AI资讯新闻榜单内容搜索-LLM
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: LLM
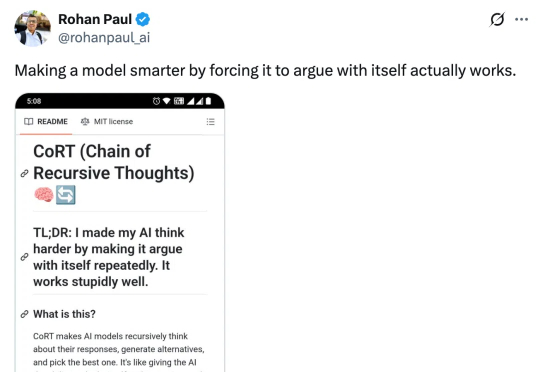
强迫模型自我争论,递归思考版CoT热度飙升!网友:这不就是大多数推理模型的套路吗?
强迫模型自我争论,递归思考版CoT热度飙升!网友:这不就是大多数推理模型的套路吗?
7219
AI技术研报
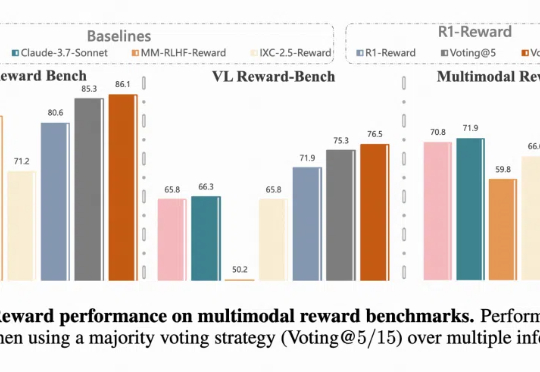
RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力
RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力
8992
AI技术研报
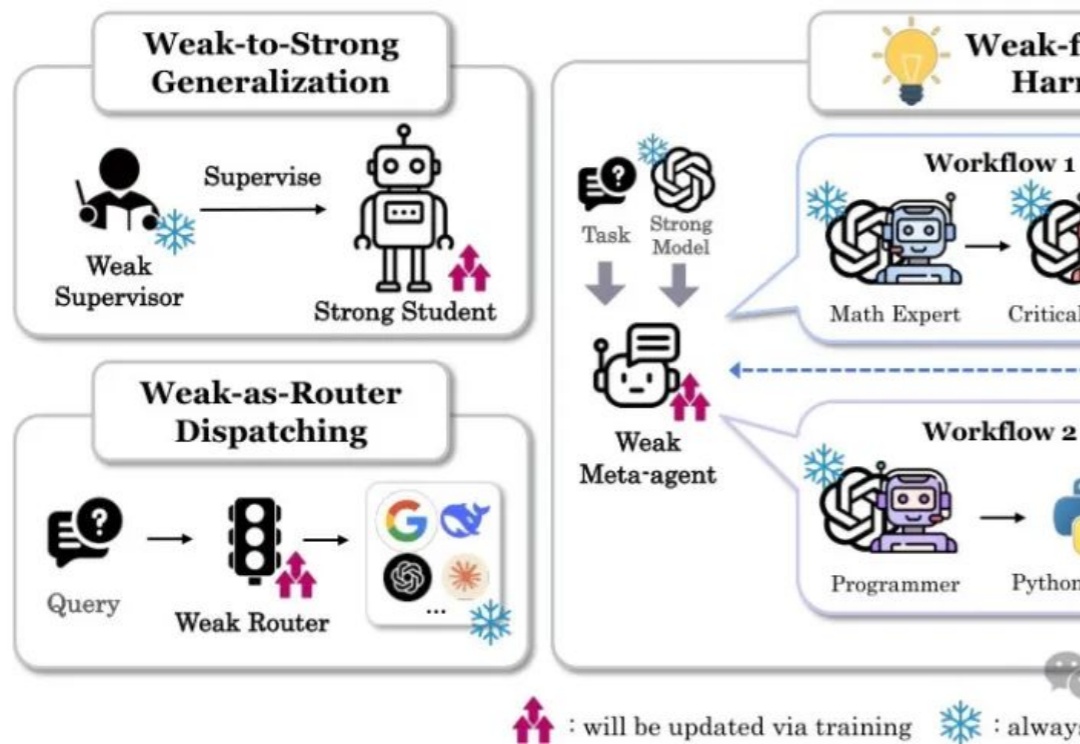
斯坦福的以弱驭强W4S,用Meta-Agent驾驭更强的LLM,准确率提升至95.4% | 最新
