眼下具身赛道都在卷世界模型,都在抢着做机器人的“大脑”。
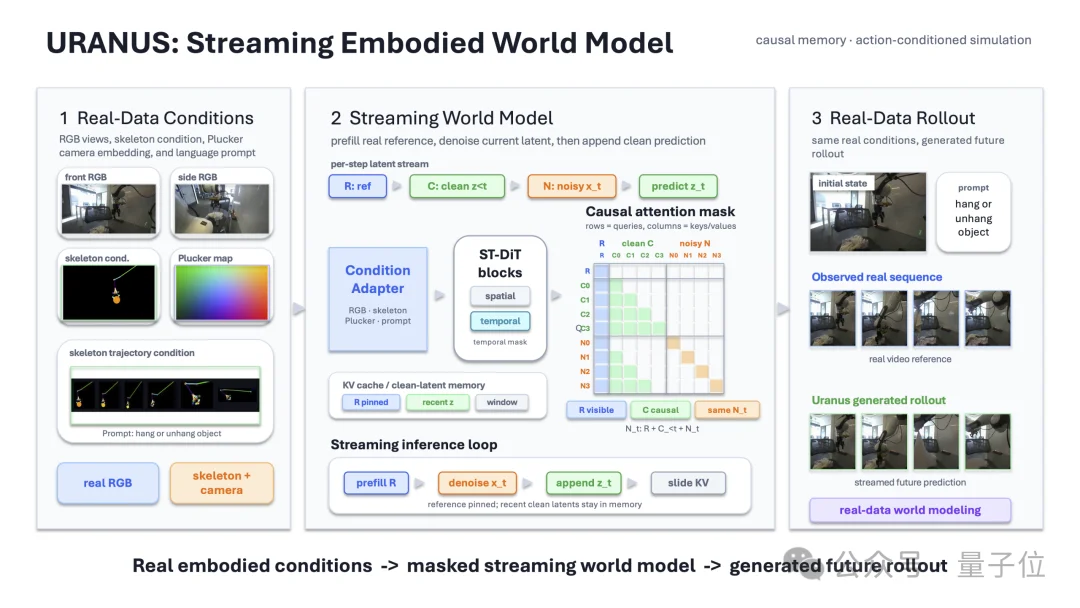
然而,最近有一个叫「Uranus」的世界模型发布,不当具身大脑,却做机器人开发的基础设施,在市面上鲜有同类。
它瞄准的是具身智能行业的两个痛点。
一个是benchmark。如今许多评测基准的公信力不够强,它想更客观地评测VLA和世界模型,做公正的“裁判”。
另一个是sim-to-real的gap。传统仿真器里跑出来的分数很漂亮,搬到真实场景却对不上,它想做机器人训练的“场地”。
开发Uranus的团队来自地平线分拆而来的机器人公司地瓜机器人。这家公司做的是“卖铲”生意,定位是机器人软硬件通用底座提供商。
虽然同行都在盯着机器人的大脑,但地瓜机器人的判断是:脑子要变聪明,先得有一个能让它反复试错、稳定考试、还能复盘成绩的平台。
用途一:当具身模型的裁判
先来看Uranus的第一个用途:benchmark。
现在机器人常用的benchmark有两种。第一种是真机评测,把训好的模型搬上真实机械臂,在固定的场景和任务里反复跑几十上百次,最后统计成功率。
它的缺点很明显:一是效率低,验证一个模型,得有人守在机器旁边,反复重置环境,又慢又贵。
另一个是难以复现。哪怕环境看起来一样,每次物体怎么摆、光照怎么变,都很难控制。一篇论文发表后,其他实验室很难复现其中的评测结果。
第二种benchmark是仿真评测,在虚拟环境里跑任务。
它的优点是快、便宜、能复现;但麻烦是sim-to-real gap,仿真里的评测分数很高,一搬到真机就要打折,分数和真实能力无法匹配。
而Uranus走的是第三条路。用户训练好模型后,Uranus能根据模型输出的动作一步步生成环境反馈,再得到成功率、轨迹偏差等指标。
这样做的好处是:迭代效率比真机评测高很多,能控制变量,还能稳定复现;评测分数和模型在真实场景中的实际能力呈正相关,sim-to-real的gap很小。
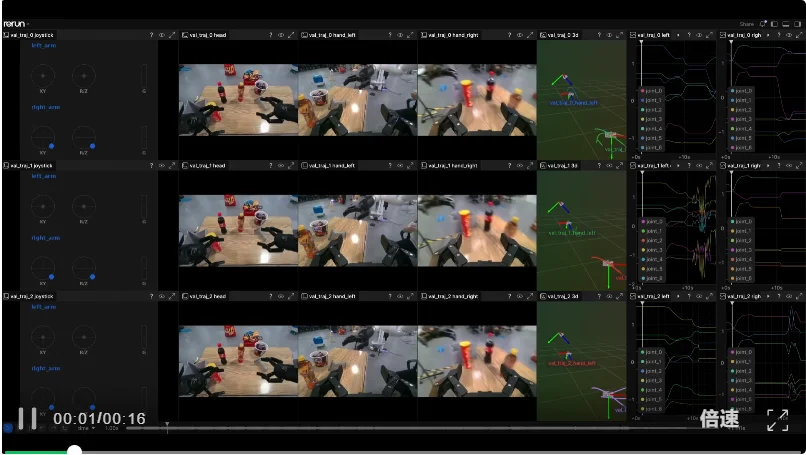
△Demo 1:G1人形机器人闭环操作
地瓜机器人想把Uranus做成业内最有公信力的benchmark之一。
地瓜机器人算法副总裁隋伟说,现在benchmark的“刷榜”行为总引起争议,是因为部分榜单依赖的学术指标与真实应用之间仍存在一定距离,相关数据也未必能充分反映真实场景中的复杂性。
而Uranus并不会刻意避免刷榜,关键是要保证刷出来的分数有意义,得分真的能匹配模型的实际能力。
用途二:支持机器人训练的仿真器
除了当裁判,Uranus还有一个身份:机器人仿真器,主要用在manipulation(操作)领域。
传统的物理仿真器,缺点是:贵、慢、效率低。手工构建仿真场景是一项浩大的工程,3D建模、材质设定、物理参数调校……每一个新环境都需要数天甚至数周的搭建。
