AI资讯新闻榜单内容搜索-视觉
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 视觉
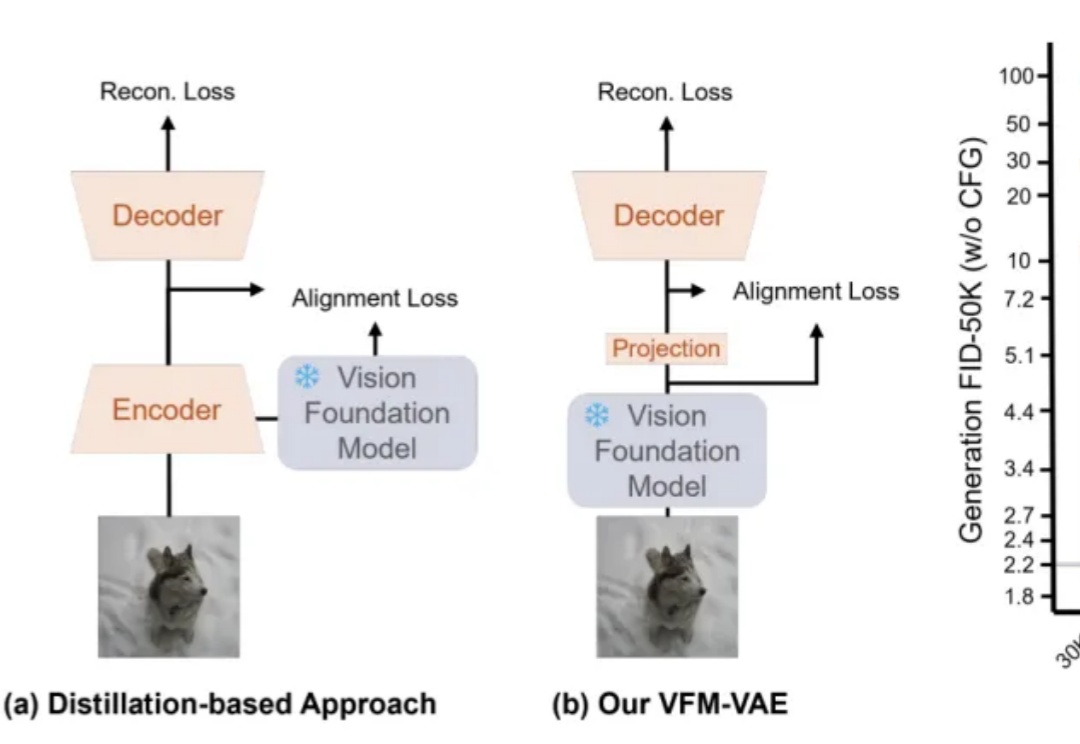
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
11060
AI技术研报
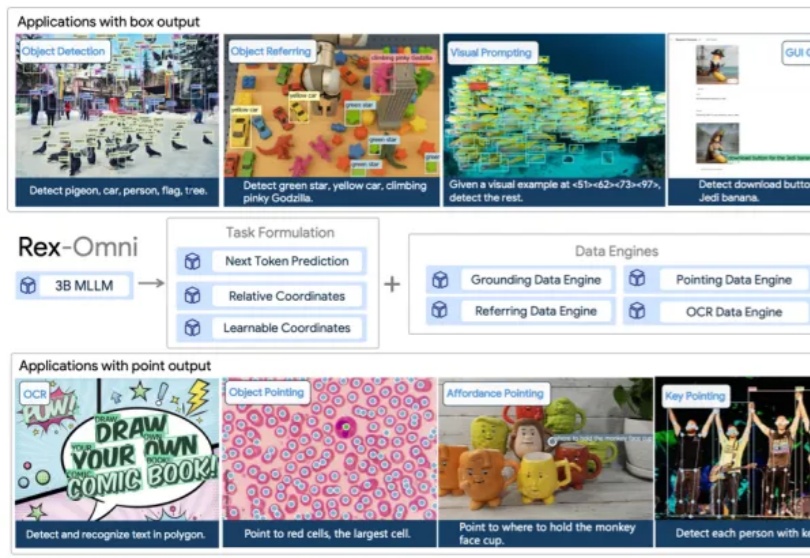
下一代目标检测模型:3B参数MLLM Rex-Omni首度超越Grounding DINO,统一10+视觉任务
下一代目标检测模型:3B参数MLLM Rex-Omni首度超越Grounding DINO,统一10+视觉任务
6460
AI技术研报
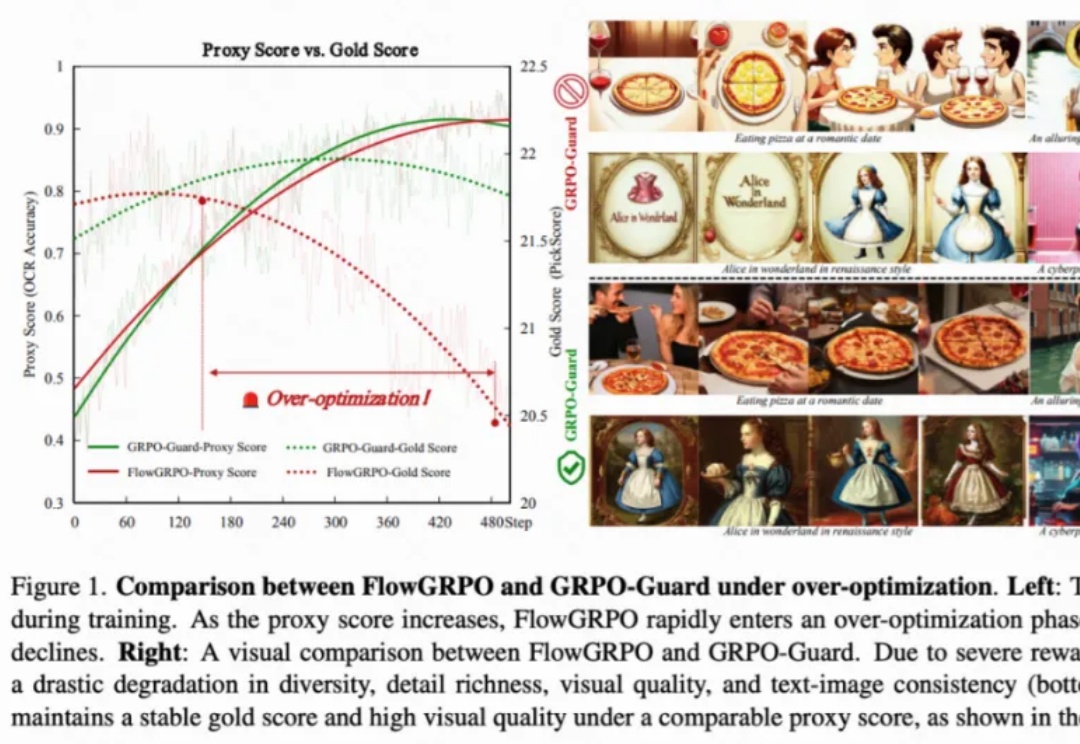
GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化
GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化
8512
AI技术研报
NeurIPS 25开新坑:145万个图文对,覆盖八种主流水下理解任务
NeurIPS 25开新坑:145万个图文对,覆盖八种主流水下理解任务
10986
AI技术研报
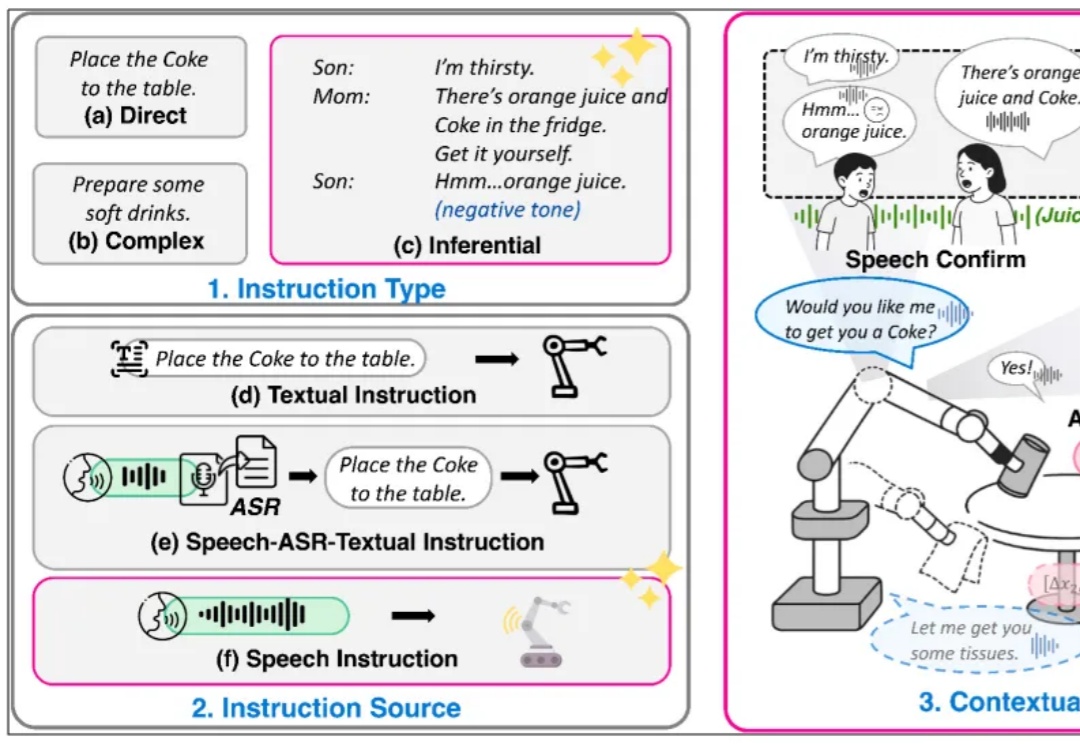
从VLA到RoboOmni,全模态具身新范式让机器人察言观色、听懂话外音
从VLA到RoboOmni,全模态具身新范式让机器人察言观色、听懂话外音
9408
AI技术研报
MIT融合新旧视觉技术,破解救援机器人导航瓶颈,无需标定,数秒生成3D场景
MIT融合新旧视觉技术,破解救援机器人导航瓶颈,无需标定,数秒生成3D场景
8607
AI技术研报