斯坦福的以弱驭强W4S,用Meta-Agent驾驭更强的LLM,准确率提升至95.4% | 最新
9210
AI技术研报
字节Seed首次开源代码模型,拿下同规模多个SOTA,提出用小模型管理数据范式
字节Seed首次开源代码模型,拿下同规模多个SOTA,提出用小模型管理数据范式
9609
AI资讯
万径归于「概率」,华人学者颠覆认知!英伟达大牛力荐RL微调新作
万径归于「概率」,华人学者颠覆认知!英伟达大牛力荐RL微调新作
10076
AI技术研报
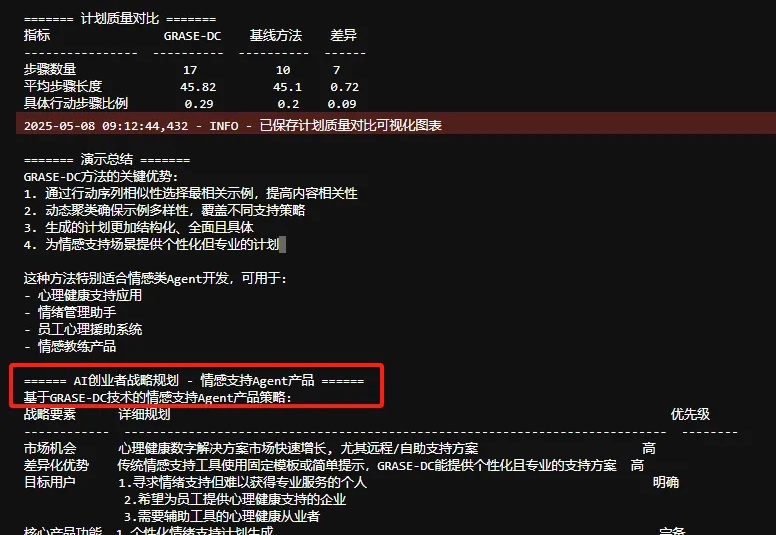
谷歌DeepMind&CMU:过去引导LLM规划的方法是错的? 用GRASE-DC改进。ICLR2025
谷歌DeepMind&CMU:过去引导LLM规划的方法是错的? 用GRASE-DC改进。ICLR2025
10764
AI技术研报
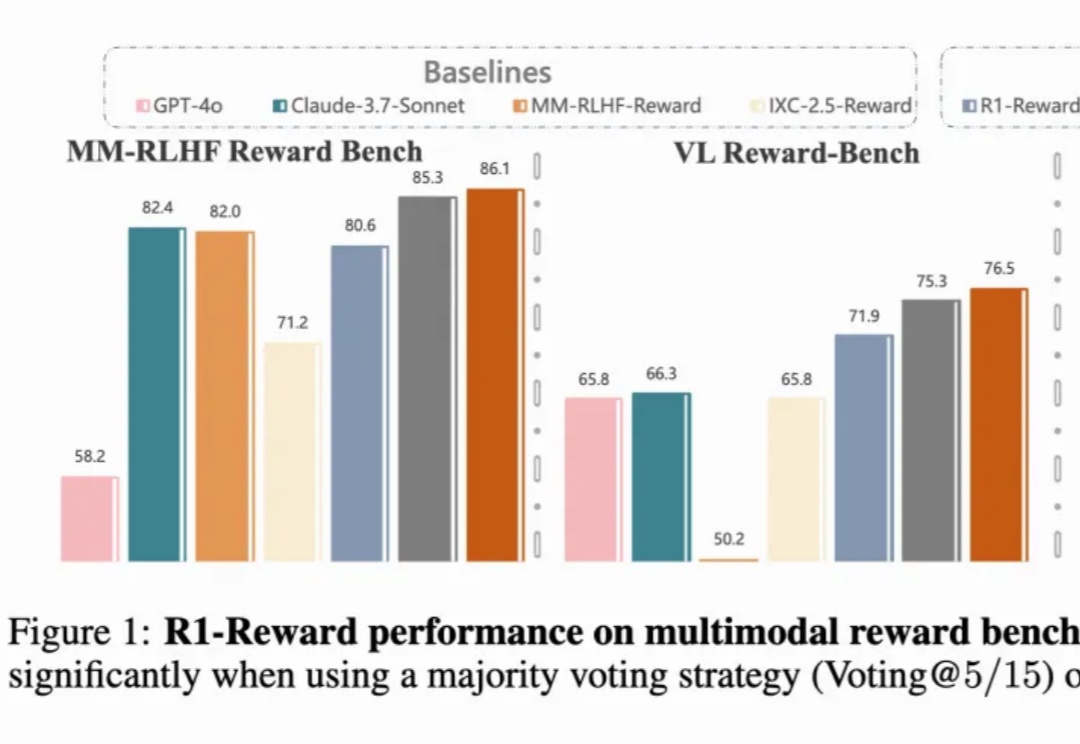
