统一,有些地方字太小,有些按钮的位置很奇怪。
第二轮的调整好了不少,它自己把配色统一了一下,用了深色背景加亮色方块元素的搭配,基本就是俄罗斯方块自带的那种「电子游戏感」。按钮也调到了合理的大小和位置。
到第三轮的时候,整体已经比较顺眼了。结算页面会展示分数、用时、等级这些数据,还有一个按钮可以直接再来一局。移动端的虚拟按键也做了适配,可以切换左右手模式,按键大小和透明度可调。
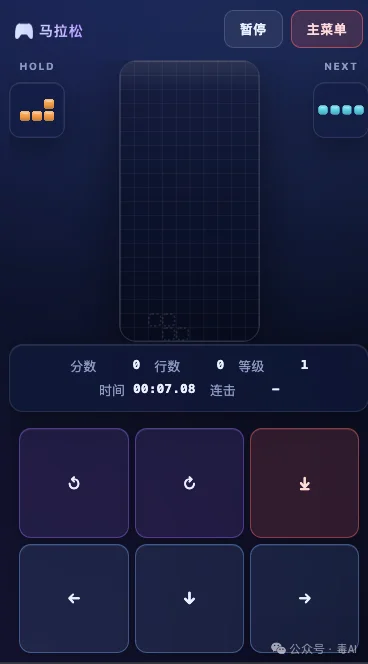
纯CSS搞出来的东西,能在三轮对话里打磨到这个程度,我是觉得OK的。没有到惊艳的程度,但绝对能看,而且能用。
我对LongCat 2.0做游戏开发的真实评价
好了,上面都在讲做了什么。这一部分聊聊我真正的感受。
先说结论,能做,但中间会踩不少坑。
LongCat 2.0搞定俄罗斯方块这件事本身,是做到的。五种玩法模式,SRS旋转系统,移动端触屏适配,菜单和结算UI,从头到尾没有写一行代码,全靠跟它对话完成的。
光说这个结果,放在一年前我是不信的。
但过程没有想象中那么丝滑,附上我破防的对话。
有些问题简单到离谱,但它就是反复搞不定。举个例子,中间有一次我需要它帮我启动一下本地测试服务器看看效果,一个npm run dev的事情,它反复试了好几次,换了好几种写法,最后是我自己手动敲命令启动的。
这种体感很有意思,它能搞定SRS旋转系统的复杂逻辑,能实现20G极速的重力算法,能在三轮对话里把一个UI打磨到能看。但有时候你让它做一个特别简单的事,它反而会卡住,而且卡住之后似乎不太敢尝试新的解法,一直在用差不多的方式重试。
这不是能力问题,更像是策略问题。就像一个很聪明但经验不足的程序员,遇到难题会花时间去研究,但遇到一个小问题,它以为很快就能解决,结果在错误的路上来来回回。
长任务的稳定性也有待提高。对比上次测的四个独立任务,这次是一个持续时间很长的大项目。能感觉到越到后面,它对前面已经修好的问题的「记忆」有些模糊了。偶尔会出现把之前修好的东西又改坏的情况,当然这也可能是Codex这一层的上下文管理问题,不完全算在LongCat头上。
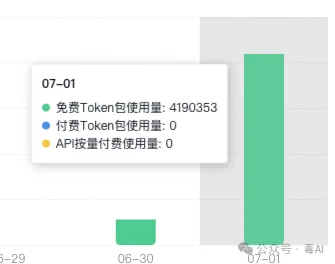
不过我必须要说一个让我很惊喜的地方,LongCat的token消耗速度是真的慢。
整个下午的开发,从第一版到五轮打磨,总共才消耗了大概4M多的token。4M什么概念?换成GPT或者Claude做同样的事情,消耗可能早就是几倍甚至十几倍了。虽然这个项目本身规模也不算很大,但这个消耗效率确实是我用过的所有模型里最好的。
还有一个有意思的细节,LongCat在写代码的过程中,会把自己的思考过程也展示出来。你能看到它在想什么,「这个地方用户可能会觉得按钮太小」、「这个配色可能太单调了」、「要不要在这里加一个动画效果」。就像一个程序员在自言自语,还挺可爱的。

这种感觉跟用其他模型不太一样,其他模型给你的感觉是「你要什么我给什么」,LongCat给的感觉更像是「我在努力做,同时我想让你知道我是怎么想的」。

坦率的讲,这让我对它的态度都宽容了不少。
所以到底值不值得用?
如果你是开发者,想用AI帮你快速出H5小游戏的MVP,LongCat 2.0是可以用的。尤其是在token消耗上确实有明显优势,做中小项目很划算。
但你得做好心理准备,它不是那种你把需求丢进去然后躺着等完美输出的工具。它更像一个基础不错的实习生,能力是有的,但你得盯着,得指导,有时候还得帮它解决一些你自己两秒钟就能搞定但它怎么都绕不出来的问题。
跟GPT或者Claude比的话,在效率上还有差距。GPT在面对一些简单问题时的反应更快、更准,不会在小问题上反复绕。LongCat有时候特别像一个过于认真的学生,会的问题也要确认三遍才敢写答案。
不过我始终觉得,做不做得到是一回事,能做到什么程度是另一回事。
LongCat 2.0从零搞出一个有五种模式的俄罗斯方块这件事,本身就说明国产模型的编程能力已经过了「能写代码」的阶段,进入了「能做产品」的阶段。而且这次最不一样的是,需求文档是它自己写的,从规划到设计到编码,一个完整的闭环跑通了。
这就意味着,随着后续版本的迭代,这些问题是可解的。
下一篇文章我可能会换一个更复杂的项目试试看,比如带后端接口的那种。如果你也在用LongCat做开发,或者有其他你觉得更适合做这种全栈项目的模型,欢迎在评论区告诉我。
文章来自于"毒AI",作者 "高晓阳"。

