近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。
近年来,受扩散模型其强大分布建模能力的启发,研究者们提出了基于扩散模型的样本增强方法(代表方法是 SynthER [1]),通过合成高保真样本实现训练数据的扩充。
然而,合成样本虽然符合真实环境动态,但未必最助于智能体的策略学习。为了更清楚地展示这一局限性,论文采用经典离线强化学习算法 TD3+BC [2],在合成样本集上训练智能体并评估其表现。实验在 Hopper 环境中的 medium-expert 样本集上进行。该样本集由 D4RL 基准 [3] 提供,包含约 200 万条直接从环境中预先采集的样本。合成样本集由 SynthER 合成所得,其规模设置为从 10 万条到 500 万条不等。
实验结果如下(原论文图 1b)。
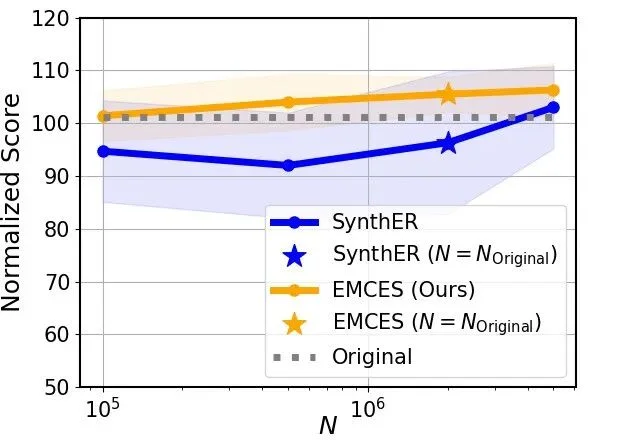
从图中可以看出,只有当合成样本集的规模远大于原始样本集时,合成样本才有可能充分覆盖高质量样本区域,并进一步获得相应的策略性能提升。这一观察揭示了当前基于扩散模型的样本增强方法所面临的局限性:其样本合成过程缺乏有效的可控机制,因而难以优先合成对策略学习更有价值的高质量样本。
针对这一局限性,浙江理工大学马啸讲师与南京大学李武军教授课题组联合提出了一种高效样本合成方法 EMCES。EMCES 将情景记忆机制引入可控扩散模型,并利用情景记忆机制引导高质量样本的合成,从而进一步提升下游强化学习算法的表现。
EMCES 是首个将情景记忆引入可控扩散模型,并利用情景记忆指导强化学习样本合成的工作。此外,论文提出了基于哈希的状态表示方法,以提升情景记忆机制的存储效率和检索效率。实验结果表明,在不损失下游强化学习算法表现的情况下,在存储开销上比已有的状态表示方法降低约 8000 倍,在时间开销上比已有的状态表示方法降低 25.5 倍。
该论文已被 ICML2026 录用。南京大学李武军教授为通讯作者,浙江理工大学马啸讲师为第一作者,南京大学硕士生李天为参与作者。

- 论文标题:Episodic Memory-Guided Controllable Experience Synthesis for Reinforcement Learning
- 论文地址:https://openreview.net/forum?id=mjYcL7esQO
1. 方法简介
情景记忆在人类大脑中发挥着重要作用,是人类快速学习与高效经验利用的重要基础。受此启发,在强化学习中,情景记忆能够存储、整合并检索有价值的历史经验,使智能体可以直接访问高质量的过往经验信息,从而提升强化学习算法的样本效率。
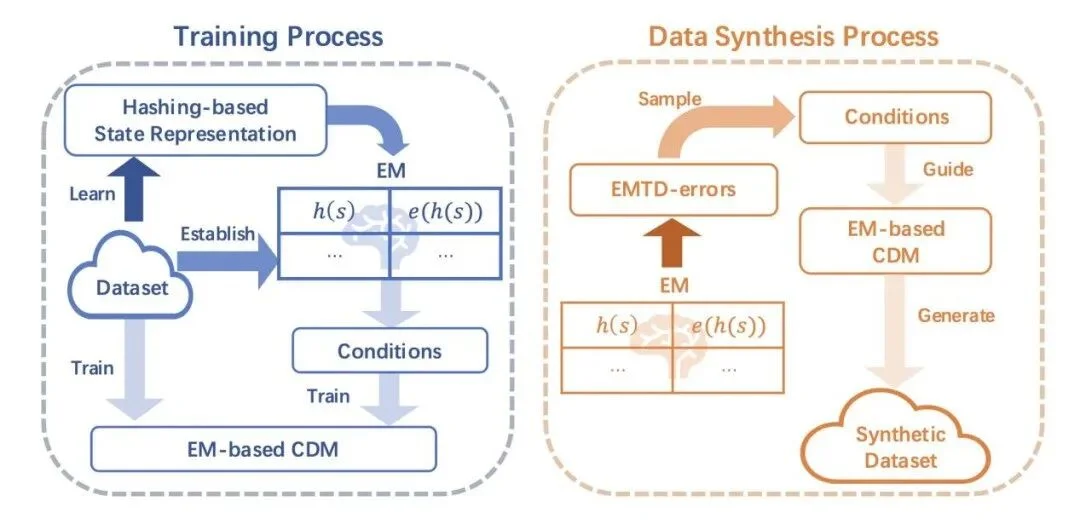
基于这一思想,EMCES 利用情景记忆存储历史经验中的高价值信息,为可控扩散模型设计控制条件,并引导可控扩散模型合成更高质量的样本。具体而言,EMCES 包含三个关键组件:基于情景记忆的可控扩散模型、基于情景记忆时序差分误差的优先条件采样策略,以及基于哈希表示的情景记忆机制。
EMCES 的架构图为:
1.1 基于情景记忆的可控扩散模型



