做大模型RL微调,你是不是也踩过这些坑?
强化学习训练总不稳定、正负样本梯度难区分,过往依赖经验手动分配Token权重的方式,始终没法拿到最优训练效果。
来自人大高瓴的研究团队针对这些问题,提出了一种新的token credit assignment算法——DelTA。DelTA不依赖经验或直觉,而是通过求解优化问题,为强化学习目标中的每一个token计算最优权重。
实验显示,DelTA适用于几乎所有主流强化方法,能够适配当前主流强化框架,并在数学推理、代码生成、知识问答等10余个任务上,为不同尺寸、不同类别的base模型带来显著提升。

看似复杂的强化学习原来是个线性判别器



DelTA的核心思路:通过优化线性判别器来让token更有区分度
在标准DAPO中,每个token被等同看待,但实际上正确的回答和错误的回答在文本上往往有很多重叠,这些重叠的token将不可避免降低正负质心的区分度,那么一个自然的解决方法就是给token加权,让有区分度的token对质心的影响更大,从而让最后的正负质心离得更远,这就是团队提出的DelTA(Discriminativesignal-guided Token Credit Assignment)算法。
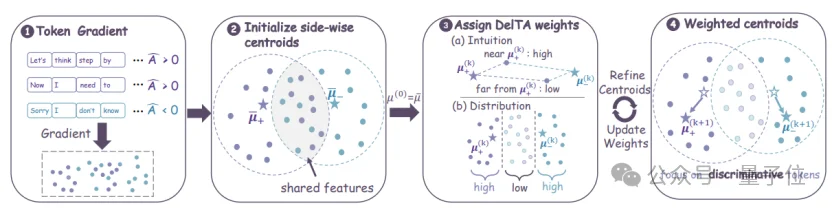
具体实现上,DelTA并不是通过“拍脑袋”来设计token权重,而是通过求解优化问题,迭代式地计算最优权重和质心:
- 第一步:计算权重
在第k步,给定正负质心,token权重由下面优化问题的解决定:
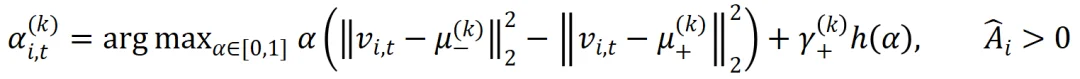
直观上,如果一个token对应正advantage(比如来自正确答案),那么优化问题希望让它离正质心更近,离负质心更远。类似也可以定义负advantage的优化问题。最后得到最优权重如下:
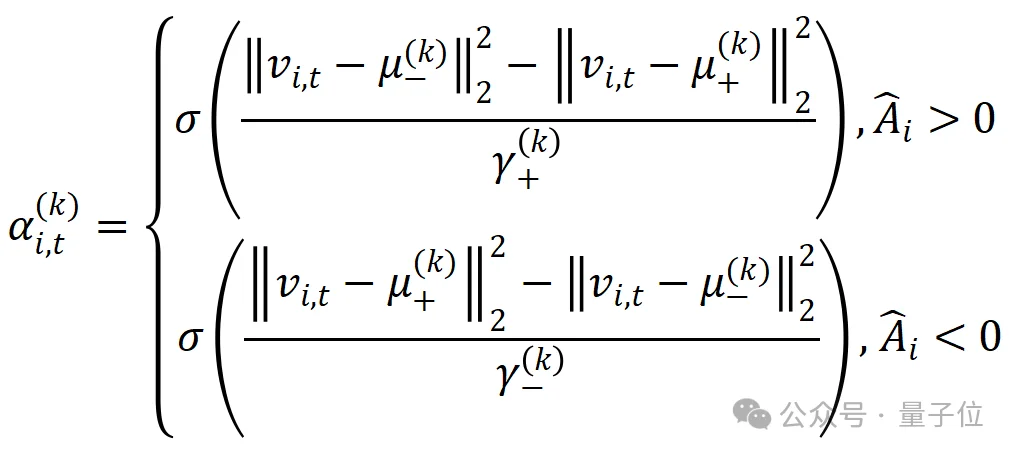
- 第二步:更新质心
有了权重,就可以对token进行加权得到新的质心:
