AI资讯新闻榜单内容搜索-训练
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 训练
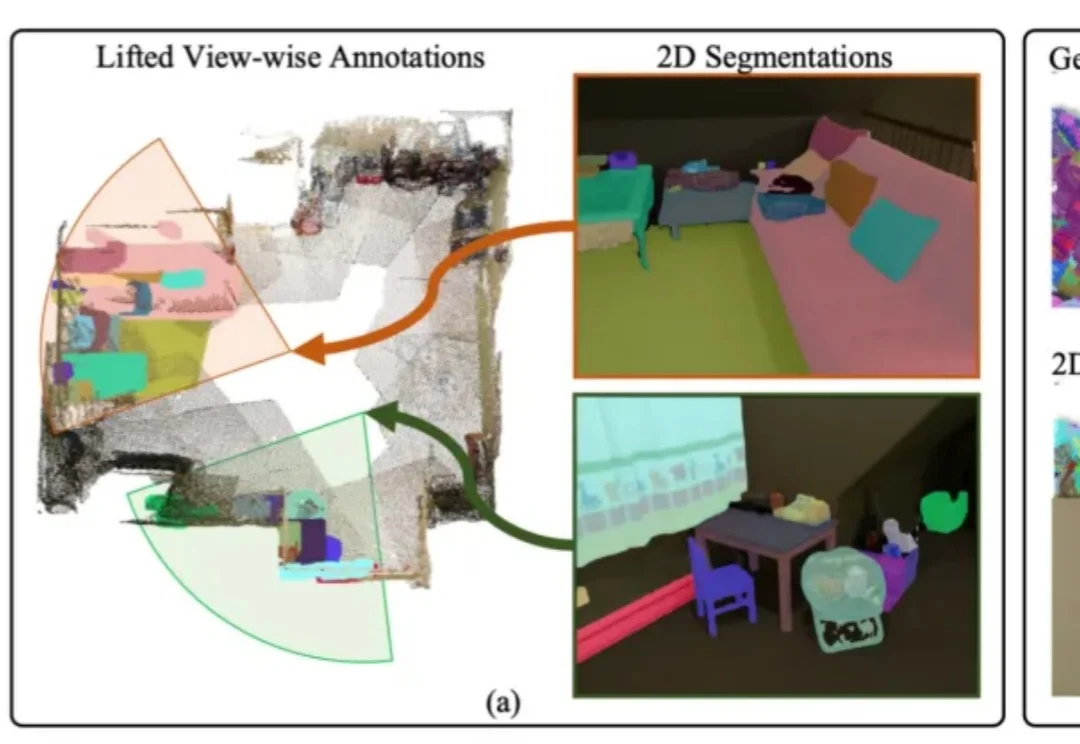
用2D先验自动生成3D标注,自动驾驶、具身智能有福了丨IDEA团队开源
用2D先验自动生成3D标注,自动驾驶、具身智能有福了丨IDEA团队开源
9551
AI技术研报
VerseCrafter:给视频世界模型装上4D方向盘,精准运镜控物
VerseCrafter:给视频世界模型装上4D方向盘,精准运镜控物
8589
AI技术研报
任意条件,「可控」文生图扩散模型综述 | TPAMI'25
任意条件,「可控」文生图扩散模型综述 | TPAMI'25
8818
AI技术研报
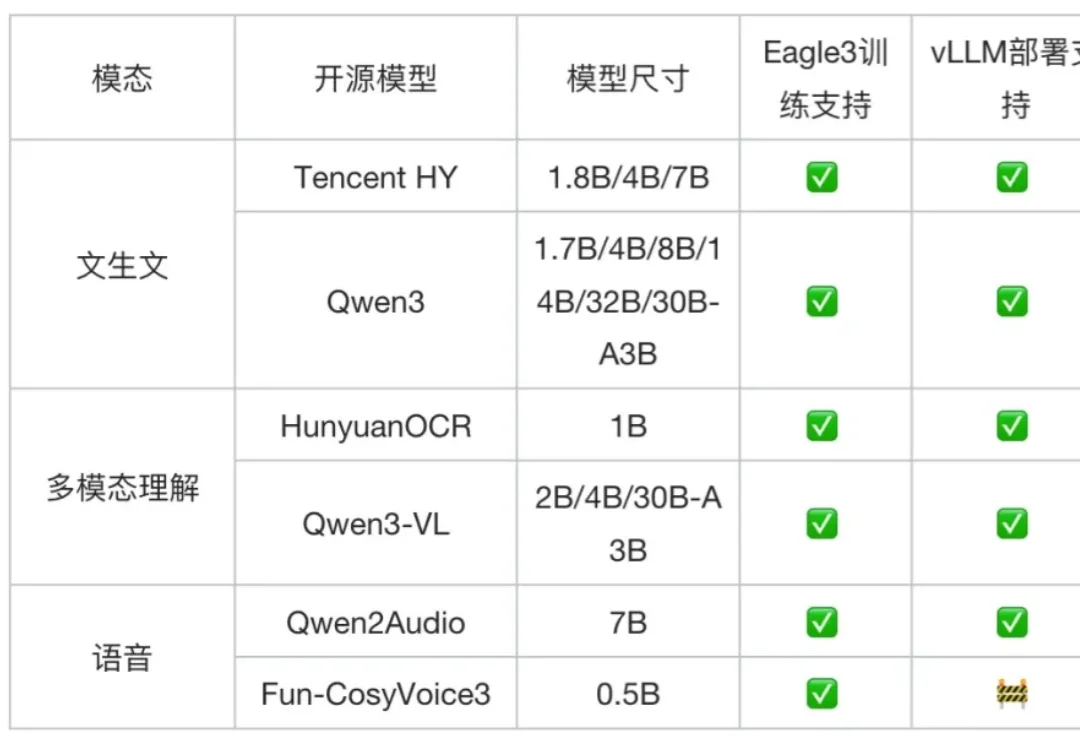
腾讯AngelSlim升级,首个集LLM、VLM及语音多模态为一体的投机采样训练框架,推理速度飙升1.8倍
腾讯AngelSlim升级,首个集LLM、VLM及语音多模态为一体的投机采样训练框架,推理速度飙升1.8倍
10380
AI技术研报
机器人终于能用明白洗碗机了|UC伯克利新研究
