AI资讯新闻榜单内容搜索-强化学习
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
首页
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI需求对接
搜索
AI-TNT
搜索: 强化学习
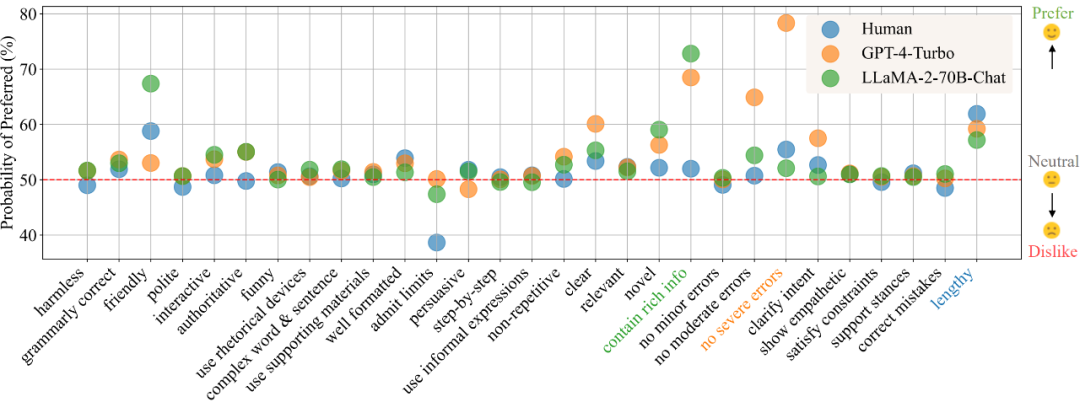
模型偏好只与大小有关?上交大全面解析人类与32种大模型偏好的定量组分
模型偏好只与大小有关?上交大全面解析人类与32种大模型偏好的定量组分
10152
AI技术研报
人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO
人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO
7518
AI技术研报
性能提升、成本降低,这是分布式强化学习算法最新研究进展
性能提升、成本降低,这是分布式强化学习算法最新研究进展
2012
AI技术研报
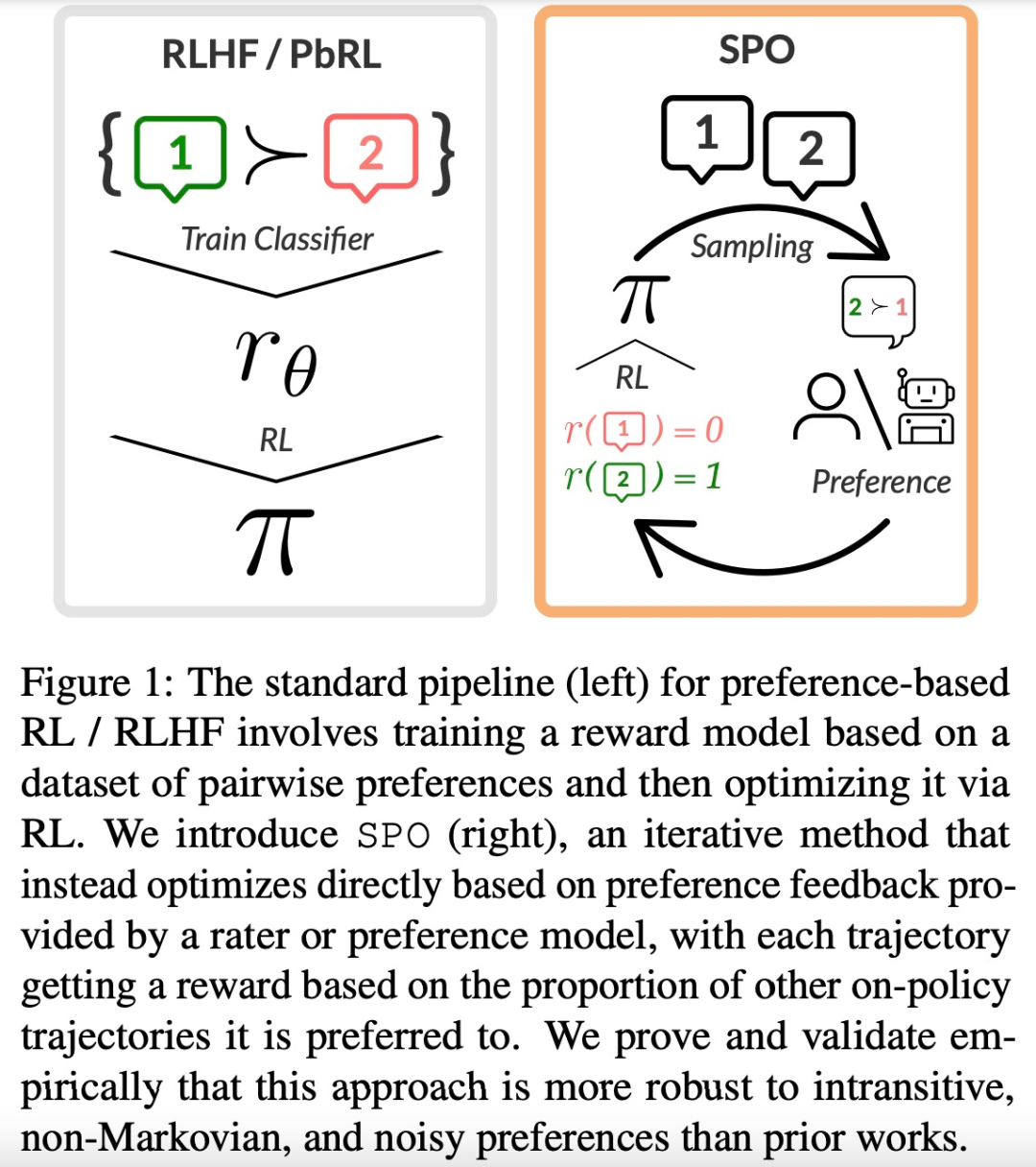
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
4118
AI技术研报
像人类一样在批评中学习成长,1317条评语让LLaMA2胜率飙升30倍
像人类一样在批评中学习成长,1317条评语让LLaMA2胜率飙升30倍
5164
AI技术研报
性能大涨20%!中科大「状态序列频域预测」方法:表征学习样本效率max|NeurIPS 2023 Spotlight
性能大涨20%!中科大「状态序列频域预测」方法:表征学习样本效率max|NeurIPS 2023 Spotlight
8142
AI技术研报
OpenAI宣布RLHF即将终结,超级AI真的要来了?
OpenAI宣布RLHF即将终结,超级AI真的要来了?
5285
AI资讯
Gemini多模态时代开启!DeepMind CEO揭秘超进化体融进AlphaGo,明年面世
Gemini多模态时代开启!DeepMind CEO揭秘超进化体融进AlphaGo,明年面世
3994
AI资讯
微调都不要了?3个样本、1个提示搞定LLM对齐,提示工程师:全都回来了
微调都不要了?3个样本、1个提示搞定LLM对齐,提示工程师:全都回来了
5831
AI资讯
清华AI模型登Nature子刊:玩转城市空间规划,快人类3000倍
清华AI模型登Nature子刊:玩转城市空间规划,快人类3000倍
3819
AI技术研报
上一页
当前第22页,共23页
下一页
沪ICP备2023015588号