AI资讯新闻榜单内容搜索-强化学习
站点导航
首页
AI资讯
AI技术研报
AI监管政策
AI产品测评
AI商业项目
AI产品热榜
AI专利库
AI需求对接
APP 下载
iOS 下载
安卓下载
# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清空
确定
AITNT
未登录
退出
验证码登录
×
发送
登录即代表您已同意AITNT
用户协议
和
隐私政策
登录
搜索: 强化学习
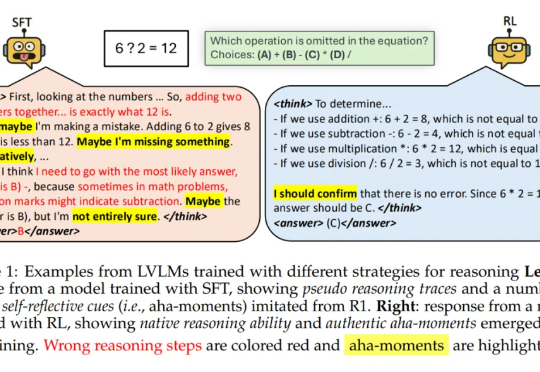
首个多模态专用慢思考框架!超GPT-o1近7个百分点,强化学习教会VLM「三思而后行」
首个多模态专用慢思考框架!超GPT-o1近7个百分点,强化学习教会VLM「三思而后行」
8349
AI技术研报
10行代码,AIME24/25提高15%!揭秘大模型强化学习熵机制
10行代码,AIME24/25提高15%!揭秘大模型强化学习熵机制
6137
AI技术研报
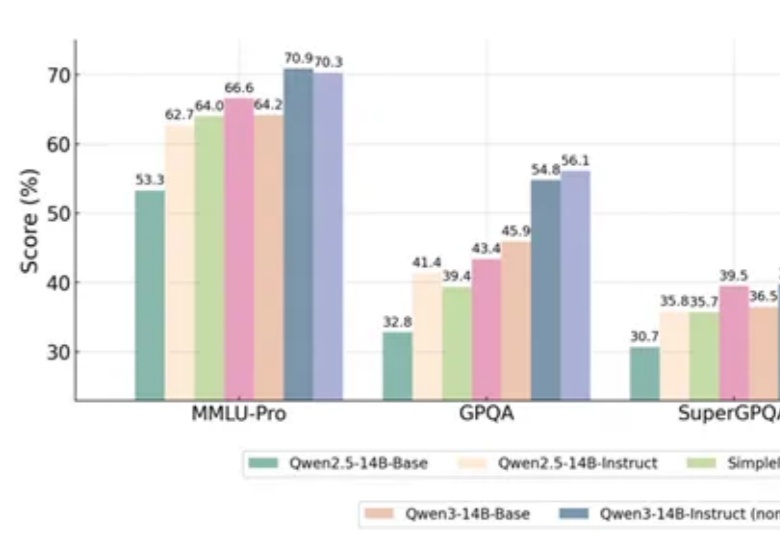
Qwen&清华团队颠覆常识:大模型强化学习仅用20%关键token,比用全部token训练还好
Qwen&清华团队颠覆常识:大模型强化学习仅用20%关键token,比用全部token训练还好
7501
AI技术研报
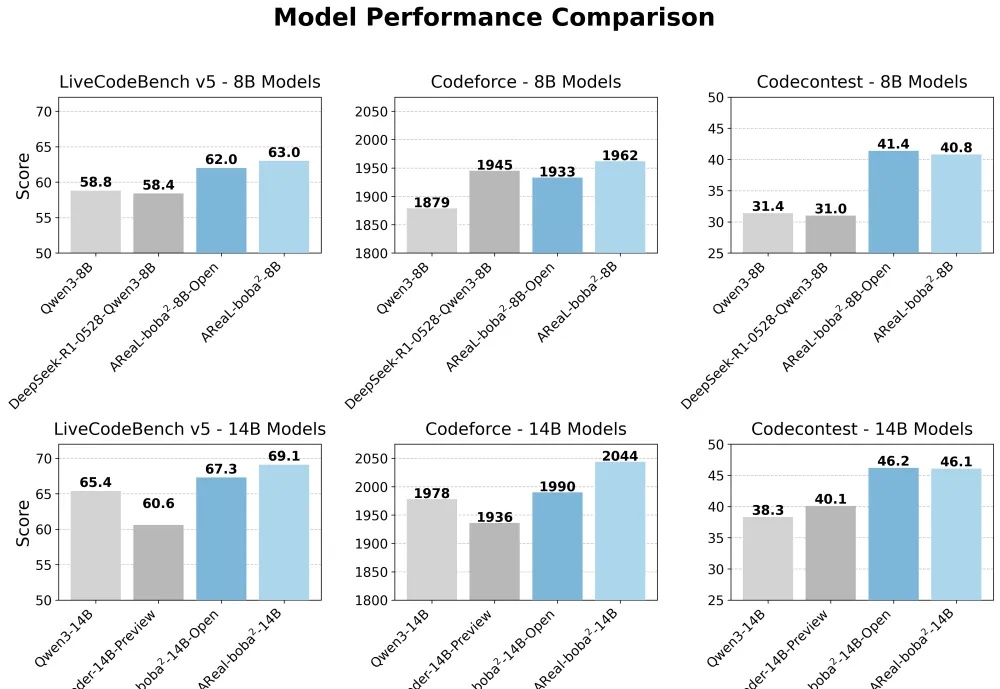
让GPU不再摸鱼!清华蚂蚁联合开源首个全异步RL,一夜击穿14B SOTA