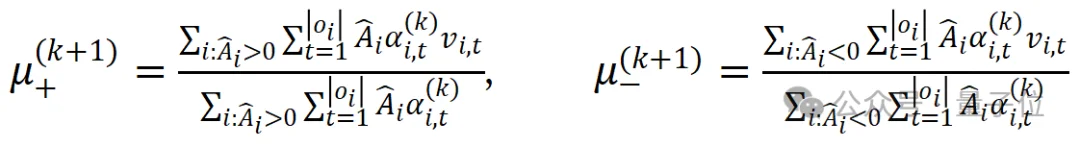
直观上,权重越大,该token的区分度就越大,对质心计算的影响也就越大。这样得到的正负质心相距更远,从而更具区分度。
- 第三步:迭代收敛后将所得权重代入强化学习目标,运行强化学习算法。
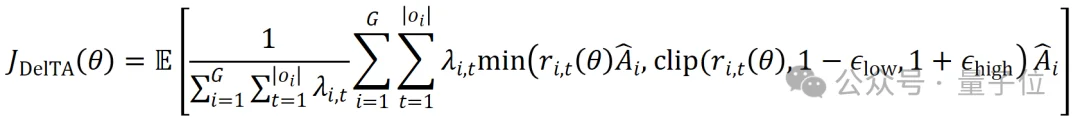
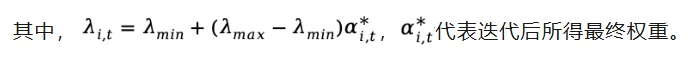
实验表现:数学代码推理全面SOTA,并在知识推理上泛化良好
- 7个数学推理任务上相较最强算法分别提升3.26(8B)和2.62(14B)。
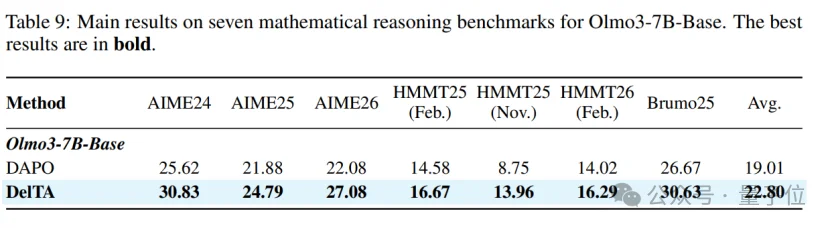
实验选取Qwen3-8B-base和Qwen3-14B-base作为基础模型,在AIME24,AIME25,AIME26,HMMT25(Feb.),HMMT25(Nov.),HMMT26(Feb.),以及Brumo25上和DAPO,DAPO with forking tokens,SAPO,以及比较新的FIPO进行了比较。在每个数据集上,DelTA都能显著超过同模型尺寸下最好算法。
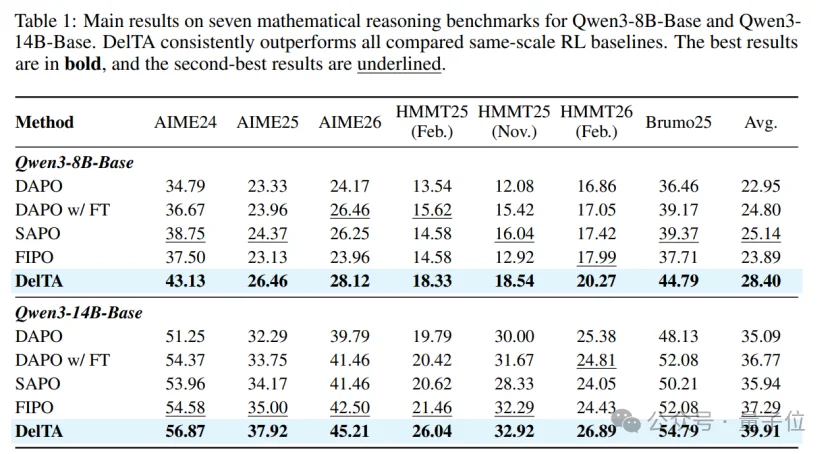
更有趣的是,相比已有算法提升reward的同时会导致token熵变大(更鼓励探索),DelTA同样带来了比较可观的reward提升,但是token熵却在下降,说明DelTA在分清了正负token后,能够更有效地利用区分度大的token进行训练,从而有可能让训练更加稳定。
- 效果不止于Qwen。
除了Qwen3,研究团队还在Allen Institute最近发布的Olmo3-7B-base上进行了实验。结果显示,DelTA依然十分有效,说明该算法并不依赖基模选择。
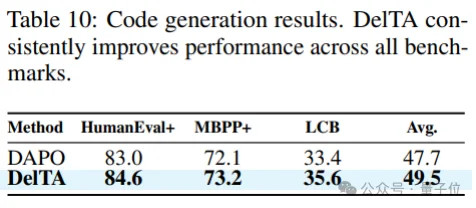
- 代码生成同样有效。
研究团队利用代码数据训练DelTA,并在包括HumanEval+,MBPP+,以及LiveCodeBench上进行了实验。结果显示,DelTA在代码生成任务上同样有效。
