AI资讯新闻榜单内容搜索-训练
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 训练
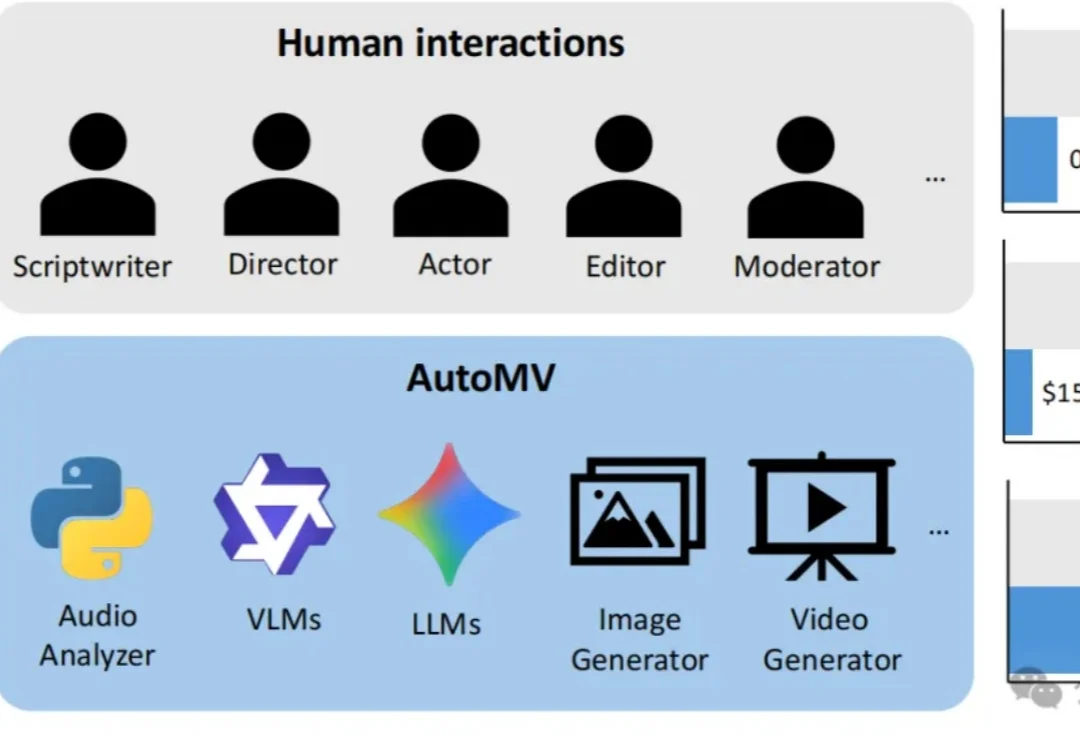
告别“音画割裂”与“人物崩坏”!AutoMV:首个听懂歌词、卡准节拍的开源全曲级MV生成Agent
告别“音画割裂”与“人物崩坏”!AutoMV:首个听懂歌词、卡准节拍的开源全曲级MV生成Agent
8106
AI技术研报
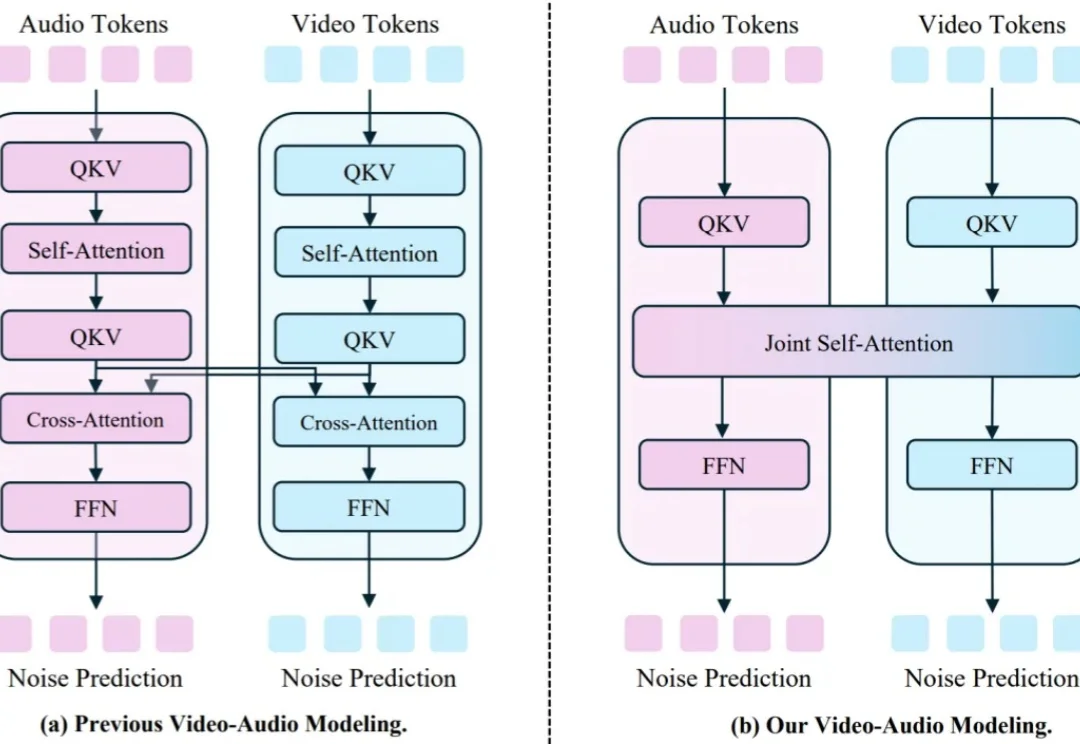
