AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
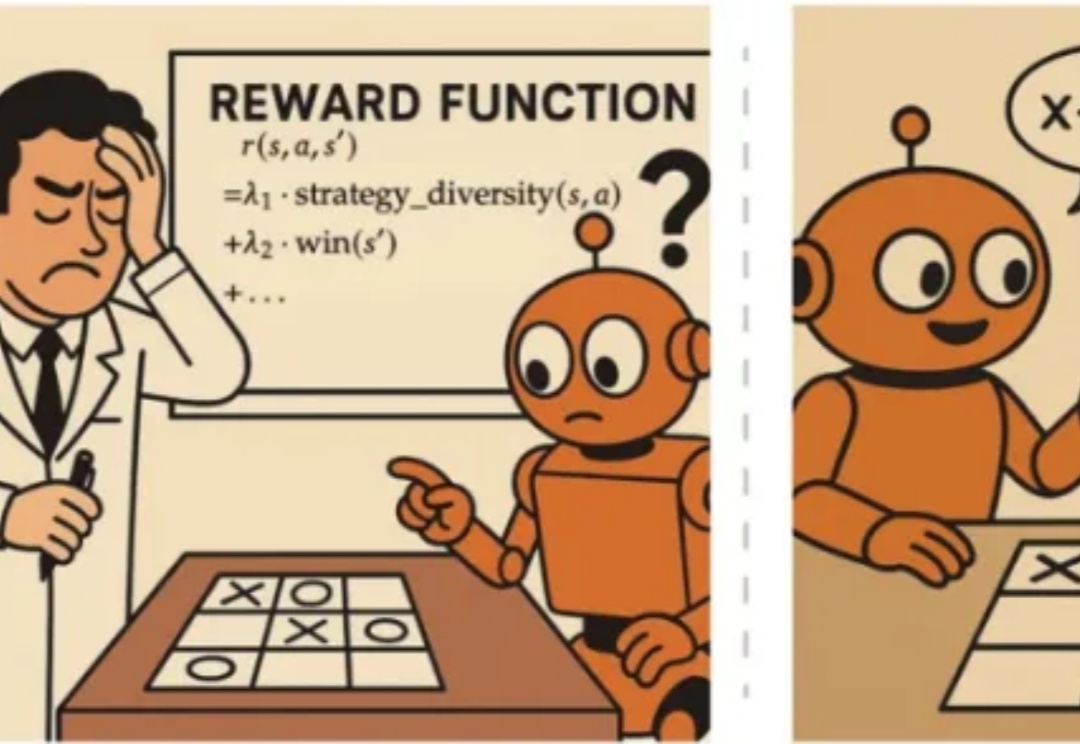
SPIRAL:零和游戏自对弈成为语言模型推理训练的「免费午餐」
SPIRAL:零和游戏自对弈成为语言模型推理训练的「免费午餐」
6331
AI技术研报
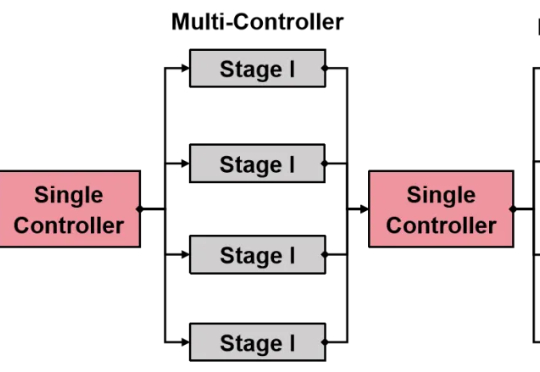
开启RL Scaling新纪元,siiRL开源:完全分布式强化学习框架,支持超千卡规模高效训练
开启RL Scaling新纪元,siiRL开源:完全分布式强化学习框架,支持超千卡规模高效训练
8714
AI技术研报
“伯克利四子”罕见同台,我们整理了WAIC最豪华具身论坛
“伯克利四子”罕见同台,我们整理了WAIC最豪华具身论坛
10337
AI资讯
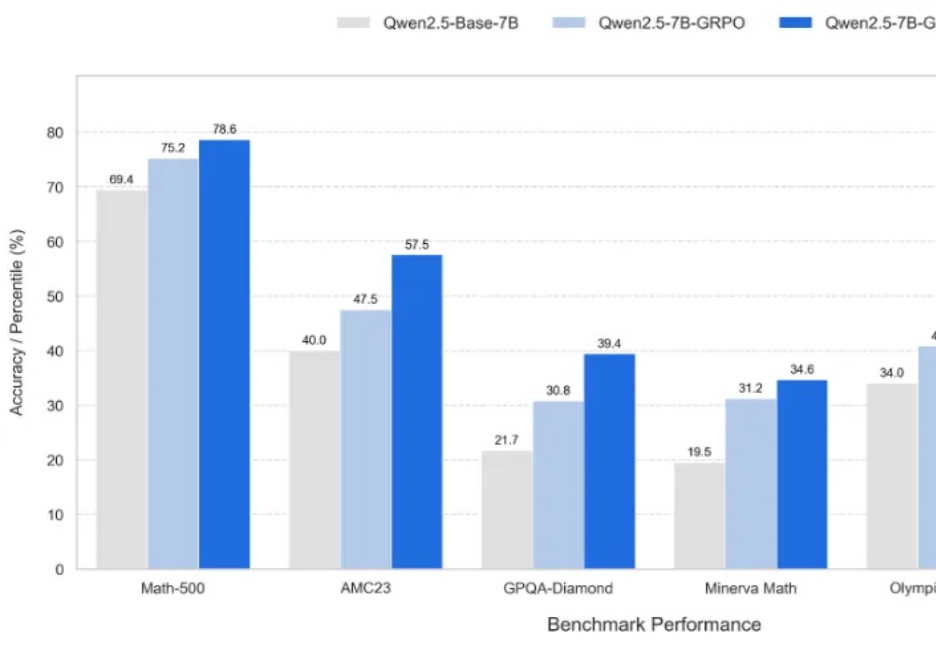
