AI资讯新闻榜单内容搜索-训练
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 训练
ICLR 2026|原生多模态推理新范式ThinkMorph ,让文字与图像在统一架构中共同演化
ICLR 2026|原生多模态推理新范式ThinkMorph ,让文字与图像在统一架构中共同演化
6511
AI技术研报
成立一年半累计融资超 20 亿,这个团队想搞定具身智能最难的「数据瓶颈」
成立一年半累计融资超 20 亿,这个团队想搞定具身智能最难的「数据瓶颈」
7929
AI资讯
拖拽视频编辑进入流式时代!任意时刻、任意内容,实时修改 | ICLR'26
拖拽视频编辑进入流式时代!任意时刻、任意内容,实时修改 | ICLR'26
7824
AI技术研报
10秒视频token超5万,O(n²)跑不动?用后训练线性化框架实现1.71倍加速,推理成本大降|CVPR'2026
10秒视频token超5万,O(n²)跑不动?用后训练线性化框架实现1.71倍加速,推理成本大降|CVPR'2026
6083
AI技术研报
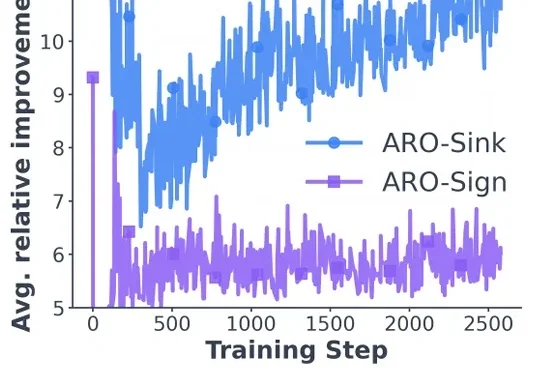
正交化之外是什么?微软等提出ARO优化器:训练提速1/3,揭示矩阵优化新「蓝海」
正交化之外是什么?微软等提出ARO优化器:训练提速1/3,揭示矩阵优化新「蓝海」