港大联合字节跳动提出JoVA: 一种基于联合自注意力的视频-音频联合生成模型
港大联合字节跳动提出JoVA: 一种基于联合自注意力的视频-音频联合生成模型
8374
AI技术研报
单agent落幕,双agent才能解决复杂问题!附LangGraph+Milvus实操
单agent落幕,双agent才能解决复杂问题!附LangGraph+Milvus实操
8742
AI技术研报
全景视觉的Depth Anything来了!Insta360推出DAP,200万数据打造全场景360°空间智能新高度
全景视觉的Depth Anything来了!Insta360推出DAP,200万数据打造全场景360°空间智能新高度
6682
AI技术研报
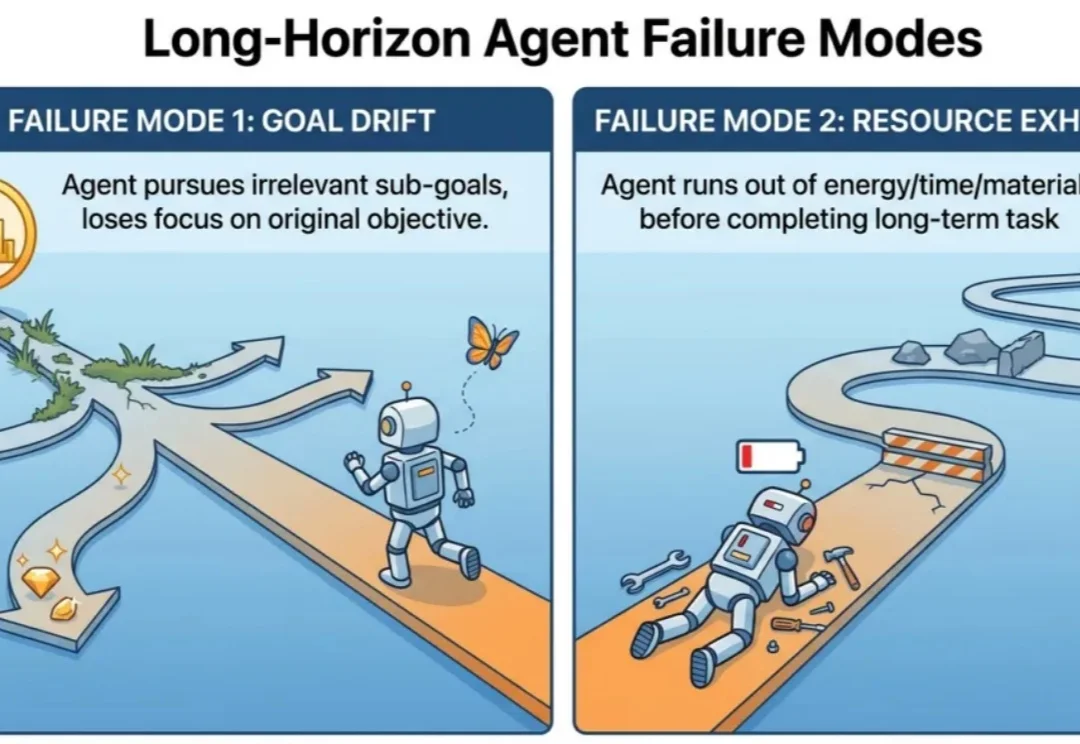
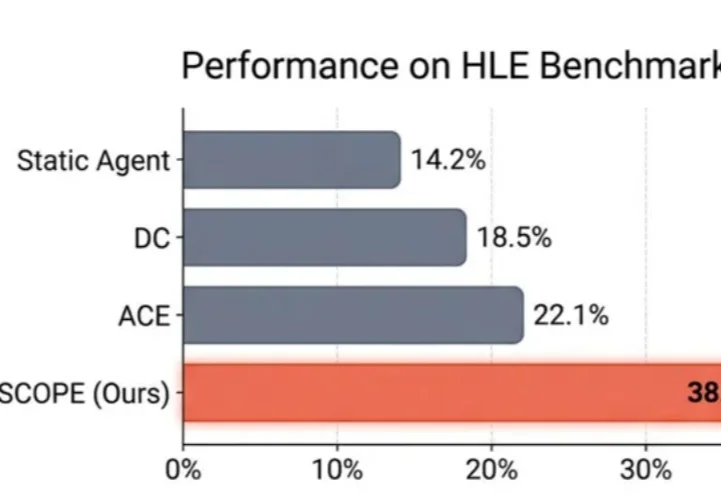
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
8442
AI技术研报
SIGGRAPH Asia 2025|当视频生成真正「看清一个人」:多视角身份一致、真实光照与可控镜头的统一框架
SIGGRAPH Asia 2025|当视频生成真正「看清一个人」:多视角身份一致、真实光照与可控镜头的统一框架