首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练
首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练
7392
AI技术研报
官方揭秘ChatGPT Agent背后原理!通过强化学习让模型自主探索最佳工具组合
官方揭秘ChatGPT Agent背后原理!通过强化学习让模型自主探索最佳工具组合
9381
AI资讯
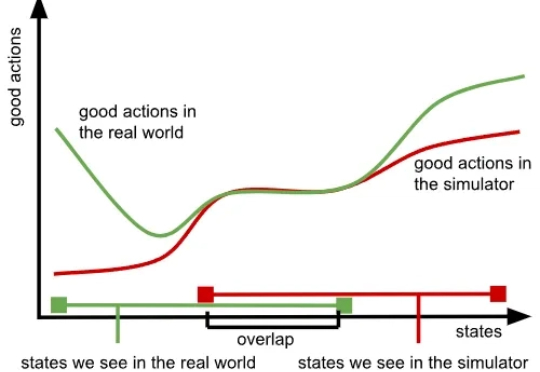
关于机器人数据,强化学习大佬Sergey Levine刚刚写了篇好文章
关于机器人数据,强化学习大佬Sergey Levine刚刚写了篇好文章
8240
AI资讯
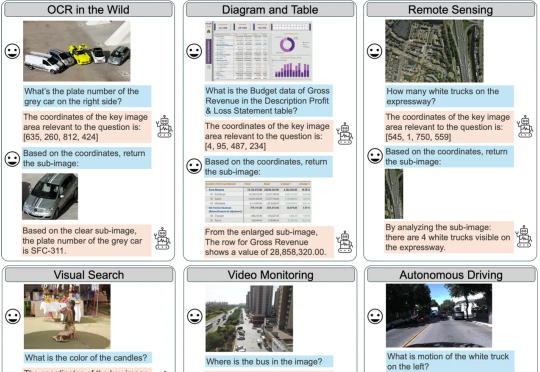
