AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘
大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘
6279
AI技术研报
智源开源EditScore:为图像编辑解锁在线强化学习的无限可能
智源开源EditScore:为图像编辑解锁在线强化学习的无限可能
10155
AI技术研报
X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习
X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习
6944
AI技术研报
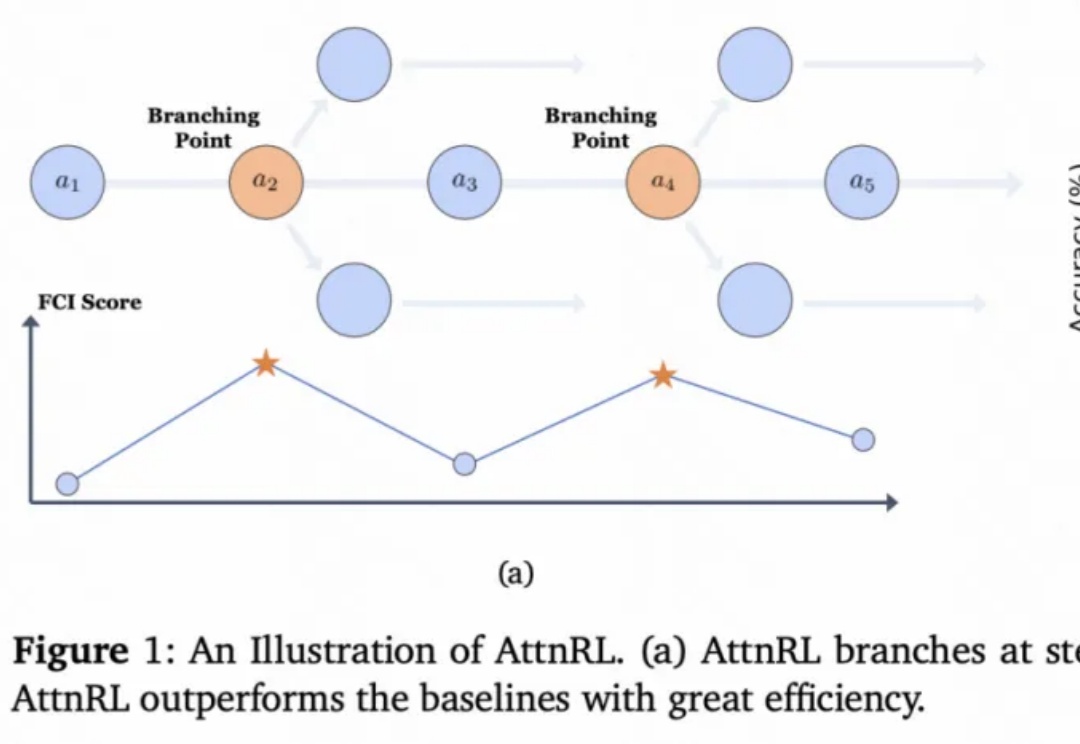
清华、快手提出AttnRL:让大模型用「注意力」探索
清华、快手提出AttnRL:让大模型用「注意力」探索
7803
AI技术研报
AGI前夜重磅:RL突破模型「认知上限」,真·学习发生了!
AGI前夜重磅:RL突破模型「认知上限」,真·学习发生了!
8093
AI技术研报
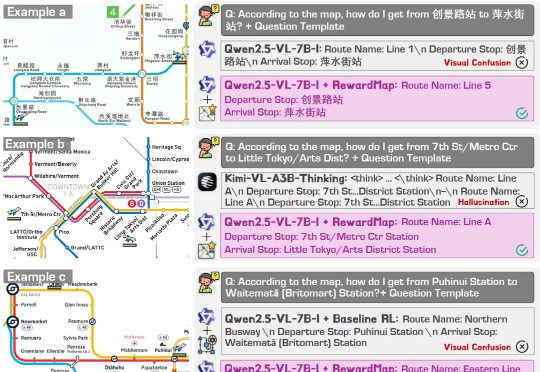
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
6519
AI技术研报
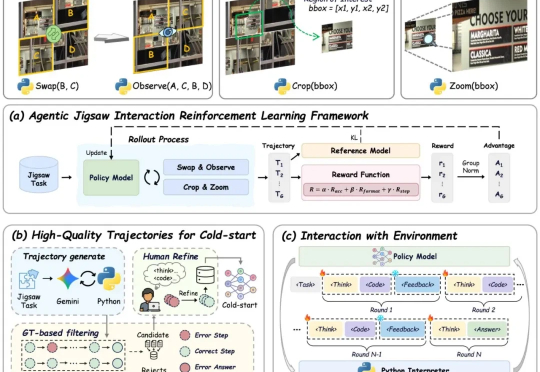
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
7152
AI技术研报
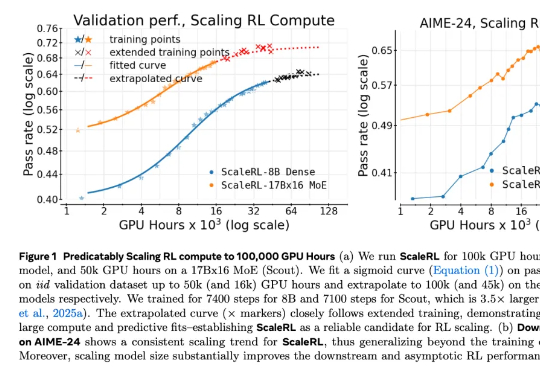
Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law
Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law
9412
AI技术研报
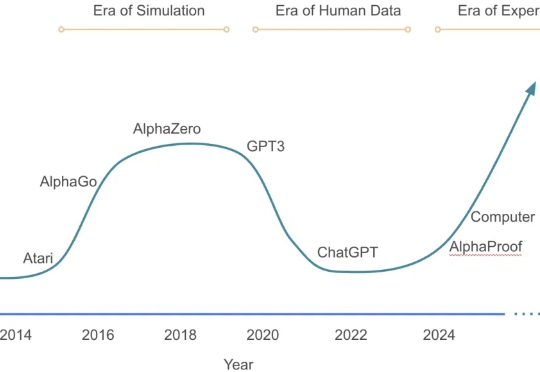
Karpathy泼冷水:AGI要等10年!根本没有「智能体元年」
Karpathy泼冷水:AGI要等10年!根本没有「智能体元年」
7991
AI资讯
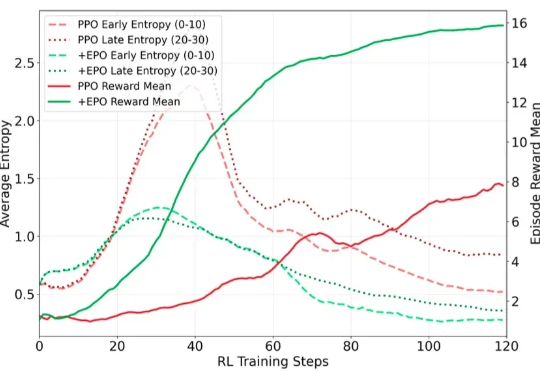
多轮Agent训练遇到级联失效?熵控制强化学习来破局
多轮Agent训练遇到级联失效?熵控制强化学习来破局
6819
AI技术研报
上一页
当前第7页,共37页
下一页
沪ICP备2023015588号