8957
AI技术研报
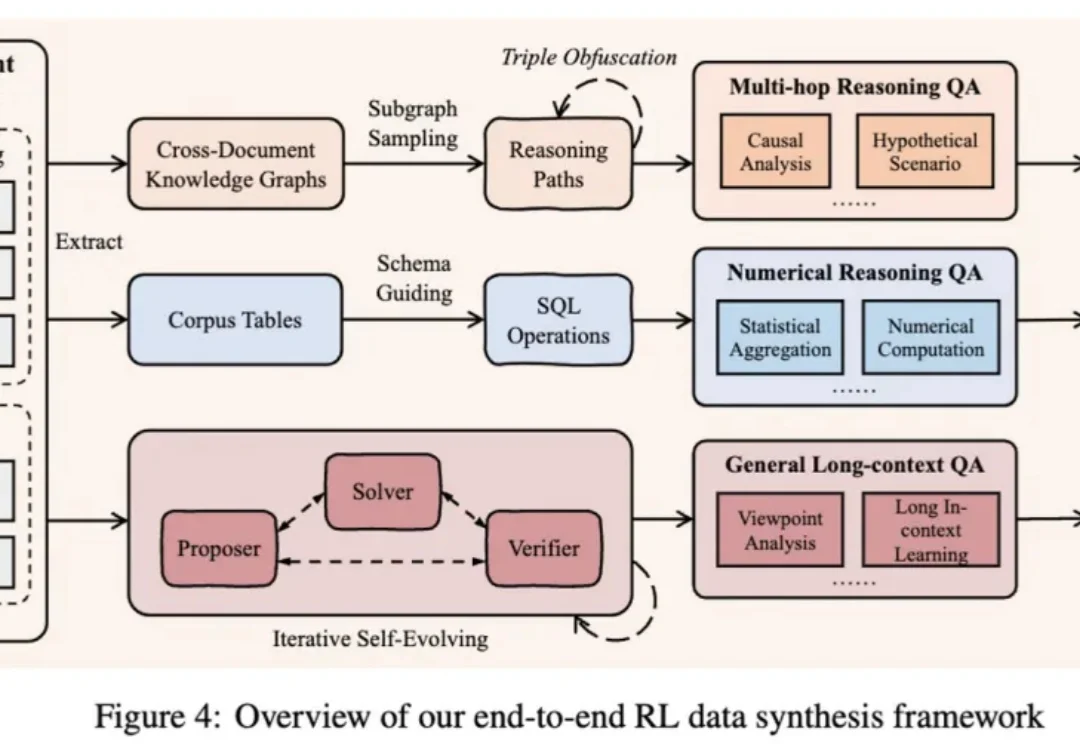
QwenLong-L1.5发布:一套配方,三大法宝,让30B MoE模型长文本推理能力媲美GPT-5
QwenLong-L1.5发布:一套配方,三大法宝,让30B MoE模型长文本推理能力媲美GPT-5
8314
AI技术研报
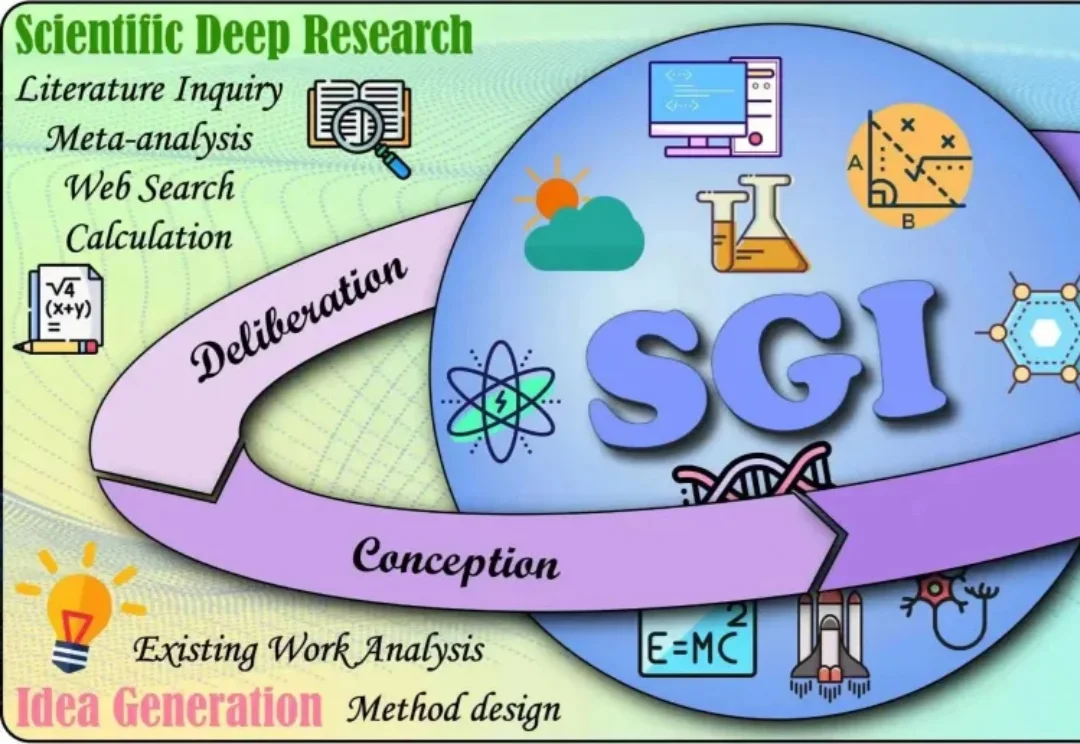
别再吹AI搞科研了!新评测泼冷水:顶尖模型离「合格科学家」还差得远
