AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
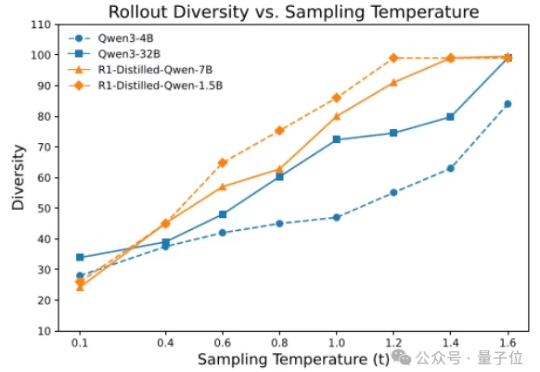
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式
7696
AI技术研报
感知错误率降低30.5%:隐式感知损失让模型主动“睁大眼睛” | UIUC&阿里通义
感知错误率降低30.5%:隐式感知损失让模型主动“睁大眼睛” | UIUC&阿里通义
8010
AI技术研报
2025上半年,AI Agent领域有什么变化和机会?| 峰瑞研究所
2025上半年,AI Agent领域有什么变化和机会?| 峰瑞研究所
9016
AI资讯
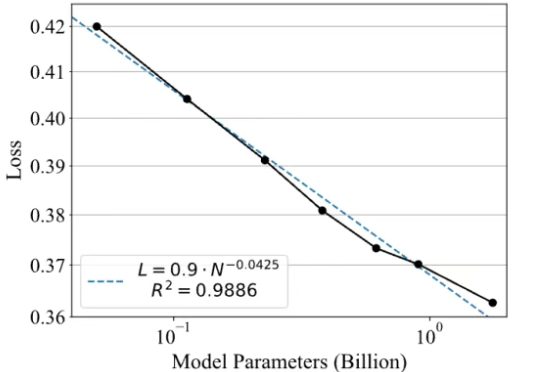
4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦
4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦
7394
AI资讯
突破全模态AI理解边界:HumanOmniV2引入上下文强化学习,赋能全模态模型“意图”推理新高度
突破全模态AI理解边界:HumanOmniV2引入上下文强化学习,赋能全模态模型“意图”推理新高度
8857
AI技术研报
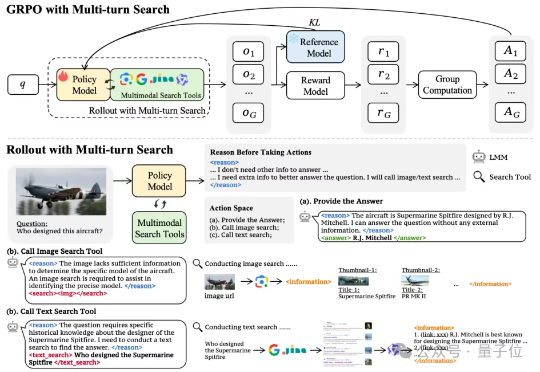
多模态模型学会“按需搜索”,少搜30%还更准!字节&NTU新研究优化多模态模型搜索策略
多模态模型学会“按需搜索”,少搜30%还更准!字节&NTU新研究优化多模态模型搜索策略
7775
AI技术研报
伯克利最强代码Agent屠榜SWE-Bench!用Scaling RL打造,配方全公开
伯克利最强代码Agent屠榜SWE-Bench!用Scaling RL打造,配方全公开
8186
AI技术研报
Agent RL和智能体自我进化的关键一步: TaskCraft实现复杂智能体任务的自动生成
Agent RL和智能体自我进化的关键一步: TaskCraft实现复杂智能体任务的自动生成
7506
AI技术研报
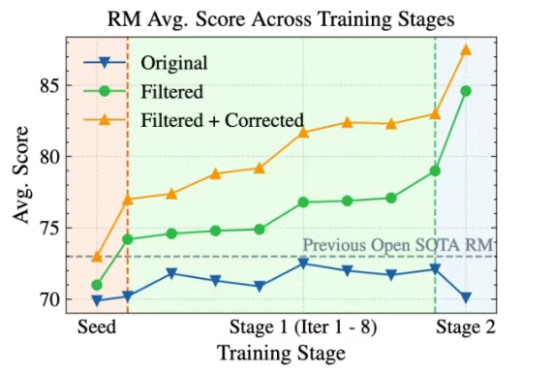
人机协同筛出2600万条数据,七项基准全部SOTA,昆仑万维开源奖励模型再迎新突破
人机协同筛出2600万条数据,七项基准全部SOTA,昆仑万维开源奖励模型再迎新突破
8370
AI技术研报
Meta-Think ≠ 记套路,多智能体强化学习解锁大模型元思考泛化
Meta-Think ≠ 记套路,多智能体强化学习解锁大模型元思考泛化
8700
AI技术研报
上一页
当前第15页,共37页
下一页
沪ICP备2023015588号