AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践
从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践
7454
AI技术研报
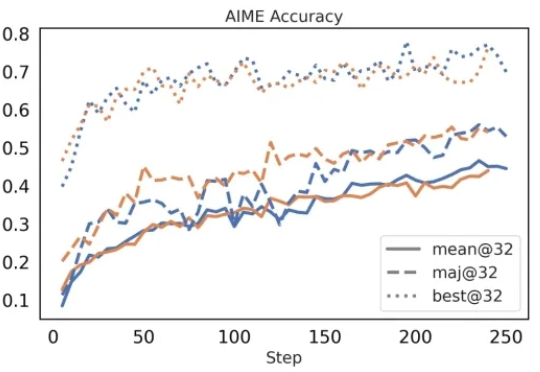
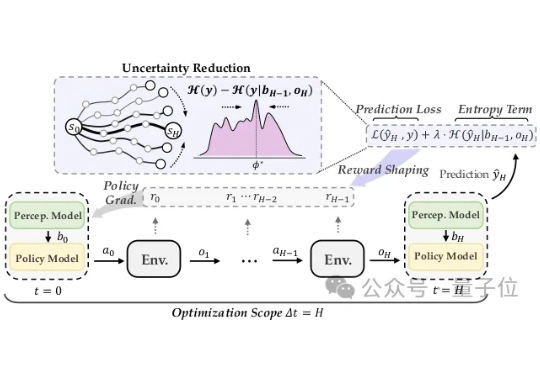
突破Agent长程推理效率瓶颈!MIT&新加坡国立联合推出强化学习新训练方法
突破Agent长程推理效率瓶颈!MIT&新加坡国立联合推出强化学习新训练方法
7886
AI技术研报
4o-mini华人领队也离职了,这次不怪小扎
4o-mini华人领队也离职了,这次不怪小扎
7528
AI资讯
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab
7799
AI技术研报
首个开源多模态Deep Research智能体,超越多个闭源方案
首个开源多模态Deep Research智能体,超越多个闭源方案
7849
AI资讯
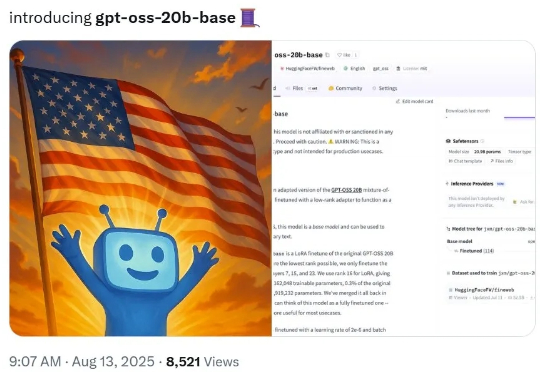
OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
7401
AI资讯
研究者警告:强化学习暗藏「策略悬崖」危机,AI对齐的根本性挑战浮现
研究者警告:强化学习暗藏「策略悬崖」危机,AI对齐的根本性挑战浮现
8652
AI技术研报
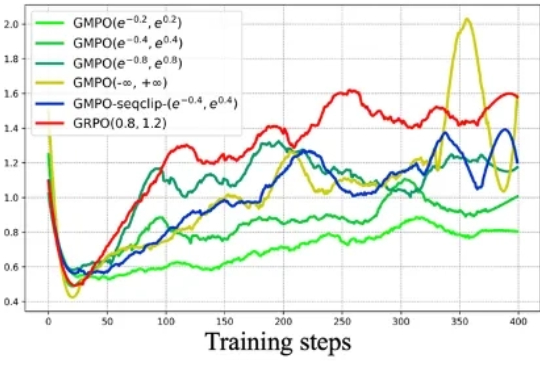
大型语言模型稳定强化学习的新路径:几何平均策略优化GMPO
大型语言模型稳定强化学习的新路径:几何平均策略优化GMPO
7170
AI技术研报
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
8068
AI技术研报
具身智能体主动迎战对抗攻击,清华团队提出主动防御框架
具身智能体主动迎战对抗攻击,清华团队提出主动防御框架
7962
AI技术研报
上一页
当前第12页,共37页
下一页
沪ICP备2023015588号