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力
9704
AI技术研报
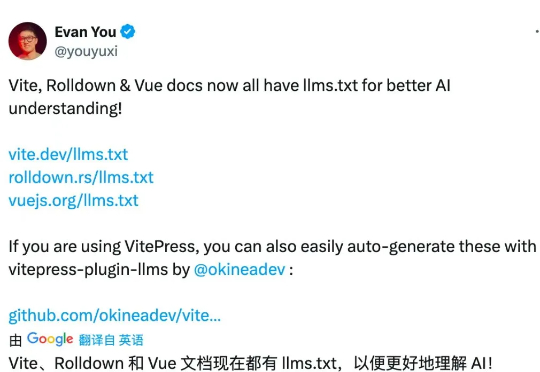
尤雨溪宣布:Vue 生态正式引入 AI!
尤雨溪宣布:Vue 生态正式引入 AI!
10445
AI资讯
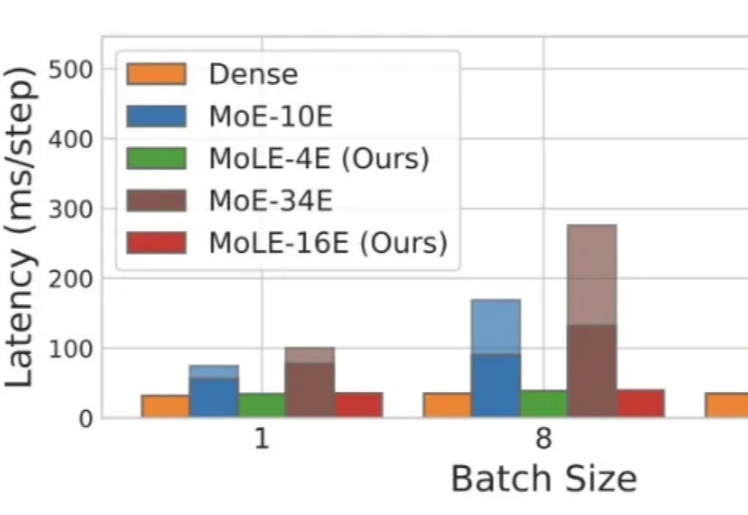
ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍
ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍
8003
AI技术研报
如何在LLM「排行榜幻象」中导航?2025AI界震撼大瓜,披露学术造假
如何在LLM「排行榜幻象」中导航?2025AI界震撼大瓜,披露学术造假
9029
AI技术研报
上一页
当前第45页,共143页
下一页
沪ICP备2023015588号