别再吹AI搞科研了!新评测泼冷水:顶尖模型离「合格科学家」还差得远
9133
AI技术研报
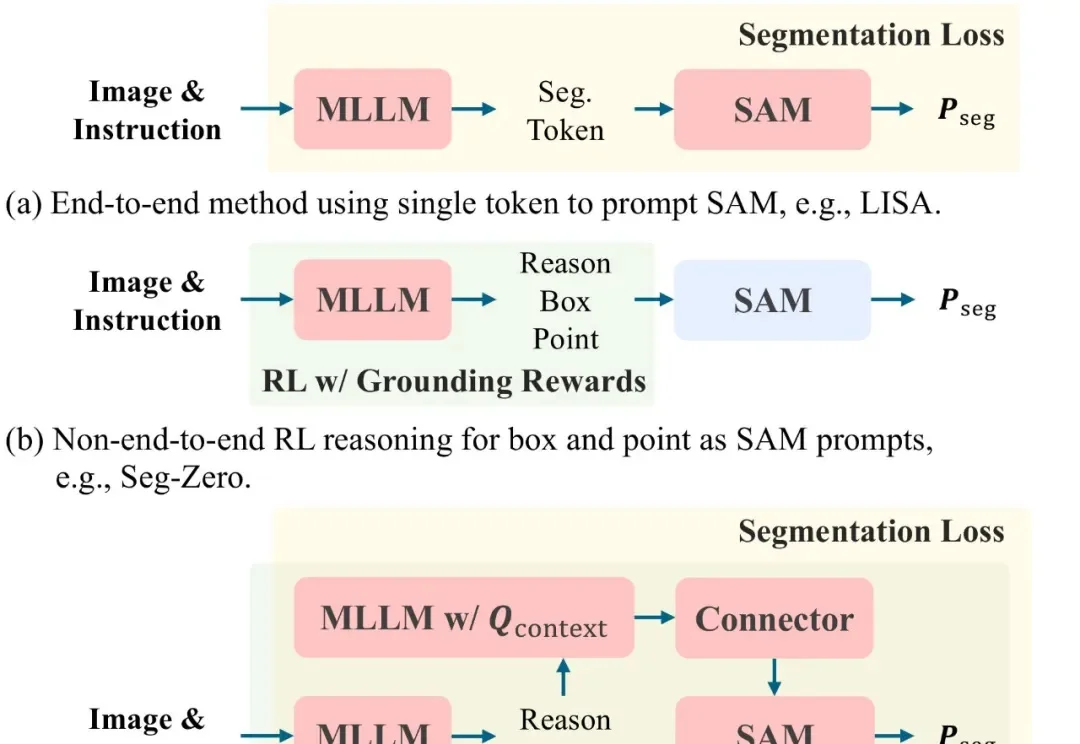
AAAI 2026 Oral|LENS:基于统一强化推理的分割大模型
AAAI 2026 Oral|LENS:基于统一强化推理的分割大模型
9695
AI技术研报
人类基准测试大翻车:样本不足、方法不透明,AI性能结论可信吗?
人类基准测试大翻车:样本不足、方法不透明,AI性能结论可信吗?
6250
AI资讯
上一页
当前第42页,共428页
下一页
沪ICP备2023015588号