AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
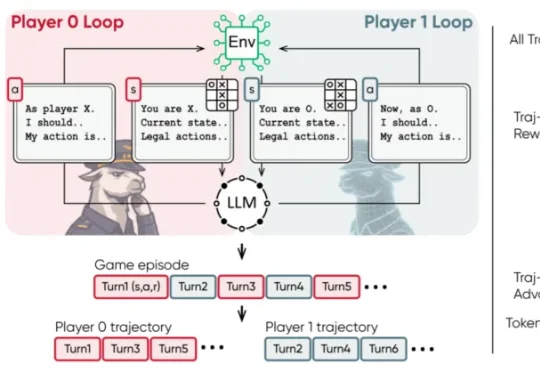
大模型如何泛化出多智能体推理能力?清华提出策略游戏自博弈方案MARSHAL
大模型如何泛化出多智能体推理能力?清华提出策略游戏自博弈方案MARSHAL
8403
AI技术研报
AI4S回归白盒符号主义,清华等联合发布SR-LLM:自主发现科学知识
AI4S回归白盒符号主义,清华等联合发布SR-LLM:自主发现科学知识
10014
AI技术研报
大模型第一股热闹正酣,“局外人”阶跃星辰发了一个小更新
大模型第一股热闹正酣,“局外人”阶跃星辰发了一个小更新
9085
AI资讯
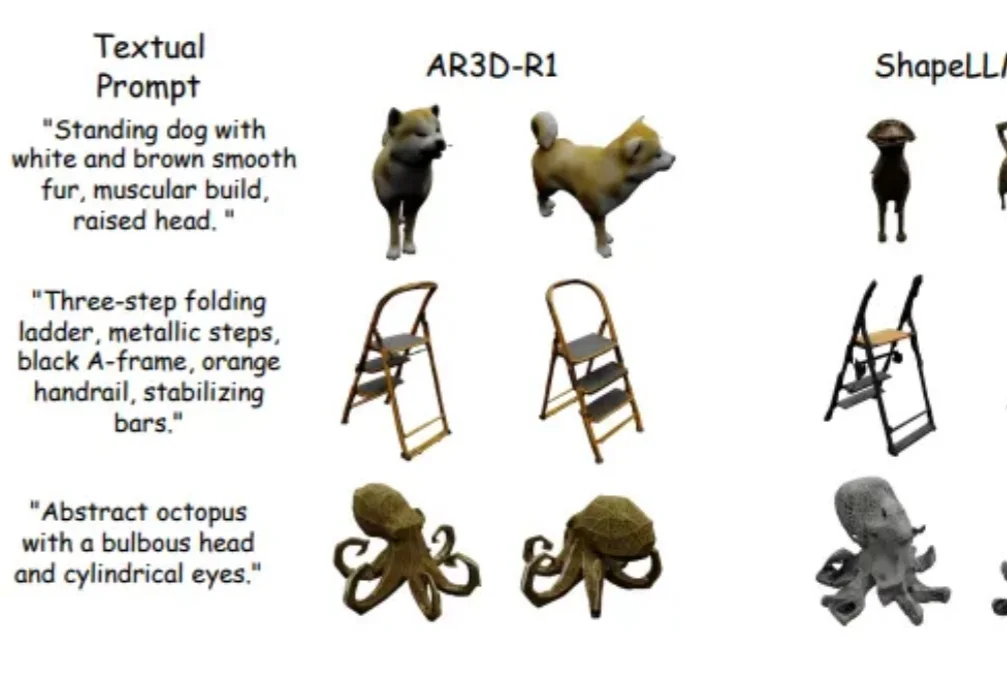
RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场
RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场
8318
AI技术研报
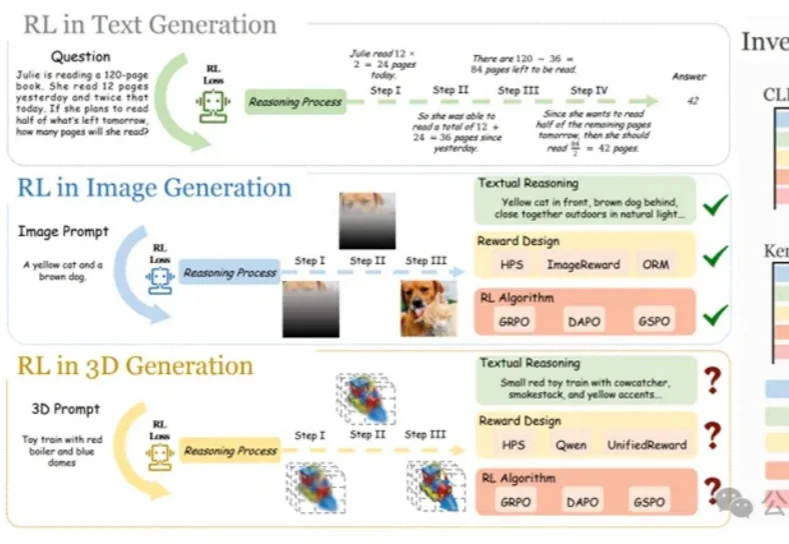
首个文本到3D生成RL范式诞生,攻克几何与物理合理性
首个文本到3D生成RL范式诞生,攻克几何与物理合理性
6241
AI技术研报
亚马逊AGI负责人离职,强化学习大佬Pieter Abbeel接任
亚马逊AGI负责人离职,强化学习大佬Pieter Abbeel接任
7727
AI资讯
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
6320
AI技术研报
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
8645
AI技术研报
全球强化学习+VLA范式,PI*0.6背后都有这家中国公司技术伏笔
全球强化学习+VLA范式,PI*0.6背后都有这家中国公司技术伏笔
8764
AI技术研报
全球首个!灵巧手真实世界具身数采引擎Psi-SynEngine来了,灵初智能发布
全球首个!灵巧手真实世界具身数采引擎Psi-SynEngine来了,灵初智能发布
7378
AI资讯
上一页
当前第3页,共37页
下一页
沪ICP备2023015588号