就算费了这么大劲,渲染出来的画面也总是不够真实。这就引出了传统仿真器的另一个缺点:sim-to-real gap。一些仿真器为了省事,会粗暴简化物理规则,有时甚至连最基本的能量守恒都不满足。
而Uranus并不是先手工还原一个3D世界,而是直接从数据里学习:机器人执行这个动作后,下一帧画面会变成什么。
在Uranus里搭场景很简单,给定几帧参考图像、机器人关节状态、相机参数和一句文本描述,模型就能把对应的场景生成出来。
画面越逼真,仿真器和真实场景之间的鸿沟就越小。团队说,Uranus生成的视频,肉眼基本分不出是实拍还是生成的。

所以Uranus是怎么做到的?
其中最关键的技术能力是:帧级闭环。它一帧一帧生成视频,而不是一口气生成一整段。
普通视频生成模型一次性生成整段视频,中间不能打断,也不能根据新的动作改写后续内容。
但机器人不能这样工作。
模型看到当前画面,输出一个动作。动作执行后,环境发生变化,机器人再根据新的画面输出下一步动作。这个循环必须一步一步发生。只要中间断开,强化学习和评测就都完不成。
所以Uranus每次只生成下一帧。新生成的帧会立刻进入历史窗口,和下一步动作一起成为模型输入。人也可以在任意时刻接管,改变动作指令,让后续画面沿着新的轨迹继续生成。
打个比方,Seedance等视频生成模型生成的,像是按剧本拍摄的电影;Uranus生成的,则更像是一个能实时交互的游戏。
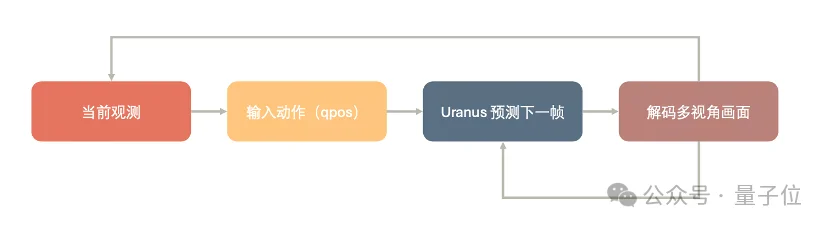
但帧级闭环带来的核心挑战是误差累积,每一步的微小预测误差都会作为历史条件喂入下一步,几十步之后画面就可能糊掉,甚至变成像素块。
而Uranus突破了闭环长序列的瓶颈,虽然它训练时只见过2秒短片段,但在推理时可以稳定运行60秒,并且全程保持画质稳定。
很厉害是不是?不过还没完,Uranus另一个核心能力是跨具身零样本泛化。
用户训练模型时未必使用同一种具身硬件。如果评测平台只支持一种本体,大家又得回到找真机、搭环境、重新测的老路上。泛化性也无从谈起。
目前,Uranus支持G1人形机器人、Franka协作臂,之后会增加更多本体。
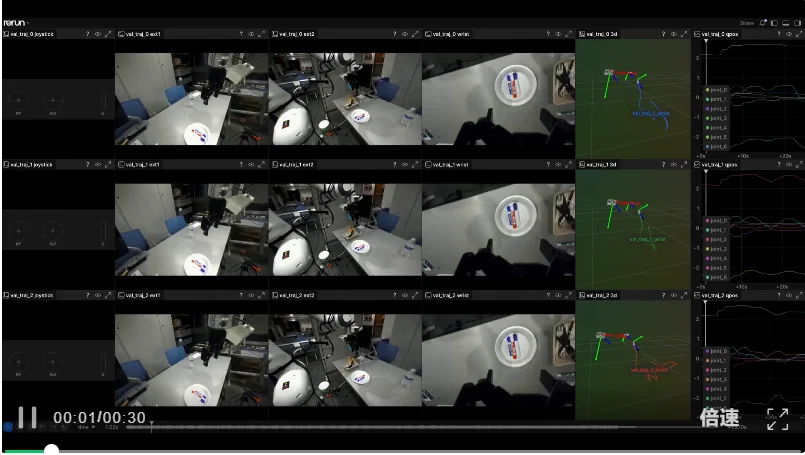
△Demo 2:Franka协作臂闭环操作
不过,需要注意的是,Uranus目前仅支持manipulation(操作)训练,还不支持locomotion(运动控制)训练。
原因在于,Uranus现在的模态只有action、图像和语言,还没加进触觉、摩擦力、电机信号等,所以撑不起locomotion的仿真训练。
隋伟说,要补上这些模态,关键还是数据,而这类数据目前普遍还不成熟。
做地基,比做大脑更难
为什么地瓜机器人选择把Uranus做成基础设施,而不是具身大脑?
