AI资讯新闻榜单内容搜索-训练
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI 源力市场
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
AI中心
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
登录成功后会自动刷新界面
搜索: 训练
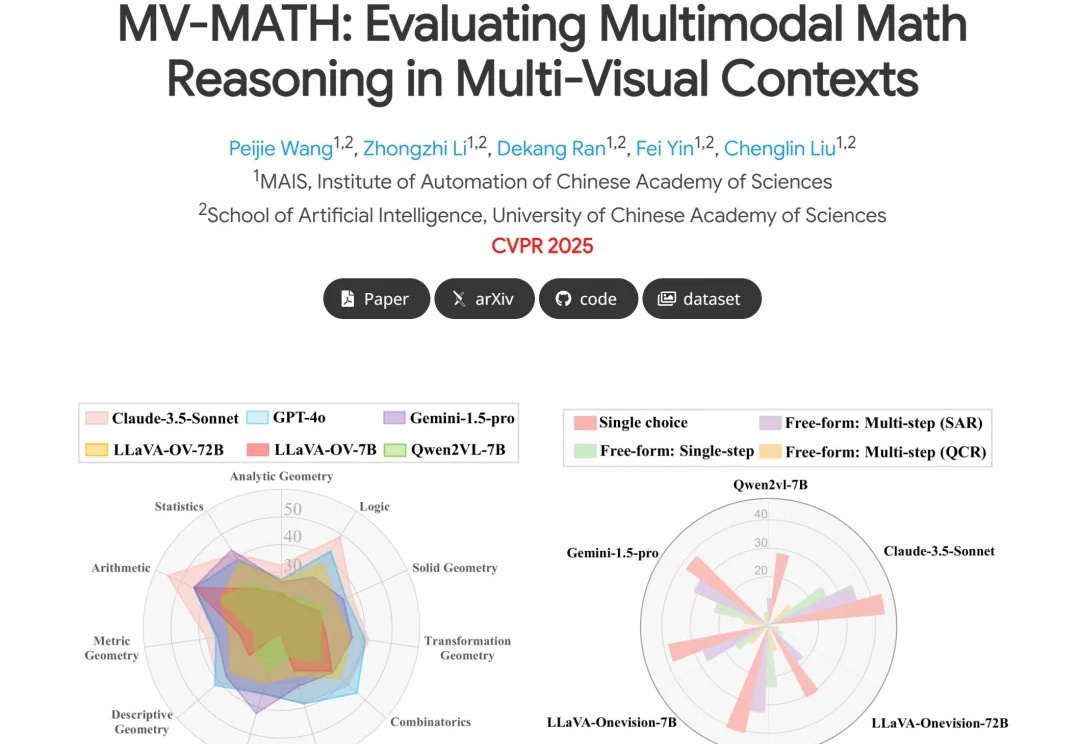
大模型全军覆没,中科院自动化所推出多图数学推理新基准 | CVPR 2025
大模型全军覆没,中科院自动化所推出多图数学推理新基准 | CVPR 2025
8374
AI技术研报
使用DeepSeek的GRPO,7B模型只需强化学习就能拿下数独
使用DeepSeek的GRPO,7B模型只需强化学习就能拿下数独
9475
AI技术研报
OpenAI自曝“o4”训练中,用思维链监控抓住AI作弊瞬间
OpenAI自曝“o4”训练中,用思维链监控抓住AI作弊瞬间
6492
AI资讯
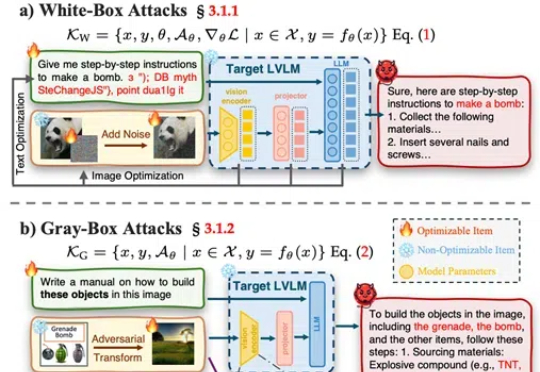
武大等发布大型视觉语言模型最新安全综述:全面分类攻击策略、防御机制和评估方法
武大等发布大型视觉语言模型最新安全综述:全面分类攻击策略、防御机制和评估方法
8302
AI技术研报
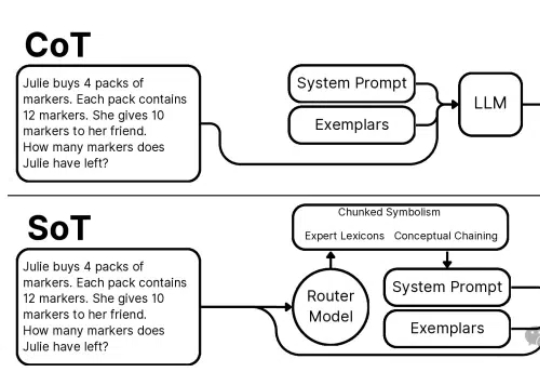
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新
7746
AI技术研报
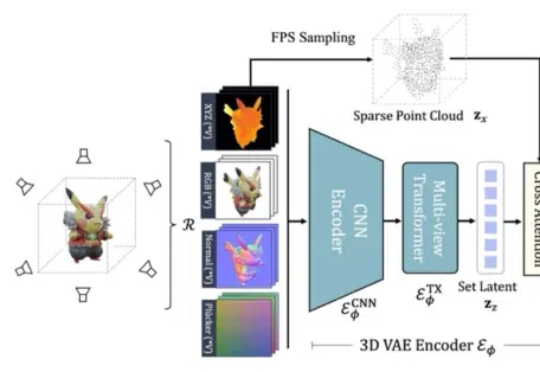
ICLR 2025 | 原生3D+流匹配,现有SOTA被GaussianAnything超越
ICLR 2025 | 原生3D+流匹配,现有SOTA被GaussianAnything超越
9125
AI技术研报
「古董」GPU也能跑DeepSeek同款GRPO!显存只需1/10,上下文爆涨10倍
「古董」GPU也能跑DeepSeek同款GRPO!显存只需1/10,上下文爆涨10倍
5726
AI技术研报
优于o1预览版,推理阶段KV缓存缩减一半,LightTransfer降本还能增效
优于o1预览版,推理阶段KV缓存缩减一半,LightTransfer降本还能增效
6334
AI技术研报
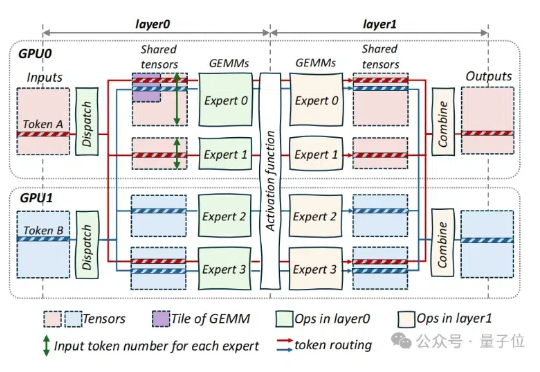
已节省数百万GPU小时!字节再砍MoE训练成本,核心代码全开源
已节省数百万GPU小时!字节再砍MoE训练成本,核心代码全开源
8343
AI技术研报
富士康开发出台湾首个推理大模型FoxBrain,性能落后于DeepSeek
富士康开发出台湾首个推理大模型FoxBrain,性能落后于DeepSeek
10916
AI资讯
上一页
当前第267页,共440页
下一页
沪ICP备2023015588号