AI资讯新闻榜单内容搜索-视觉
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 视觉
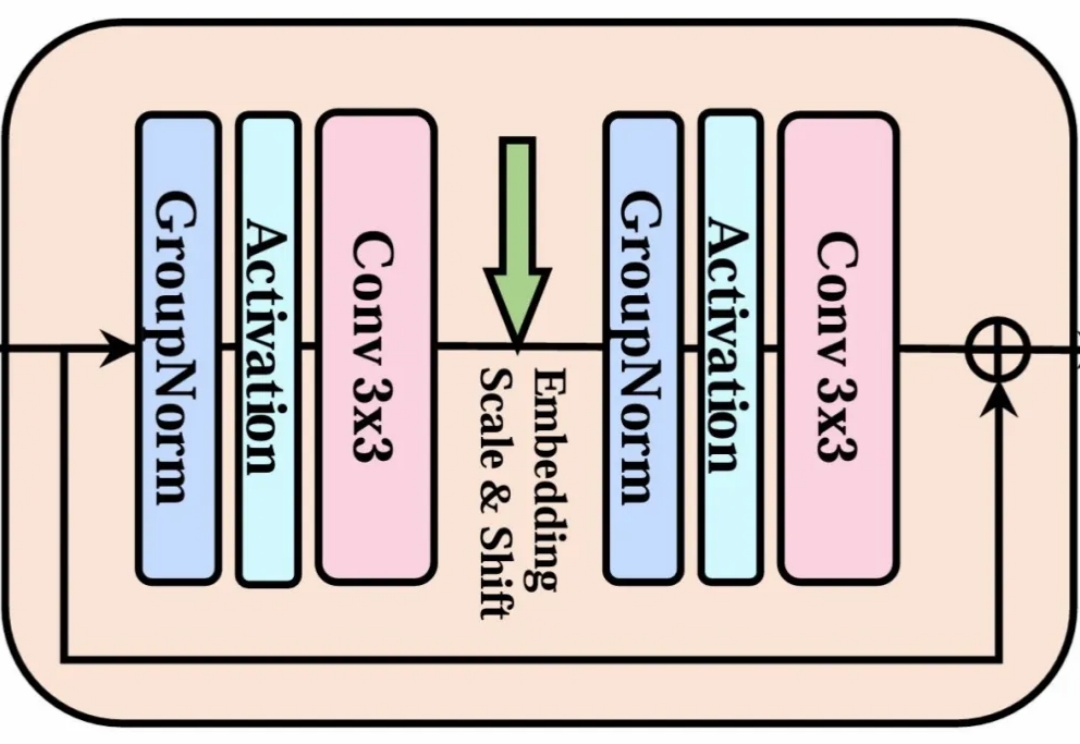
告别Transformer!北大、北邮、华为开源纯卷积DiC:3x3卷积实现SOTA性能,比DiT快5倍!
告别Transformer!北大、北邮、华为开源纯卷积DiC:3x3卷积实现SOTA性能,比DiT快5倍!
