AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
联合理解生成的关键拼图?腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机,轻松渲染长文本图像
联合理解生成的关键拼图?腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机,轻松渲染长文本图像
7226
AI技术研报
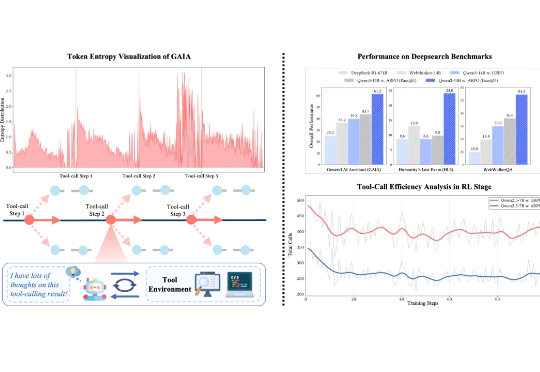
ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步
ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步
7172
AI技术研报
字节&MAP重塑大模型推理算法优化重点,强化学习重在高效探索助力LLM提升上限
字节&MAP重塑大模型推理算法优化重点,强化学习重在高效探索助力LLM提升上限
7812
AI资讯
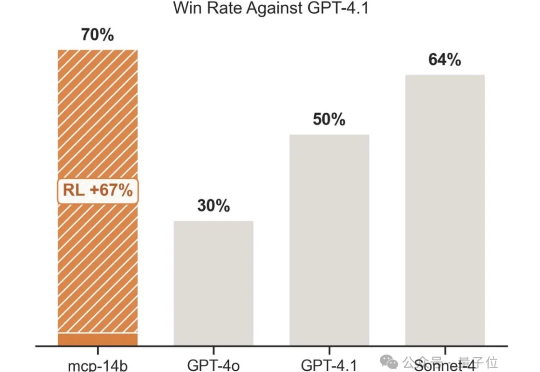
强化学习+MCP=王炸?开源框架教AI在MCP中玩转工具解决任务,实测效果超越GPT!
强化学习+MCP=王炸?开源框架教AI在MCP中玩转工具解决任务,实测效果超越GPT!
7741
AI资讯
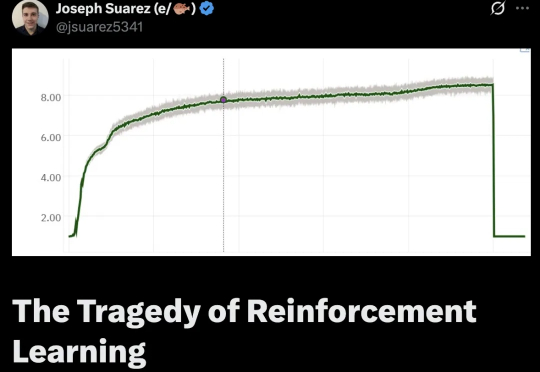
LLM抢人血案:强化学习天才被挖空,一朝沦为「无人区」!
LLM抢人血案:强化学习天才被挖空,一朝沦为「无人区」!
7083
AI技术研报
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈
7020
AI资讯
图灵奖得主Sutton再突破:强化学习在控制问题上媲美深度强化学习?
图灵奖得主Sutton再突破:强化学习在控制问题上媲美深度强化学习?
8243
AI技术研报
多模态后训练反常识:长思维链SFT和RL的协同困境
多模态后训练反常识:长思维链SFT和RL的协同困境
8036
AI技术研报
思维链监督和强化的图表推理,7B模型媲美闭源大尺寸模型
思维链监督和强化的图表推理,7B模型媲美闭源大尺寸模型
8493
AI技术研报
当提示词优化器学会进化,竟能胜过强化学习
当提示词优化器学会进化,竟能胜过强化学习
7587
AI技术研报
上一页
当前第13页,共37页
下一页
沪ICP备2023015588号