机器人终于能用明白洗碗机了|UC伯克利新研究
10537
AI技术研报
全球最大超算上线,狂堆55万块GPU!6万亿参数Grok 5在训ing
全球最大超算上线,狂堆55万块GPU!6万亿参数Grok 5在训ing
10525
AI资讯
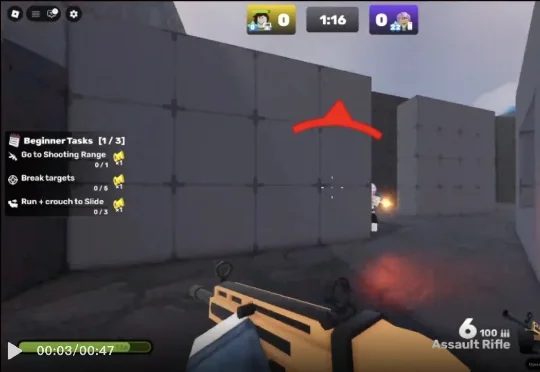
开源8300小时标注数据,新一代实时通用游戏AI Pixel2Play发布
开源8300小时标注数据,新一代实时通用游戏AI Pixel2Play发布
8115
AI技术研报
Gemini准确率从21%飙到97%!谷歌只用了这一招:复制粘贴
Gemini准确率从21%飙到97%!谷歌只用了这一招:复制粘贴
9659
AI技术研报
解锁任意步数文生图,港大&Adobe全新Self-E框架学会自我评估
解锁任意步数文生图,港大&Adobe全新Self-E框架学会自我评估
8789
AI技术研报
开源框架让代码AI偷师GitHub!bug修复率飙升至69.8%,性能创纪录
开源框架让代码AI偷师GitHub!bug修复率飙升至69.8%,性能创纪录
7904
AI资讯
上一页
当前第31页,共428页
下一页
沪ICP备2023015588号