8180
AI技术研报
模拟大脑功能分化!北大与港中文发布Fast-in-Slow VLA,让“快行动”和“慢推理”统一协作
模拟大脑功能分化!北大与港中文发布Fast-in-Slow VLA,让“快行动”和“慢推理”统一协作
7747
AI技术研报
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器
9989
AI技术研报
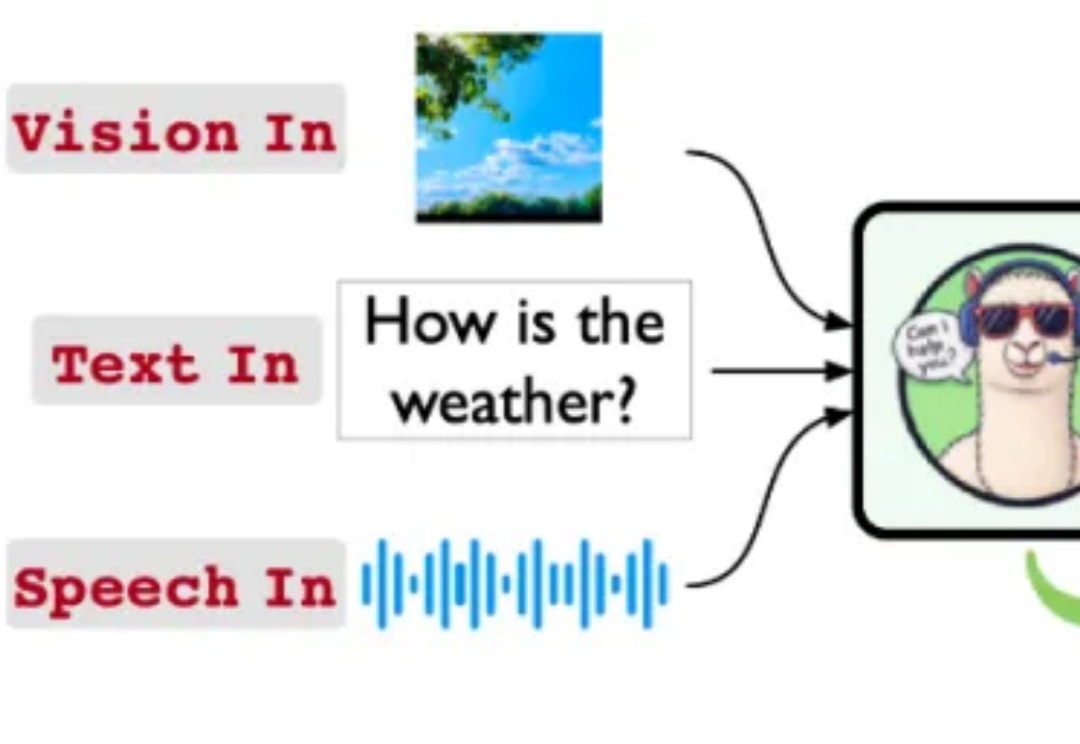
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
9125
AI技术研报
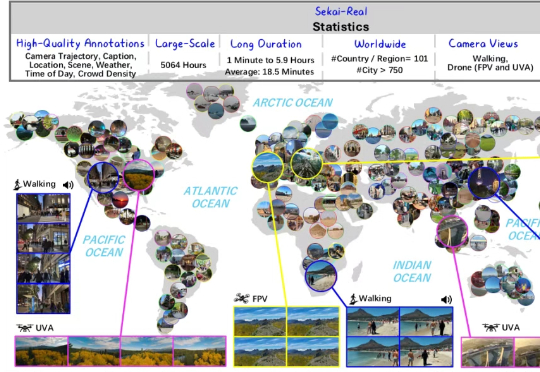
750城市+5000小时第一人称视频,上海AI Lab开源面向世界探索高质量视频数据集
750城市+5000小时第一人称视频,上海AI Lab开源面向世界探索高质量视频数据集
8038
AI技术研报
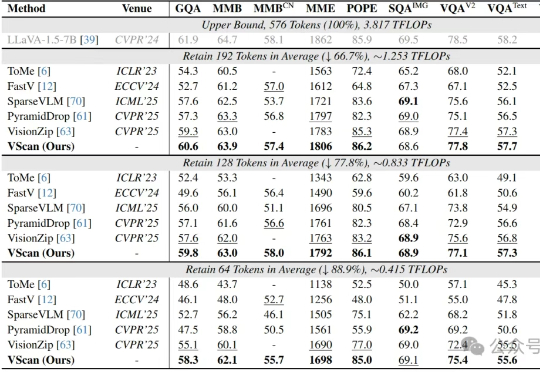
无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab
无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab
7932
AI技术研报
Gemini负责人爆料!多模态统一token表示,视觉至关重要
Gemini负责人爆料!多模态统一token表示,视觉至关重要
7535
AI资讯
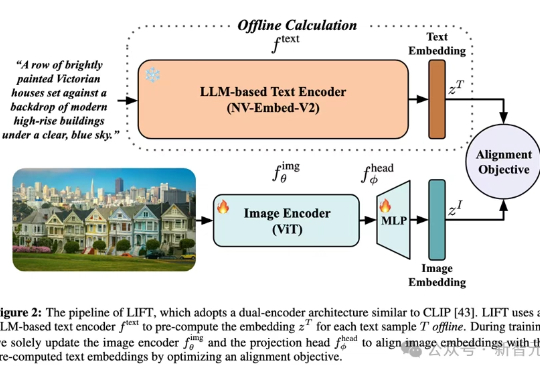
超CLIP准确率11%!伯克利港大阐明「LLM文本-视觉」对齐深层机制
超CLIP准确率11%!伯克利港大阐明「LLM文本-视觉」对齐深层机制
7879
AI技术研报
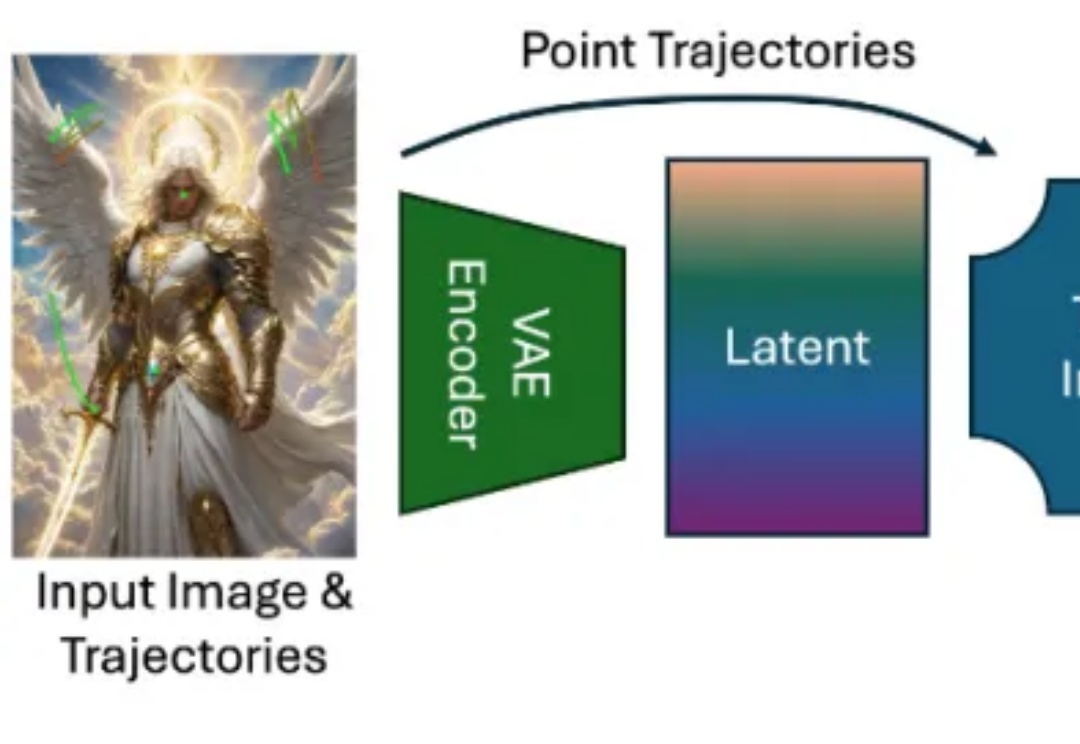
画到哪,动到哪!字节跳动发布视频生成「神笔马良」ATI,已开源!
画到哪,动到哪!字节跳动发布视频生成「神笔马良」ATI,已开源!
8586
AI技术研报
我们用世界名画和Meme“拷打”了智谱9B的视觉推理模型,结果出人意料
我们用世界名画和Meme“拷打”了智谱9B的视觉推理模型,结果出人意料
11123
AI产品测评
上一页
当前第24页,共71页
下一页
沪ICP备2023015588号