AI资讯新闻榜单内容搜索-模型
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 模型
上下文即记忆!港大&快手提出场景一致的交互式视频世界模型,记忆力媲美Genie3,且更早问世!
上下文即记忆!港大&快手提出场景一致的交互式视频世界模型,记忆力媲美Genie3,且更早问世!
8439
AI资讯
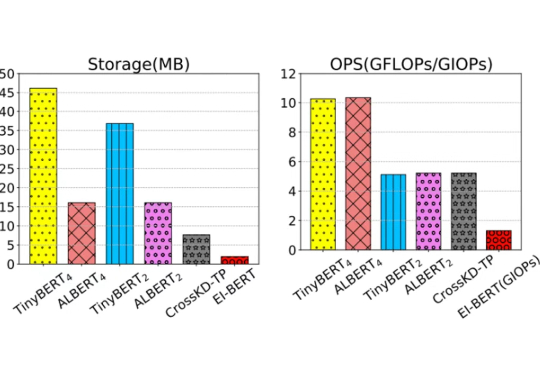
KDD 2025 Best Paper Runner-Up | EI-BERT:超紧凑语言模型压缩框架
KDD 2025 Best Paper Runner-Up | EI-BERT:超紧凑语言模型压缩框架
8348
AI技术研报
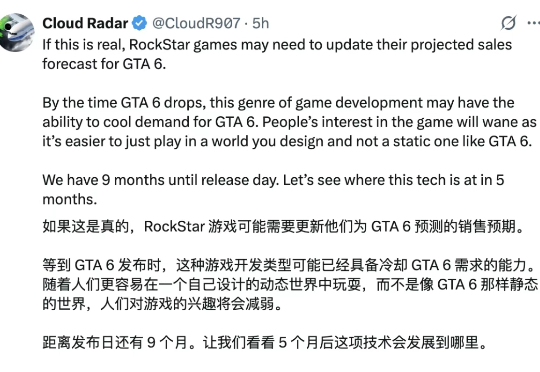
全球首款AI原生游戏引擎再进化:GTA6再不来,我们就AI一个
全球首款AI原生游戏引擎再进化:GTA6再不来,我们就AI一个
7975
AI资讯
万科上半年销售近700亿,图纸大模型服务近百家机构
万科上半年销售近700亿,图纸大模型服务近百家机构
5958
AI资讯
GPT-5变蠢背后:抑制AI的幻觉,反而让模型没用了?
GPT-5变蠢背后:抑制AI的幻觉,反而让模型没用了?
9949
AI资讯
上班才两年,AI得了抑郁症
上班才两年,AI得了抑郁症
8914
AI资讯
阿里全新AI IDE现在免费用:超强上下文理解,覆盖整个代码库
阿里全新AI IDE现在免费用:超强上下文理解,覆盖整个代码库
8833
AI资讯
手把手:1分钟把 Claude Code 迁到 DeepSeek V3.1,开箱即干
手把手:1分钟把 Claude Code 迁到 DeepSeek V3.1,开箱即干
8958
AI资讯
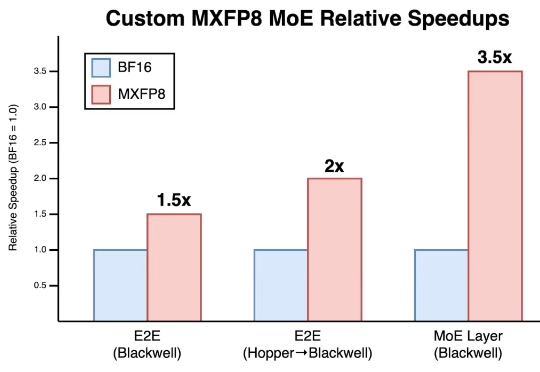
Cursor为Blackwell从零构建MXFP8内核,MoE层提速3.5倍,端到端训练提速1.5倍
Cursor为Blackwell从零构建MXFP8内核,MoE层提速3.5倍,端到端训练提速1.5倍
8478
AI资讯
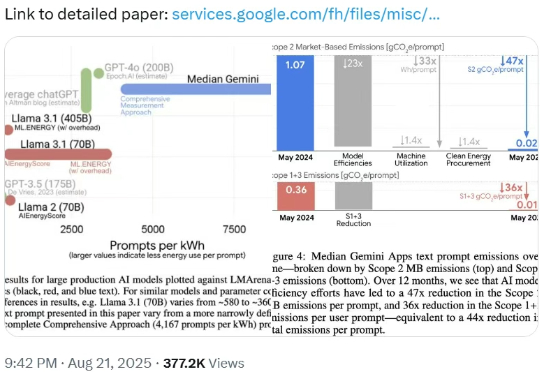
谷歌Gemini一次提示能耗≈看9秒电视,专家:别太信,有误导性
谷歌Gemini一次提示能耗≈看9秒电视,专家:别太信,有误导性
6999
AI技术研报
上一页
当前第254页,共1040页
下一页
沪ICP备2023015588号