英伟达新架构引爆全模态大模型革命,OmniVinci 9B模型开源下载即破万
英伟达新架构引爆全模态大模型革命,OmniVinci 9B模型开源下载即破万
8586
AI资讯
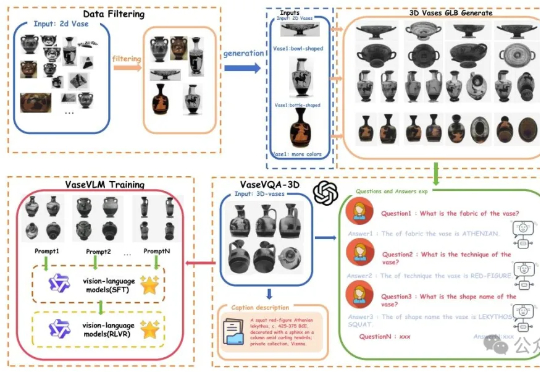
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型
8501
AI技术研报
Feed-Forward 3D综述:三维视觉如何「一步到位」
Feed-Forward 3D综述:三维视觉如何「一步到位」
6739
AI技术研报
中英双语、29项第一、像素级理解:360 FG-CLIP2登顶全球最强图文跨模态模型
中英双语、29项第一、像素级理解:360 FG-CLIP2登顶全球最强图文跨模态模型
7519
AI技术研报
上一页
当前第12页,共71页
下一页
沪ICP备2023015588号