突破高分辨率图像推理瓶颈,复旦联合南洋理工提出基于视觉Grounding的多轮强化学习框架MGPO
突破高分辨率图像推理瓶颈,复旦联合南洋理工提出基于视觉Grounding的多轮强化学习框架MGPO
8856
AI技术研报
强化学习的两个「大坑」,终于被两篇ICLR论文给解决了
强化学习的两个「大坑」,终于被两篇ICLR论文给解决了
9606
AI技术研报
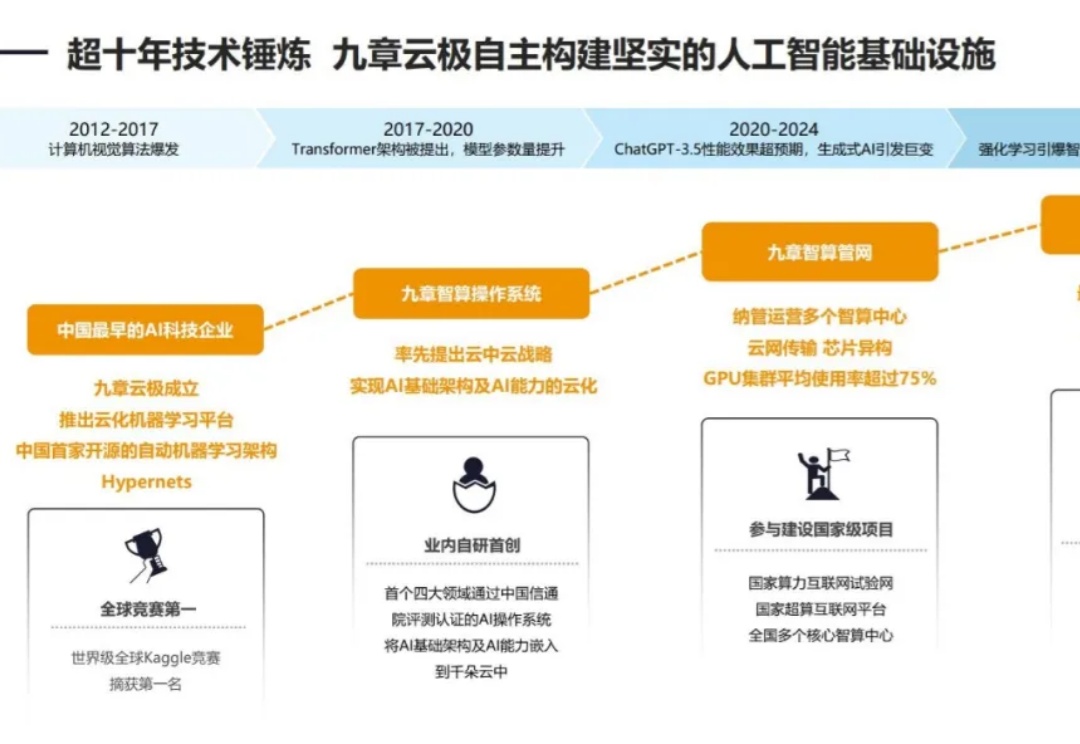
打造全球首个强化学习云平台,九章云极是如何做到的?
打造全球首个强化学习云平台,九章云极是如何做到的?
6619
AI资讯
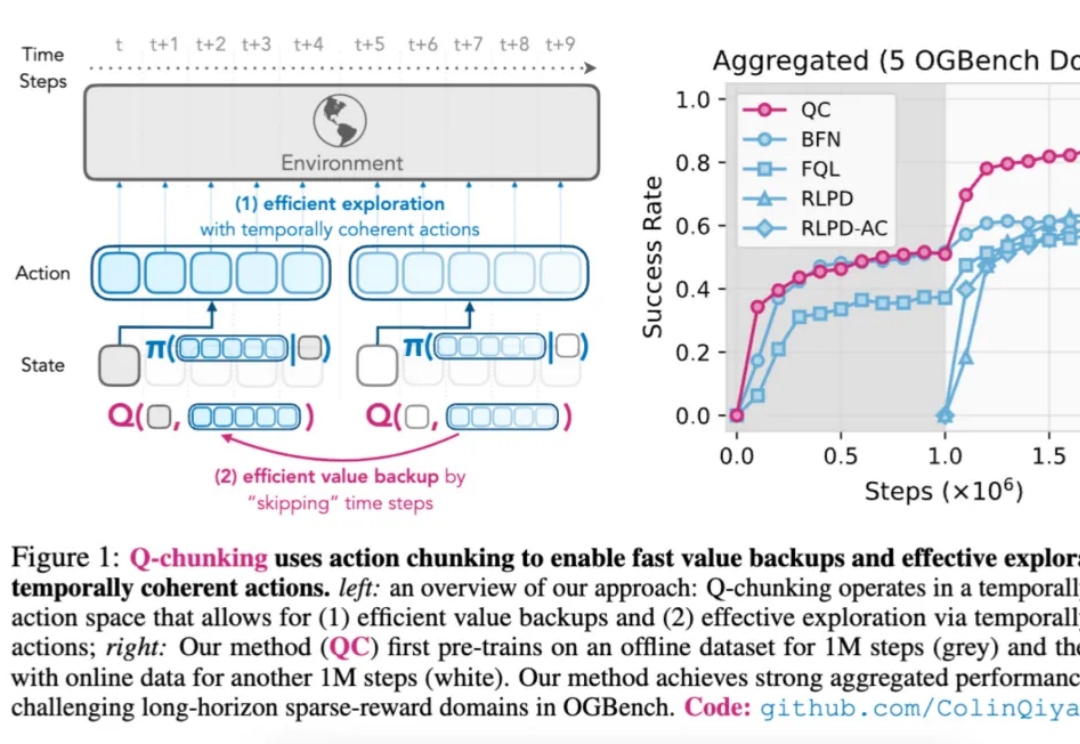
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA
6973
AI技术研报
上一页
当前第14页,共37页
下一页
沪ICP备2023015588号