1.2 基于情景记忆时序差分误差的优先条件采样策略
尽管基于情景记忆的可控扩散模型可以直接用于合成样本,但其核心优势在于能够以可控方式合成高质量样本。直观而言,样本合成过程不仅应当符合底层样本分布,还应进一步优先合成对智能体策略学习更有价值的样本。

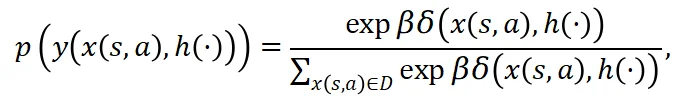

1.3 基于哈希状态表示的情景记忆

对于情景记忆机制,论文沿用团队前期工作 [5] 中的实现方式,即 KD-树。其对应的存储复杂度、检索时间复杂度和构建时间复杂度分别为:
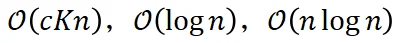


2. 实验结果
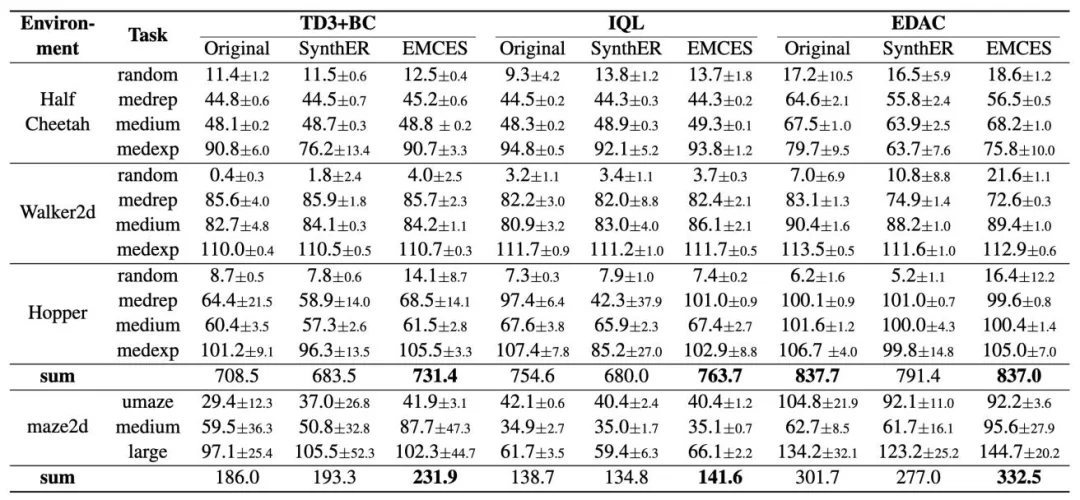
为验证 EMCES 的有效性,论文分别在离线强化学习和在线强化学习设置下进行实验。首先是在离线强化学习设置下,论文从 D4RL 基准中选取 HalfCheetah、Walker2d、Hopper 和 Maze2D 作为实验环境,选取 TD3+BC、IQL 和 EDAC 三种代表性离线强化学习算法对合成样本集的质量进行评估。下表中的结果表明,EMCES 在多数任务中提升了下游算法表现,并且合成样本训练效果经常达到甚至超过原始样本集训练效果(原论文表 1)。
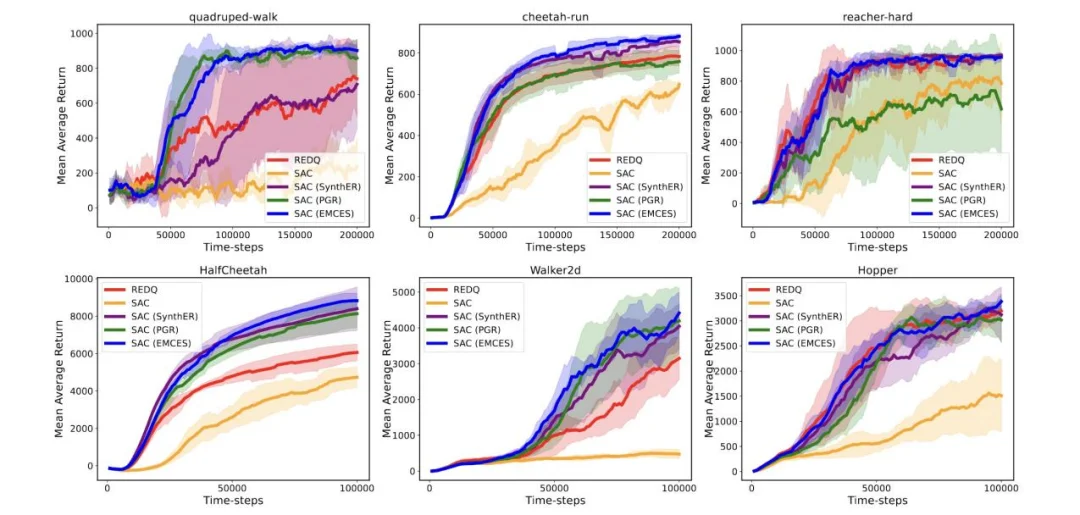
在在线强化学习设置下,论文选择了 quadruped-walk、reacher-hard、cheetah-run、Walker2d、HalfCheetah 和 Hopper 等 6 个环境来评估 EMCES。论文使用 SAC 作为在线强化学习算法。除了 SynthER 之外,论文还与一种专注于在线强化学习的样本增强方法 PGR [6] 进行对比。更多实验细节见原论文。下图结果表明(原论文图 4),SAC (EMCES) 能够持续提升样本效率,并优于 SAC (SynthER) 和 SAC (PGR),这表明 EMCES 合成的数据质量更高。
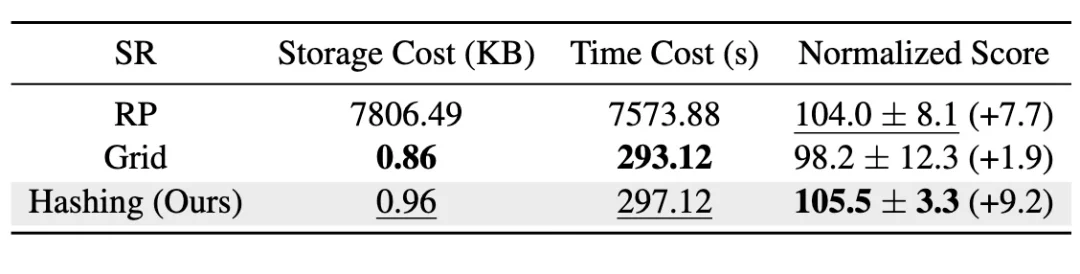
论文还对情景记忆中的状态表示方法进行了讨论。论文在表(原论文表 4)中总结了 EMCES 在不同状态表示下的归一化分数,括号中的数字表示 EMCES 在不同状态表示下相较于 SynthER 所取得的归一化分数提升。为了公平比较,所有实验在一台配备 36 核 72 线程 Intel Xeon Gold 6240 CPU @ 2.60GHz、377 GB 内存和 8 块 NVIDIA GeForce RTX2080Ti GPU 的工作站上进行。如下表所示,EMCES 在不同状态表示下均取得了优于 SynthER 的表现。
这一结果验证了 EMCES 整体框架的有效性。同时,下表汇报了在不同状态表示下,建立情景记忆机制所需的存储成本和时间成本,其中时间成本同时包括检索时间成本和构建时间成本。可以发现,基于哈希的状态表示和基于网格的状态表示均能显著降低存储和时间成本。与基于随机投影的状态表示相比,在不损失归一化分数的情况下,基于哈希的状态表示将存储成本降低了约 8000 倍,将时间成本降低了约 25.5 倍。此外,论文还对可控扩散模型的条件设计、采样策略的设计进行了消融实验,更多讨论可见原文。
3. 全文小结
EMCES 具有如下优点:
- 合成过程强可控: EMCES 将情景记忆机制引入可控扩散模型中,通过情景记忆机制构造条件,引导扩散模型合成与目标任务更相关的样本,从而提升了样本增强的可控性;
- 合成样本质量高: EMCES 利用情景记忆时序差分误差评估样本对于策略学习的潜在价值,并在采样过程中优先关注更具潜在价值的样本区域,从而合成高质量样本;
- 情景记忆高效性: 采用基于哈希的状态表示后,情景记忆机制能够在不损失下游强化学习算法表现的情况下,在存储开销上比已有的状态表示方法降低约 8000 倍,在时间开销上比已有的状态表示方法降低 25.5 倍。
参考文献:
[1] Lu, C., Ball, P. J., Teh, Y. W., and Parker-Holder, J. Synthetic experience replay. In NeurIPS, 2023b.
[2] Fujimoto, S. and Gu, S. S. A minimalist approach to offline reinforcement learning. In NeurIPS, 2021.
[3] Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4RL: datasets for deep data-driven reinforcement learning. CoRR, abs/2004.07219, 2020.
[4] Kong, W. and Li, W.-J. Isotropic hashing. In NeurIPS, 2012.
[5] Ma, X. and Li, W.-J. State-based episodic memory for multi-agent reinforcement learning. Machine Learning, 112(12):5163–5190, 2023.
文章来自于"机器之心",作者 "机器之心"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