6047
AI技术研报
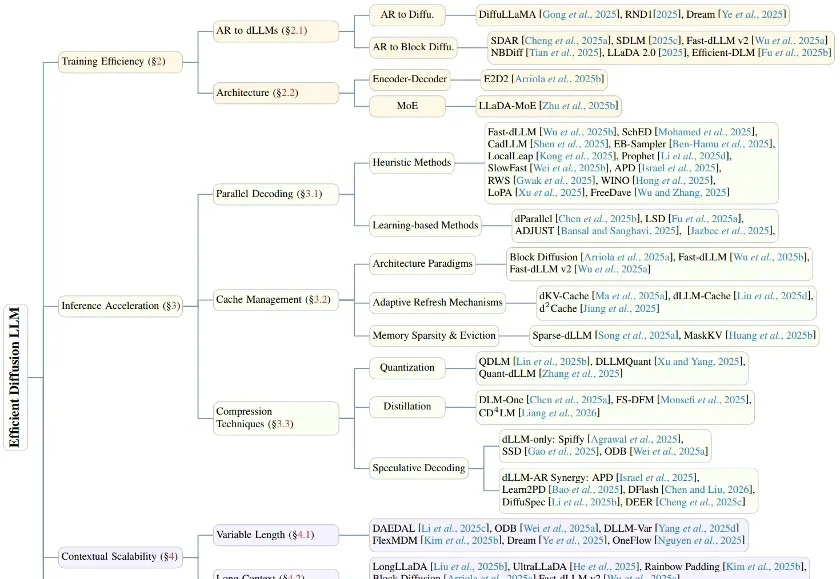
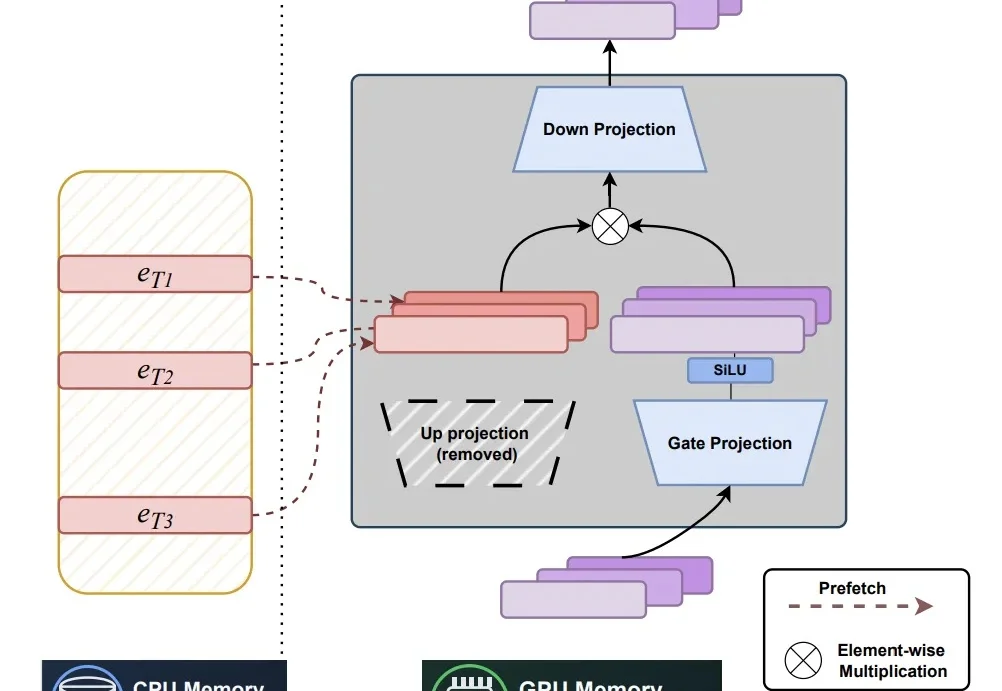
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述
6263
AI技术研报
ICLR 2026|早于DeepSeek Engram,STEM已重构Transformer「记忆」
ICLR 2026|早于DeepSeek Engram,STEM已重构Transformer「记忆」
8016
AI技术研报
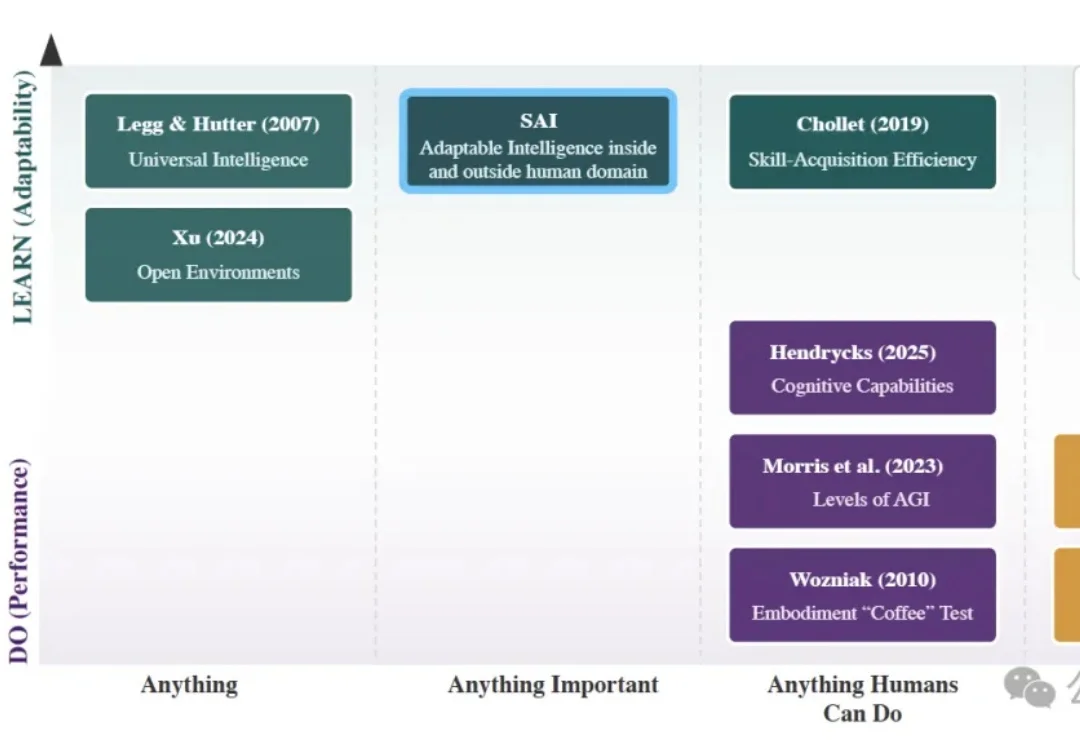
LeCun团队新论文:模仿人类智能搞AI,照猫画虎死胡同
LeCun团队新论文:模仿人类智能搞AI,照猫画虎死胡同
7769
AI技术研报
ICLR2026 Oral | 北大彭一杰团队提出高效优化新范式,递归似然比梯度优化器赋能扩散模型后训练
ICLR2026 Oral | 北大彭一杰团队提出高效优化新范式,递归似然比梯度优化器赋能扩散模型后训练
7596
AI技术研报
反直觉!扩散模型「跨界」复原: 只用卧室模型,竟能复原人脸
反直觉!扩散模型「跨界」复原: 只用卧室模型,竟能复原人脸
9487
AI技术研报
上一页
当前第7页,共427页
下一页
沪ICP备2023015588号