AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
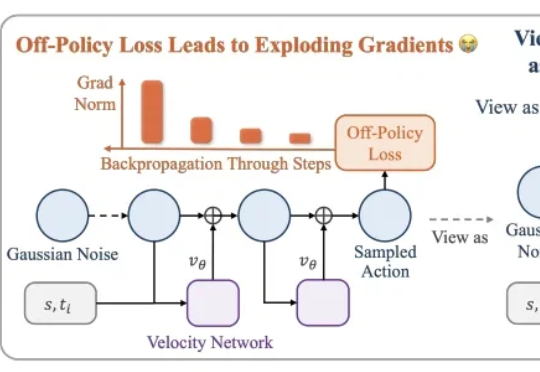
稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow
稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow
7851
AI技术研报
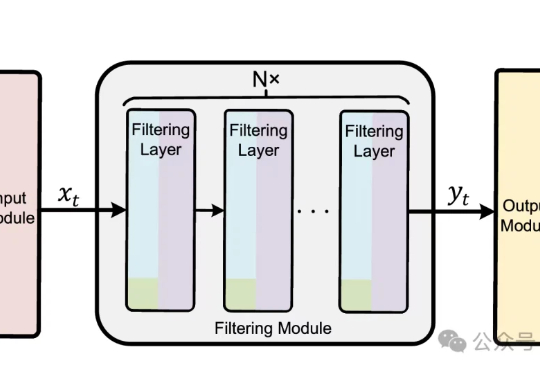
动作波动率降低70%!清华发布工业控制专用神经网络模型 | TIV'25
动作波动率降低70%!清华发布工业控制专用神经网络模型 | TIV'25
8233
AI技术研报
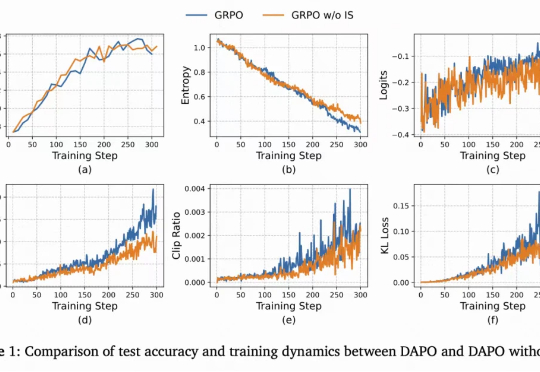
「重要性采样」并不「重要」?快手清华ASPO攻克重要性采样权重错配
「重要性采样」并不「重要」?快手清华ASPO攻克重要性采样权重错配
7666
AI技术研报
小米最新大模型成果!罗福莉现身了
小米最新大模型成果!罗福莉现身了
8473
AI技术研报
RL微调,关键在前10%奖励!基于评分准则,Scale AI等提出新方法
RL微调,关键在前10%奖励!基于评分准则,Scale AI等提出新方法
8091
AI技术研报
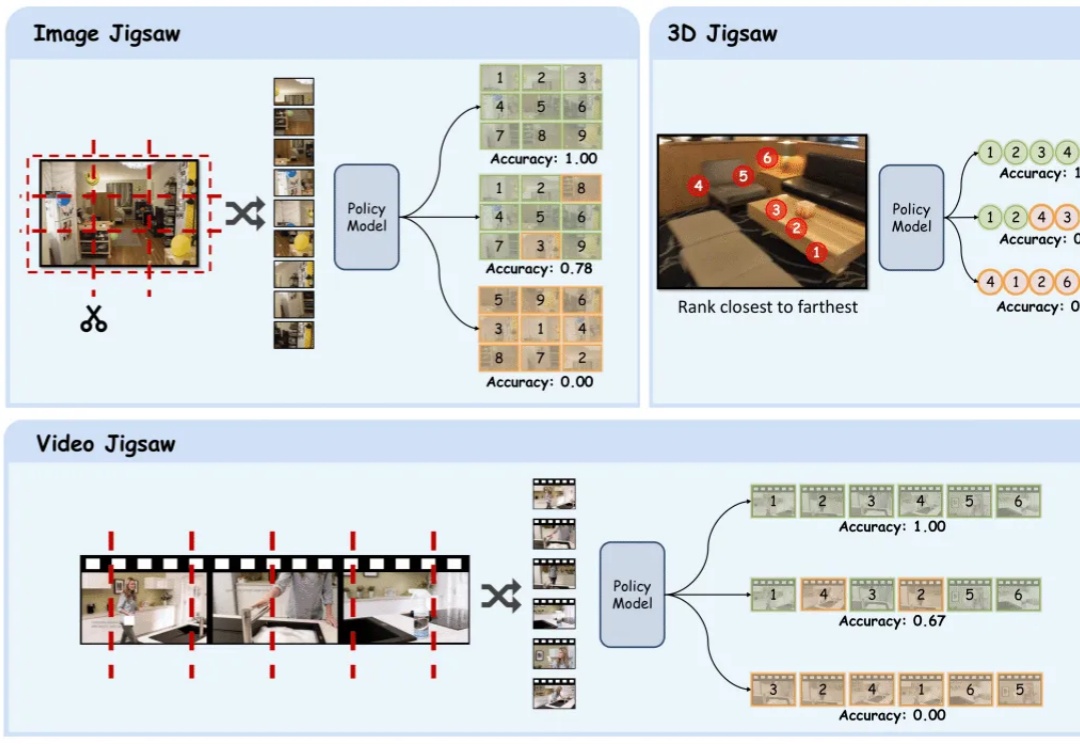