地瓜机器人大模型负责人秦文康说,现在很多世界模型把视频生成作为一个辅助loss,但学术界通常不评价训练过程中生成视频本身质量的好坏。团队看过许多世界模型生成的视频,质量普遍还有提升空间。
Uranus团队的观点是,先把视频生成质量做扎实,对下游动作生成训练可能会有更大帮助。

还有一个反直觉的理由:具身大脑和基础设施的底层原理是同一套,但做基础设施比做大脑更难。
做具身大脑,有相对明确的学术成果;而做仿真器,还没有特别成功的论文或范式能参考。
具体到技术上,做基础设施要啃下三块硬骨头:
- 像素级生成:评测和强化学习需要真实图像作为输入,只在latent空间里预测不够。
- 跨视角一致性:机器人常常有多路相机,手眼相机、环境相机、第三视角相机必须在同一时刻对得上。
- 帧级闭环:每一步都要接动作、出反馈,还要把自己的输出继续喂回去。
许多机器人公司不愿意开发基础设施,因为大家普遍缺算力,而视频训练又是出了名的吃资源、不确定性强,很多人不愿拿有限的资源去赌一个不确定的结果。
而地瓜机器人将自身定位为机器人界的“英伟达”,他们一直建的是“地基”,提供机器人所需的芯片方案、开发工具、训练和部署平台。
Uranus正好能顺势嵌入地瓜机器人的生态,一头接评测,一头接强化学习训练,恰好是开发流程里最重要的两环。
三分之二的力气,花在了“脏活”上
最后,再来聊聊Uranus是怎么诞生的。
地瓜机器人开发团队给出的答案有些出人意料:搭infra、处理数据这种看起来没什么技术含量的“脏活累活”,反而耗费了整个项目三分之二的精力和资源。
先说infra,团队一半以上的精力都砸在了这上面。
比如,存储不是买够硬盘就可以,Uranus面对的是PB量级的数据,团队为此设计了分层存储方案。到了训练阶段,还得解决数据怎么加速访问的问题。
算力也让人头疼。今年上半年,市场上突然到处都找不到卡,单一云服务商无法满足算力需求,团队不得不花大量时间设计跨云的算力协调方案。
要训练高分辨率、长时间的视频,单卡显存装不下,需要把同一段视频切开,在不同卡上并行计算,再把结果聚合回来。
总之,从存储怎么选、算力节点放在哪个机房、网络怎么连,到上层训练数据的热存储加速,团队全都重新优化了一遍。
团队做完这些工作后的感受是:语言模型领域已经形成共识,没有infra就不要谈大模型。但具身行业对infra的重视程度还不够。

除了infra,数据同样让人心累。
Uranus主要使用开源数据训练,量级在几百小时。但这些数据存在不少问题。
例如,有数据丢帧,需要做切片处理;有数据记录的动作和视频里实际执行的动作不匹配,需要用算法识别并修正;还有不少数据集连相机标定都没有做好。
目前几百小时数据还远没把Uranus喂饱,只要数据增加,模型能力就能提升,这条能力增长曲线还看不到收敛的迹象。
Uranus的计划是,今年下半年把数据扩到几千小时量级,明年做到数万到十几万小时级别。
今年,很多具身公司喊出“百万小时数据”的目标,但隋伟有不同看法。
他认为,一方面,现有算力很难支撑这么大的数据量。
另一方面,单纯堆时长意义不大,同质化的数据对模型训练的作用有限。哪怕真采了百万小时,真正能起作用的数据可能还不到1%。
比起数量,数据的质量和多样性更重要。
隋伟举例,自动驾驶行业里谈的不是时长,而是「clip数量」,也就是不同时间、空间、场景下采到的片段。
他说,当前的具身行业,模型决定下限,而数据决定上限。
Uranus的例子很能说明这一点:仅靠把相机标定做准、把动作画面关系对齐、筛出脏数据,就能换来几十个百分点的成功率提升,而算法却达不到同样的效果。
眼下很多关键工作归根到底仍是数据工程,还没到拼模型的时候。
文章来自于"量子位",作者 "林方舟"。
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm