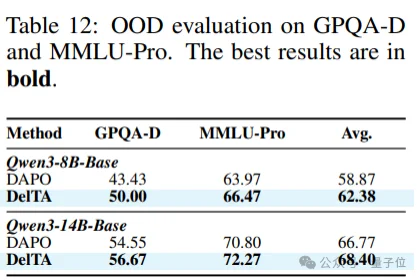
- 泛化能力优越。
为了检验DelTA训练后模型的泛化能力,研究团队将数学数据上训练的Qwen3-8B-base直接应用到GPQA-Diamond以及MMLU-Pro上。结果显示,DelTA除了能够显著提升DAPO在数学推理上的效果,还能为其带来泛化能力上的提升。
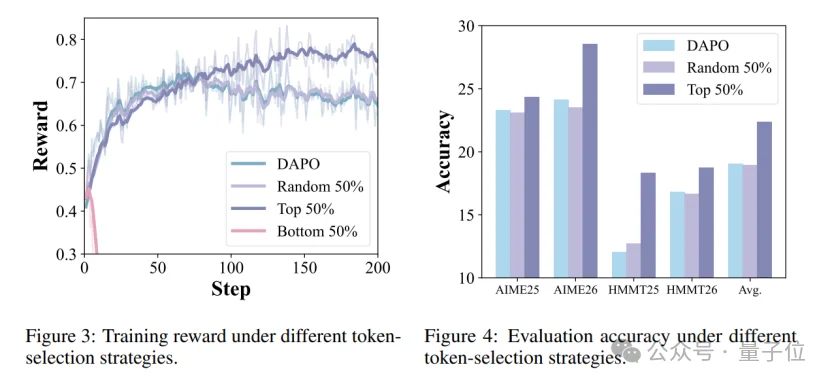
- 指标提升在于学到了正确的token权重。
指标提升了,但token权重学对了吗?为了回答这个问题,研究团队做了个有趣的实验。
他们按DelTA给出的权重对rollout中的token排序,只用前50%高权重token来计算DAPO损失,并与随机50%和后50%两种选择作对照。结果发现,只训练前50%高权重token不仅超过随机50%,甚至还能超过全量DAPO;而只训练后50%低权重token时,训练很快崩溃。这个对比说明,DelTA的权重并不是简单地做稀疏化,而是在把真正有学习价值的token梯度从共享或误导性的梯度中筛选出来。
面向未来
- 算法上跨越DAPO,模型上跨越14B。事实上,团队已经从数学上证明了DelTA并不依赖具体的强化方法,也不依赖verifiable reward,因此在更大的模型上,更多的在线强化算法上验证DelTA的有效性,是一个有趣方向。
- 实现上寻求更优近似。当前为了效率,研究团队在token梯度上做了非常大幅的近似,而这种近似势必限制了DelTA的性能。下一步,团队也在寻求效率上可接受,理论上更合理,效果上更优秀的梯度计算方法。
作者介绍
本作第一作者为人民大学高瓴人工智能学院二年级硕士张凯翼。
论文链接:https://arxiv.org/pdf/2605.21467
代码链接:https://github.com/RUCBM/DelTA
文章来自于"量子位",作者 "DelTA团队"。
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