让GPU不再摸鱼!清华蚂蚁联合开源首个全异步RL,一夜击穿14B SOTA
6777
AI技术研报
10步优化超越强化学习,仅需1条未标注数据!后训练强势破局
10步优化超越强化学习,仅需1条未标注数据!后训练强势破局
7663
AI技术研报
英伟达揭示RL Scaling魔力!训练步数翻倍=推理能力质变,小模型突破推理极限
英伟达揭示RL Scaling魔力!训练步数翻倍=推理能力质变,小模型突破推理极限
7785
AI技术研报
重磅开源!首个全异步强化学习训练系统来了,SOTA推理大模型RL训练提速2.77倍
重磅开源!首个全异步强化学习训练系统来了,SOTA推理大模型RL训练提速2.77倍
7694
AI技术研报
超越GPT-4o!华人团队新框架让Qwen跨领域推理提升10%,刷新12项基准测试
超越GPT-4o!华人团队新框架让Qwen跨领域推理提升10%,刷新12项基准测试
6923
AI技术研报
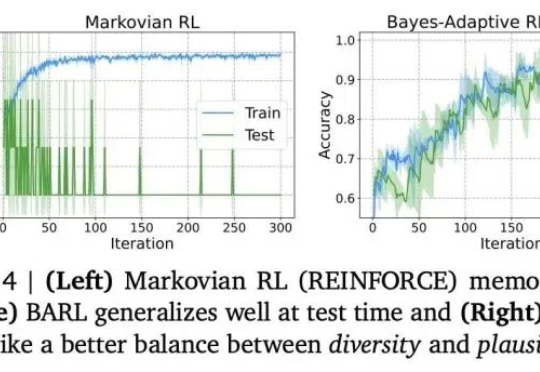
首次解释LLM如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升
首次解释LLM如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升
7994
AI技术研报
SFT在帮倒忙?新研究:直接进行强化学习,模型多模态推理上限更高
SFT在帮倒忙?新研究:直接进行强化学习,模型多模态推理上限更高
8714
AI技术研报
上一页
当前第19页,共37页
下一页
沪ICP备2023015588号