AI玩拼图游戏暴涨视觉理解力,告别文本中心训练,无需标注的多模态大模型后训练范式
AI玩拼图游戏暴涨视觉理解力,告别文本中心训练,无需标注的多模态大模型后训练范式
7964
AI技术研报
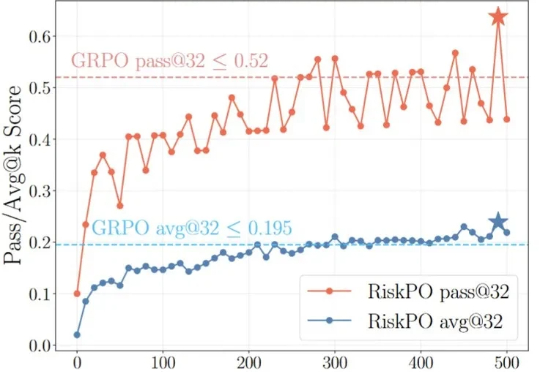
北大彭一杰教授课题组提出RiskPO,用风险度量优化重塑大模型后训练
北大彭一杰教授课题组提出RiskPO,用风险度量优化重塑大模型后训练
6718
AI技术研报
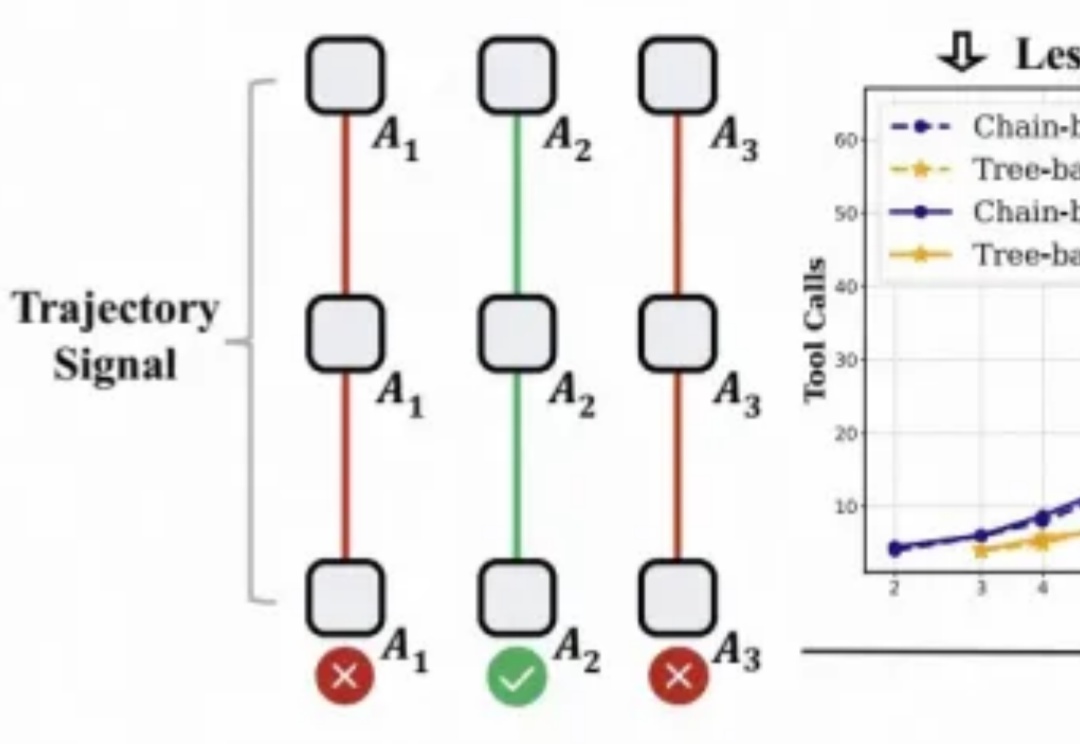
只需1/4预算,性能反超基线:阿里高德提出Tree-GRPO,高效破解智能体RL难题
只需1/4预算,性能反超基线:阿里高德提出Tree-GRPO,高效破解智能体RL难题
8304
AI技术研报
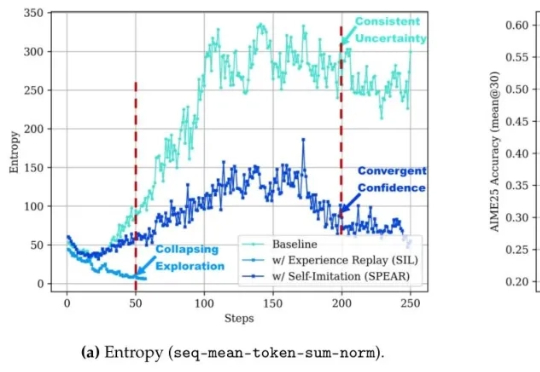
腾讯开源强化学习新算法!让智能体无需专家示范就“自学成才”,还即插即用零成本接入
腾讯开源强化学习新算法!让智能体无需专家示范就“自学成才”,还即插即用零成本接入
7784
AI技术研报
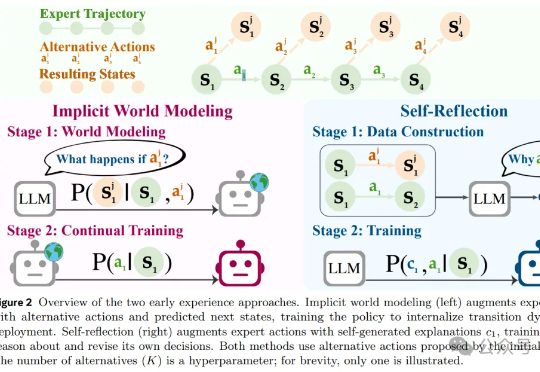
刚刚,Meta风雨飘摇中发了篇重量级论文,作者几乎全是华人
刚刚,Meta风雨飘摇中发了篇重量级论文,作者几乎全是华人
9411
AI技术研报
上一页
当前第8页,共37页
下一页
沪ICP备2023015588号